 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrinity: Unifying Class-Agnostic Terrain and Semantic Segmentation for Unstructured Outdoor Environments by Leveraging Synthetic Data
May 26, 2026Terrain understanding is fundamental for mobile robots operating in unstructured outdoor environments. Existing vision-based traversability estimation methods rely on robot-specific annotations or semantic class mappings, limiting transferability across platforms and requiring costly re-annotation when robot capabilities change, while standard semantic segmentation methods only focus on specific predefined classes, which do not capture the variety of terrains. In this work, we propose a transformer-based architecture that jointly performs class-specific semantic segmentation and class-agnostic terrain segmentation within a unified network, called Trinity. Terrain regions are segmented based solely on visual appearance, without predefined semantic labels or robot-dependent traversability scores. This formulation enables the learning of robot-agnostic visual terrain priors that can be combined with robot-specific experience for downstream tasks such as traversability estimation, visual odometry, and mission planning. To enable large-scale training with diverse terrain appearances, we extend the OAISYS simulator and introduce RUGDSynth, a synthetic dataset inspired by RUGD with class-agnostic terrain samples. Furthermore, we present the EXTerra Dataset, providing real-world images annotated with both class-specific and class-agnostic terrain labels. Experiments demonstrate the feasibility of the proposed task and the effectiveness of our joint segmentation approach in complex outdoor environments. Code and datasets will be released with this publication (after review).
Out of the Room: Generalizing Event-Based Dynamic Motion Segmentation for Complex Scenes
Mar 07, 2024



Rapid and reliable identification of dynamic scene parts, also known as motion segmentation, is a key challenge for mobile sensors. Contemporary RGB camera-based methods rely on modeling camera and scene properties however, are often under-constrained and fall short in unknown categories. Event cameras have the potential to overcome these limitations, but corresponding methods have only been demonstrated in smaller-scale indoor environments with simplified dynamic objects. This work presents an event-based method for class-agnostic motion segmentation that can successfully be deployed across complex large-scale outdoor environments too. To this end, we introduce a novel divide-and-conquer pipeline that combines: (a) ego-motion compensated events, computed via a scene understanding module that predicts monocular depth and camera pose as auxiliary tasks, and (b) optical flow from a dedicated optical flow module. These intermediate representations are then fed into a segmentation module that predicts motion segmentation masks. A novel transformer-based temporal attention module in the segmentation module builds correlations across adjacent 'frames' to get temporally consistent segmentation masks. Our method sets the new state-of-the-art on the classic EV-IMO benchmark (indoors), where we achieve improvements of 2.19 moving object IoU (2.22 mIoU) and 4.52 point IoU respectively, as well as on a newly-generated motion segmentation and tracking benchmark (outdoors) based on the DSEC event dataset, termed DSEC-MOTS, where we show improvement of 12.91 moving object IoU.
U-BEV: Height-aware Bird's-Eye-View Segmentation and Neural Map-based Relocalization
Oct 20, 2023



Efficient relocalization is essential for intelligent vehicles when GPS reception is insufficient or sensor-based localization fails. Recent advances in Bird's-Eye-View (BEV) segmentation allow for accurate estimation of local scene appearance and in turn, can benefit the relocalization of the vehicle. However, one downside of BEV methods is the heavy computation required to leverage the geometric constraints. This paper presents U-BEV, a U-Net inspired architecture that extends the current state-of-the-art by allowing the BEV to reason about the scene on multiple height layers before flattening the BEV features. We show that this extension boosts the performance of the U-BEV by up to 4.11 IoU. Additionally, we combine the encoded neural BEV with a differentiable template matcher to perform relocalization on neural SD-map data. The model is fully end-to-end trainable and outperforms transformer-based BEV methods of similar computational complexity by 1.7 to 2.8 mIoU and BEV-based relocalization by over 26% Recall Accuracy on the nuScenes dataset.
