 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Fine-Tuning of Pretrained Controllers for Autonomous Driving via Real-Time Recurrent RL
Feb 03, 2026Deploying pretrained policies in real-world applications presents substantial challenges that fundamentally limit the practical applicability of learning-based control systems. When autonomous systems encounter environmental changes in system dynamics, sensor drift, or task objectives, fixed policies rapidly degrade in performance. We show that employing Real-Time Recurrent Reinforcement Learning (RTRRL), a biologically plausible algorithm for online adaptation, can effectively fine-tune a pretrained policy to improve autonomous agents' performance on driving tasks. We further show that RTRRL synergizes with a recent biologically inspired recurrent network model, the Liquid-Resistance Liquid-Capacitance RNN. We demonstrate the effectiveness of this closed-loop approach in a simulated CarRacing environment and in a real-world line-following task with a RoboRacer car equipped with an event camera.
PoSafeNet: Safe Learning with Poset-Structured Neural Nets
Jan 29, 2026Safe learning is essential for deploying learningbased controllers in safety-critical robotic systems, yet existing approaches often enforce multiple safety constraints uniformly or via fixed priority orders, leading to infeasibility and brittle behavior. In practice, safety requirements are heterogeneous and admit only partial priority relations, where some constraints are comparable while others are inherently incomparable. We formalize this setting as poset-structured safety, modeling safety constraints as a partially ordered set and treating safety composition as a structural property of the policy class. Building on this formulation, we propose PoSafeNet, a differentiable neural safety layer that enforces safety via sequential closed-form projection under poset-consistent constraint orderings, enabling adaptive selection or mixing of valid safety executions while preserving priority semantics by construction. Experiments on multi-obstacle navigation, constrained robot manipulation, and vision-based autonomous driving demonstrate improved feasibility, robustness, and scalability over unstructured and differentiable quadratic program-based safety layers.
See Less, Drive Better: Generalizable End-to-End Autonomous Driving via Foundation Models Stochastic Patch Selection
Jan 15, 2026Recent advances in end-to-end autonomous driving show that policies trained on patch-aligned features extracted from foundation models generalize better to Out-of-Distribution (OOD). We hypothesize that due to the self-attention mechanism, each patch feature implicitly embeds/contains information from all other patches, represented in a different way and intensity, making these descriptors highly redundant. We quantify redundancy in such (BLIP2) features via PCA and cross-patch similarity: $90$% of variance is captured by $17/64$ principal components, and strong inter-token correlations are pervasive. Training on such overlapping information leads the policy to overfit spurious correlations, hurting OOD robustness. We present Stochastic-Patch-Selection (SPS), a simple yet effective approach for learning policies that are more robust, generalizable, and efficient. For every frame, SPS randomly masks a fraction of patch descriptors, not feeding them to the policy model, while preserving the spatial layout of the remaining patches. Thus, the policy is provided with different stochastic but complete views of the (same) scene: every random subset of patches acts like a different, yet still sensible, coherent projection of the world. The policy thus bases its decisions on features that are invariant to which specific tokens survive. Extensive experiments confirm that across all OOD scenarios, our method outperforms the state of the art (SOTA), achieving a $6.2$% average improvement and up to $20.4$% in closed-loop simulations, while being $2.4\times$ faster. We conduct ablations over masking rates and patch-feature reorganization, training and evaluating 9 systems, with 8 of them surpassing prior SOTA. Finally, we show that the same learned policy transfers to a physical, real-world car without any tuning.
A Unified Stochastic Mechanism Underlying Collective Behavior in Ants, Physical Systems, and Robotic Swarms
Nov 08, 2025Biological swarms, such as ant colonies, achieve collective goals through decentralized and stochastic individual behaviors. Similarly, physical systems composed of gases, liquids, and solids exhibit random particle motion governed by entropy maximization, yet do not achieve collective objectives. Despite this analogy, no unified framework exists to explain the stochastic behavior in both biological and physical systems. Here, we present empirical evidence from \textit{Formica polyctena} ants that reveals a shared statistical mechanism underlying both systems: maximization under different energy function constraints. We further demonstrate that robotic swarms governed by this principle can exhibit scalable, decentralized cooperation, mimicking physical phase-like behaviors with minimal individual computation. These findings established a unified stochastic model linking biological, physical, and robotic swarms, offering a scalable principle for designing robust and intelligent swarm robotics.