SCIM: Simultaneous Clustering, Inference, and Mapping for Open-World Semantic Scene Understanding
Jun 21, 2022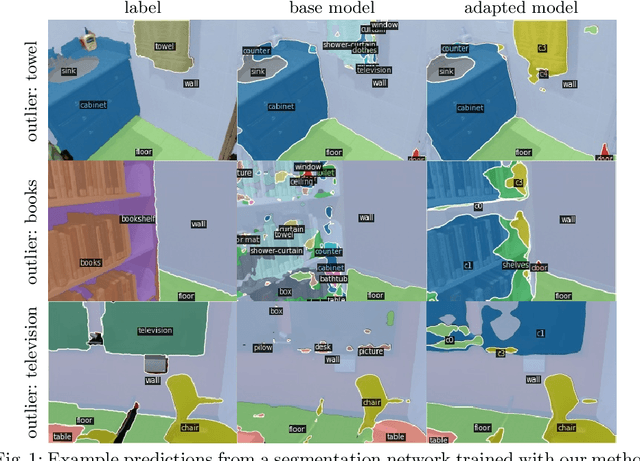
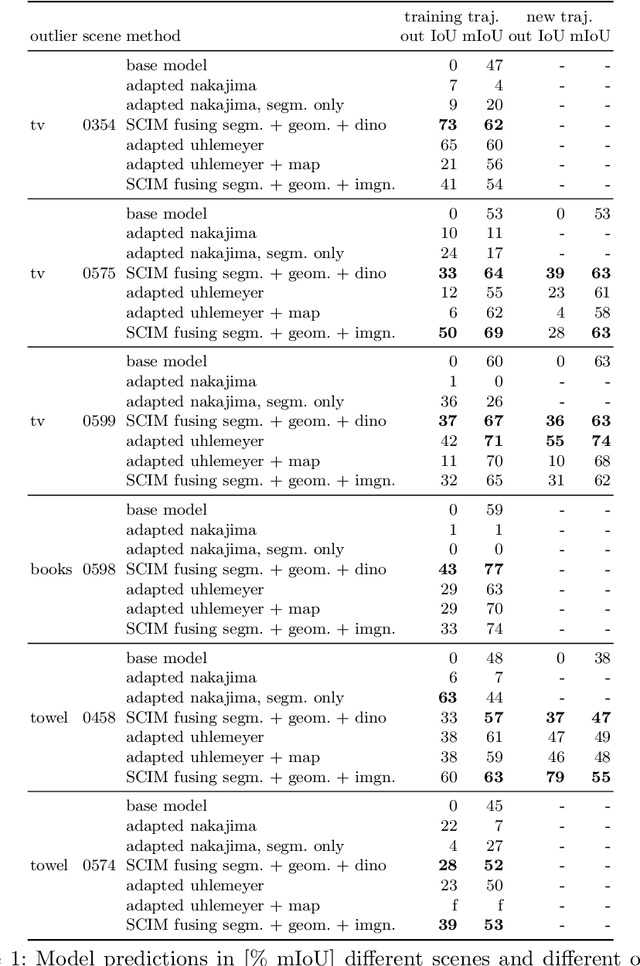
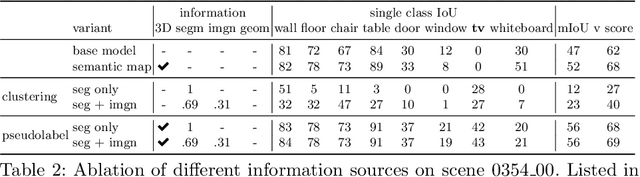
In order to operate in human environments, a robot's semantic perception has to overcome open-world challenges such as novel objects and domain gaps. Autonomous deployment to such environments therefore requires robots to update their knowledge and learn without supervision. We investigate how a robot can autonomously discover novel semantic classes and improve accuracy on known classes when exploring an unknown environment. To this end, we develop a general framework for mapping and clustering that we then use to generate a self-supervised learning signal to update a semantic segmentation model. In particular, we show how clustering parameters can be optimized during deployment and that fusion of multiple observation modalities improves novel object discovery compared to prior work.
SL Sensor: An Open-Source, ROS-Based, Real-Time Structured Light Sensor for High Accuracy Construction Robotic Applications
Jan 22, 2022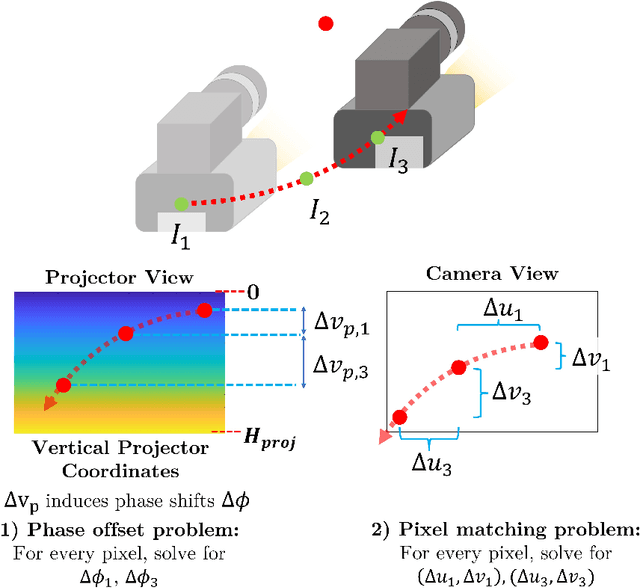


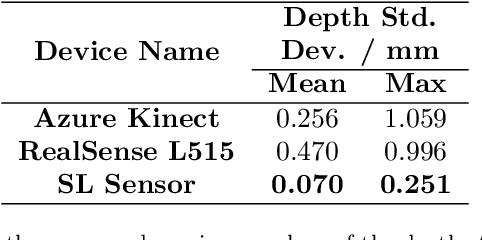
High accuracy 3D surface information is required for many construction robotics tasks such as automated cement polishing or robotic plaster spraying. However, consumer-grade depth cameras currently found in the market are not accurate enough for these tasks where millimeter (mm)-level accuracy is required. We present SL Sensor, a structured light sensing solution capable of producing high fidelity point clouds at 5Hz by leveraging on phase shifting profilometry (PSP) codification techniques. We compared SL Sensor to two commercial depth cameras - the Azure Kinect and RealSense L515. Experiments showed that the SL Sensor surpasses the two devices in both precision and accuracy. Furthermore, to demonstrate SL Sensor's ability to be a structured light sensing research platform for robotic applications, we developed a motion compensation strategy that allows the SL Sensor to operate during linear motion when traditional PSP methods only work when the sensor is static. Field experiments show that the SL Sensor is able produce highly detailed reconstructions of spray plastered surfaces. The software and a sample hardware build of the SL Sensor are made open-source with the objective to make structured light sensing more accessible to the construction robotics community. All documentation and code is available at https://github.com/ethz-asl/sl_sensor/ .