SAFe-Copilot: Unified Shared Autonomy Framework
Nov 06, 2025Autonomous driving systems remain brittle in rare, ambiguous, and out-of-distribution scenarios, where human driver succeed through contextual reasoning. Shared autonomy has emerged as a promising approach to mitigate such failures by incorporating human input when autonomy is uncertain. However, most existing methods restrict arbitration to low-level trajectories, which represent only geometric paths and therefore fail to preserve the underlying driving intent. We propose a unified shared autonomy framework that integrates human input and autonomous planners at a higher level of abstraction. Our method leverages Vision Language Models (VLMs) to infer driver intent from multi-modal cues -- such as driver actions and environmental context -- and to synthesize coherent strategies that mediate between human and autonomous control. We first study the framework in a mock-human setting, where it achieves perfect recall alongside high accuracy and precision. A human-subject survey further shows strong alignment, with participants agreeing with arbitration outcomes in 92% of cases. Finally, evaluation on the Bench2Drive benchmark demonstrates a substantial reduction in collision rate and improvement in overall performance compared to pure autonomy. Arbitration at the level of semantic, language-based representations emerges as a design principle for shared autonomy, enabling systems to exercise common-sense reasoning and maintain continuity with human intent.
ReGen: Generative Robot Simulation via Inverse Design
Nov 06, 2025Simulation plays a key role in scaling robot learning and validating policies, but constructing simulations remains a labor-intensive process. This paper introduces ReGen, a generative simulation framework that automates simulation design via inverse design. Given a robot's behavior -- such as a motion trajectory or an objective function -- and its textual description, ReGen infers plausible scenarios and environments that could have caused the behavior. ReGen leverages large language models to synthesize scenarios by expanding a directed graph that encodes cause-and-effect relationships, relevant entities, and their properties. This structured graph is then translated into a symbolic program, which configures and executes a robot simulation environment. Our framework supports (i) augmenting simulations based on ego-agent behaviors, (ii) controllable, counterfactual scenario generation, (iii) reasoning about agent cognition and mental states, and (iv) reasoning with distinct sensing modalities, such as braking due to faulty GPS signals. We demonstrate ReGen in autonomous driving and robot manipulation tasks, generating more diverse, complex simulated environments compared to existing simulations with high success rates, and enabling controllable generation for corner cases. This approach enhances the validation of robot policies and supports data or simulation augmentation, advancing scalable robot learning for improved generalization and robustness. We provide code and example videos at: https://regen-sim.github.io/