Self-Improving Semantic Perception on a Construction Robot
May 04, 2021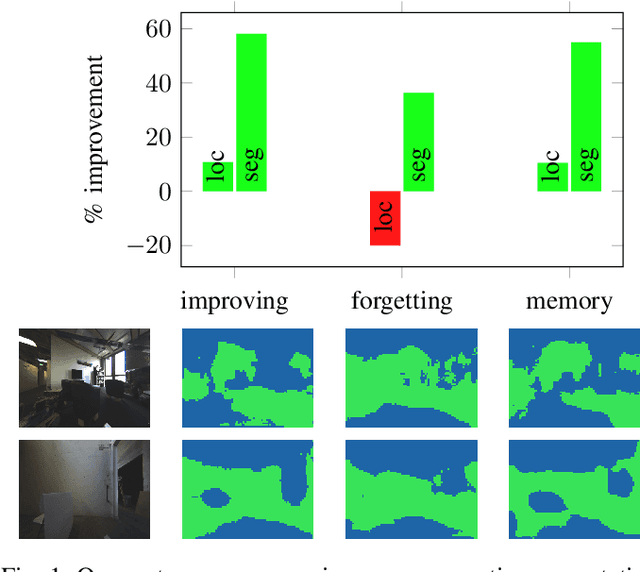
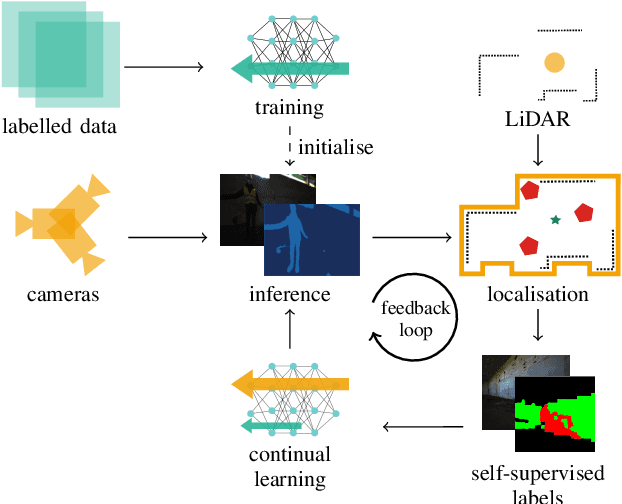
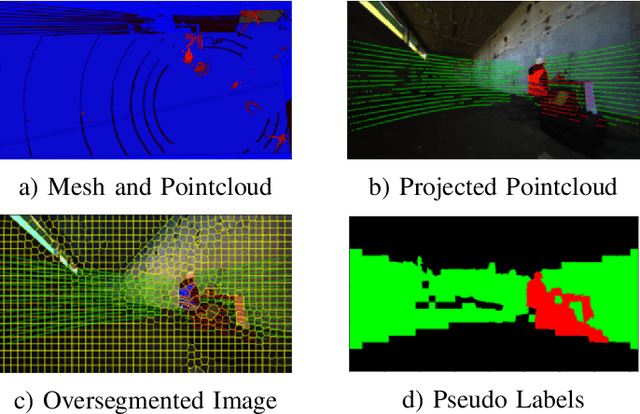

We propose a novel robotic system that can improve its semantic perception during deployment. Contrary to the established approach of learning semantics from large datasets and deploying fixed models, we propose a framework in which semantic models are continuously updated on the robot to adapt to the deployment environments. Our system therefore tightly couples multi-sensor perception and localisation to continuously learn from self-supervised pseudo labels. We study this system in the context of a construction robot registering LiDAR scans of cluttered environments against building models. Our experiments show how the robot's semantic perception improves during deployment and how this translates into improved 3D localisation by filtering the clutter out of the LiDAR scan, even across drastically different environments. We further study the risk of catastrophic forgetting that such a continuous learning setting poses. We find memory replay an effective measure to reduce forgetting and show how the robotic system can improve even when switching between different environments. On average, our system improves by 60% in segmentation and 10% in localisation compared to deployment of a fixed model, and it keeps this improvement up while adapting to further environments.
Multiple Hypothesis Semantic Mapping for Robust Data Association
Dec 08, 2020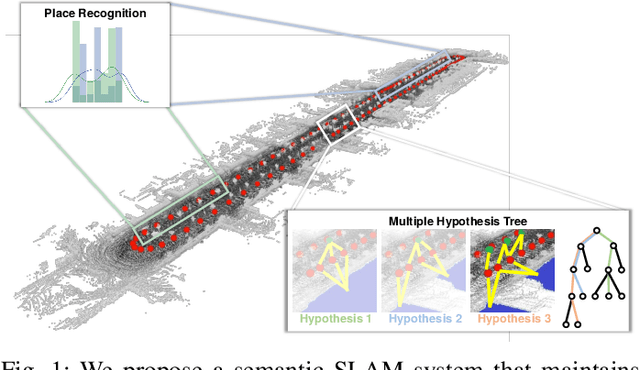
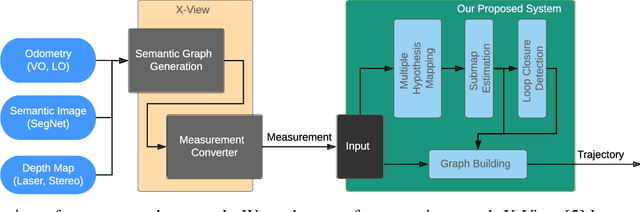
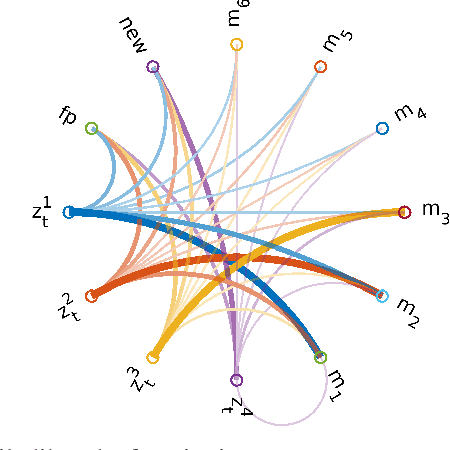
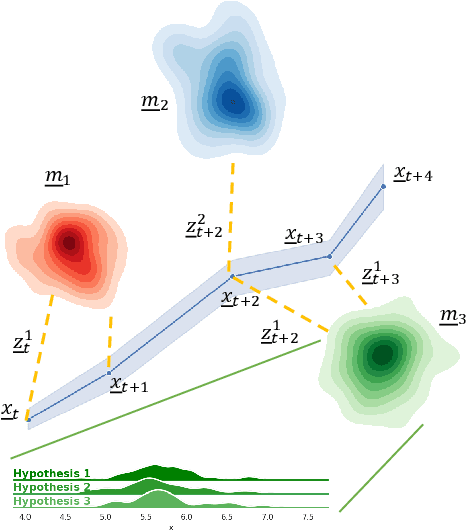
In this paper, we present a semantic mapping approach with multiple hypothesis tracking for data association. As semantic information has the potential to overcome ambiguity in measurements and place recognition, it forms an eminent modality for autonomous systems. This is particularly evident in urban scenarios with several similar looking surroundings. Nevertheless, it requires the handling of a non-Gaussian and discrete random variable coming from object detectors. Previous methods facilitate semantic information for global localization and data association to reduce the instance ambiguity between the landmarks. However, many of these approaches do not deal with the creation of complete globally consistent representations of the environment and typically do not scale well. We utilize multiple hypothesis trees to derive a probabilistic data association for semantic measurements by means of position, instance and class to create a semantic representation. We propose an optimized mapping method and make use of a pose graph to derive a novel semantic SLAM solution. Furthermore, we show that semantic covisibility graphs allow for a precise place recognition in urban environments. We verify our approach using real-world outdoor dataset and demonstrate an average drift reduction of 33 % w.r.t. the raw odometry source. Moreover, our approach produces 55 % less hypotheses on average than a regular multiple hypotheses approach.
Precise Robot Localization in Architectural 3D Plans
Jun 09, 2020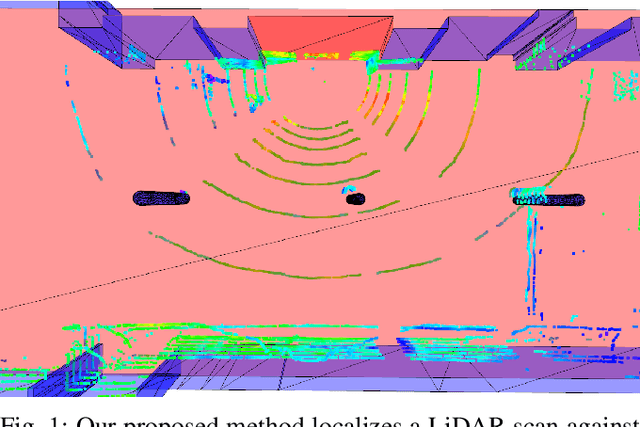

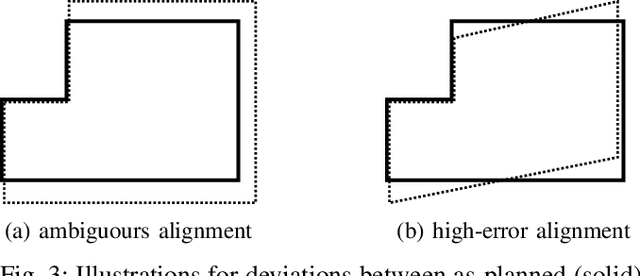

This paper presents a localization system for mobile robots enabling precise localization in inaccurate building models. The approach leverages local referencing to counteract inherent deviations between as-planned and as-built data for locally accurate registration. We further fuse a novel image-based robust outlier detector with LiDAR data to reject a wide range of outlier measurements from clutter, dynamic objects, and sensor failures. We evaluate the proposed approach on a mobile robot in a challenging real world building construction site. It consistently outperforms the traditional ICP-based alingment, reducing localization error by at least 30%.
Fast and Accurate Mapping for Autonomous Racing
Mar 12, 2020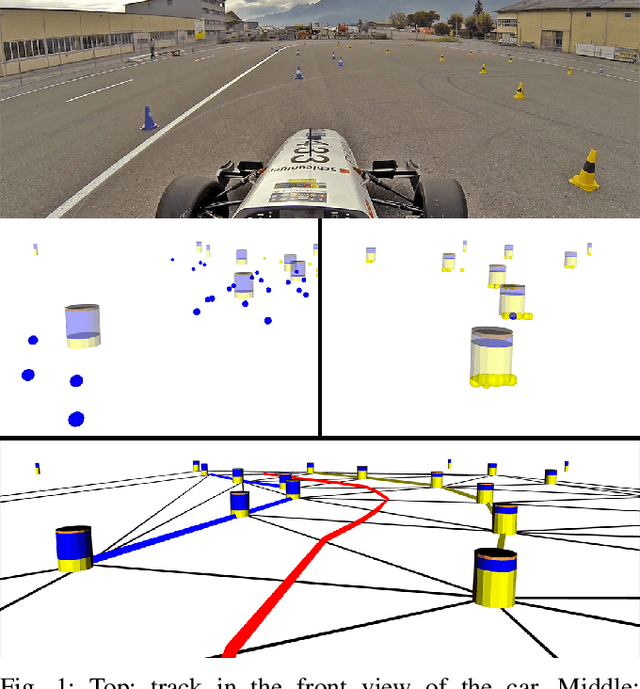
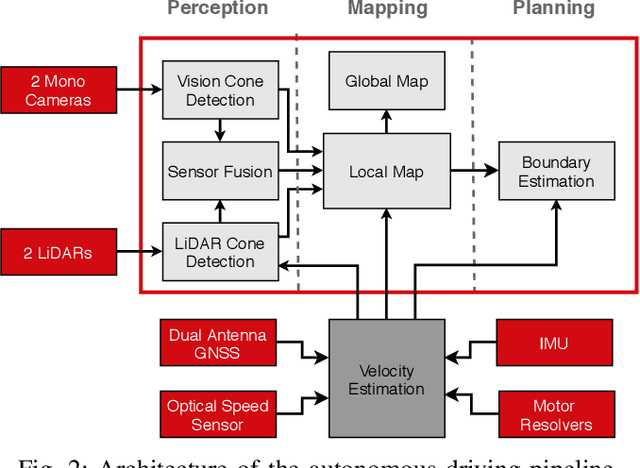
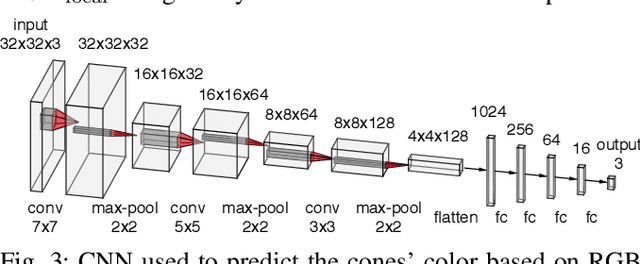

This paper presents the perception, mapping, and planning pipeline implemented on an autonomous race car. It was developed by the 2019 AMZ driverless team for the Formula Student Germany (FSG) 2019 driverless competition, where it won 1st place overall. The presented solution combines early fusion of camera and LiDAR data, a layered mapping approach, and a planning approach that uses Bayesian filtering to achieve high-speed driving on unknown race tracks while creating accurate maps. We benchmark the method against our team's previous solution, which won FSG 2018, and show improved accuracy when driving at the same speeds. Furthermore, the new pipeline makes it possible to reliably raise the maximum driving speed in unknown environments from 3~m/s to 12~m/s while still mapping with an acceptable RMSE of 0.29~m.
A Fully-Integrated Sensing and Control System for High-Accuracy Mobile Robotic Building Construction
Dec 04, 2019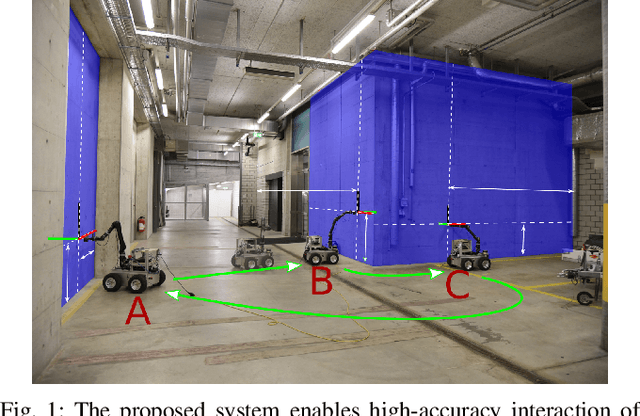
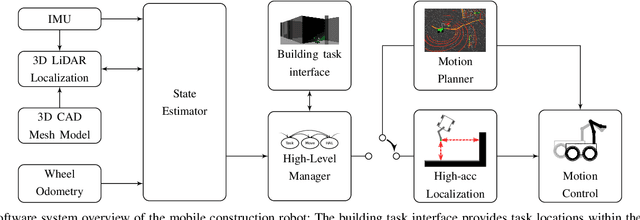

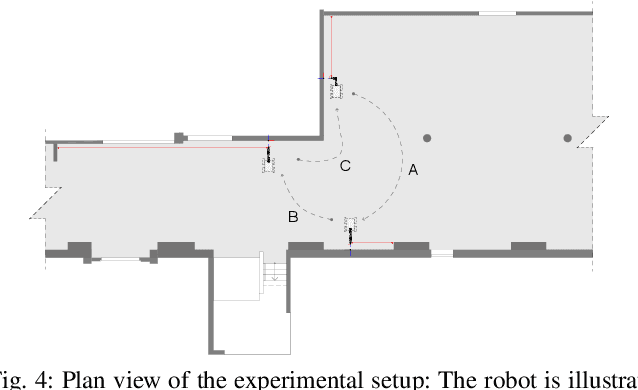
We present a fully-integrated sensing and control system which enables mobile manipulator robots to execute building tasks with millimeter-scale accuracy on building construction sites. The approach leverages multi-modal sensing capabilities for state estimation, tight integration with digital building models, and integrated trajectory planning and whole-body motion control. A novel method for high-accuracy localization updates relative to the known building structure is proposed. The approach is implemented on a real platform and tested under realistic construction conditions. We show that the system can achieve sub-cm end-effector positioning accuracy during fully autonomous operation using solely on-board sensing.