Compress to Impress: Efficient LLM Adaptation Using a Single Gradient Step on 100 Samples
Oct 23, 2025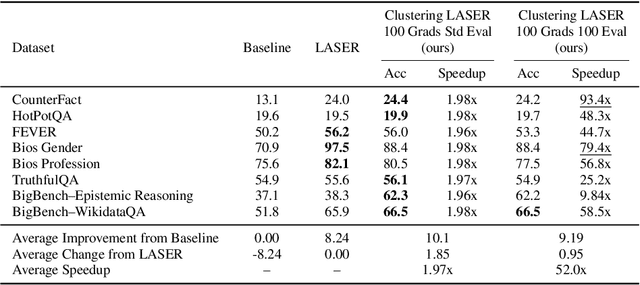
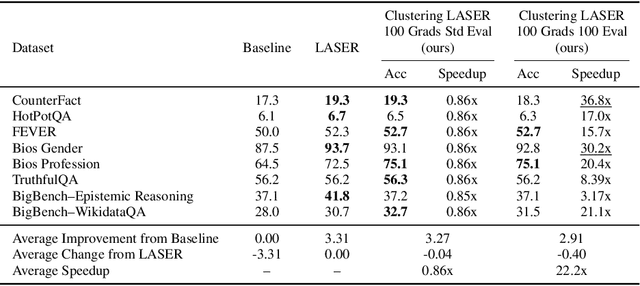
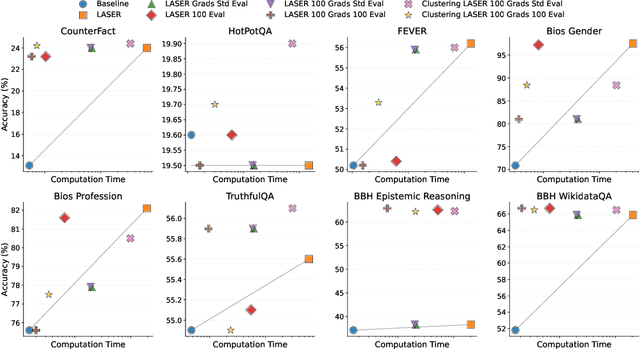
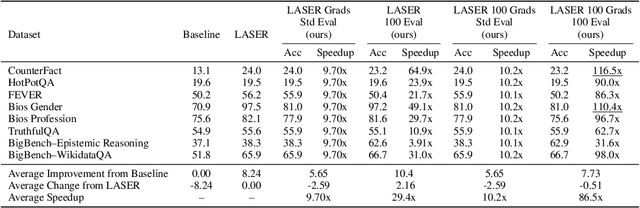
Recently, Sharma et al. suggested a method called Layer-SElective-Rank reduction (LASER) which demonstrated that pruning high-order components of carefully chosen LLM's weight matrices can boost downstream accuracy -- without any gradient-based fine-tuning. Yet LASER's exhaustive, per-matrix search (each requiring full-dataset forward passes) makes it impractical for rapid deployment. We demonstrate that this overhead can be removed and find that: (i) Only a small, carefully chosen subset of matrices needs to be inspected -- eliminating the layer-by-layer sweep, (ii) The gradient of each matrix's singular values pinpoints which matrices merit reduction, (iii) Increasing the factorization search space by allowing matrices rows to cluster around multiple subspaces and then decomposing each cluster separately further reduces overfitting on the original training data and further lifts accuracy by up to 24.6 percentage points, and finally, (iv) we discover that evaluating on just 100 samples rather than the full training data -- both for computing the indicative gradients and for measuring the final accuracy -- suffices to further reduce the search time; we explain that as adaptation to downstream tasks is dominated by prompting style, not dataset size. As a result, we show that combining these findings yields a fast and robust adaptation algorithm for downstream tasks. Overall, with a single gradient step on 100 examples and a quick scan of the top candidate layers and factorization techniques, we can adapt LLMs to new datasets -- entirely without fine-tuning.
Safe Motion Planning and Control Using Predictive and Adaptive Barrier Methods for Autonomous Surface Vessels
Oct 01, 2025Safe motion planning is essential for autonomous vessel operations, especially in challenging spaces such as narrow inland waterways. However, conventional motion planning approaches are often computationally intensive or overly conservative. This paper proposes a safe motion planning strategy combining Model Predictive Control (MPC) and Control Barrier Functions (CBFs). We introduce a time-varying inflated ellipse obstacle representation, where the inflation radius is adjusted depending on the relative position and attitude between the vessel and the obstacle. The proposed adaptive inflation reduces the conservativeness of the controller compared to traditional fixed-ellipsoid obstacle formulations. The MPC solution provides an approximate motion plan, and high-order CBFs ensure the vessel's safety using the varying inflation radius. Simulation and real-world experiments demonstrate that the proposed strategy enables the fully-actuated autonomous robot vessel to navigate through narrow spaces in real time and resolve potential deadlocks, all while ensuring safety.
Decentralized Vision-Based Autonomous Aerial Wildlife Monitoring
Aug 20, 2025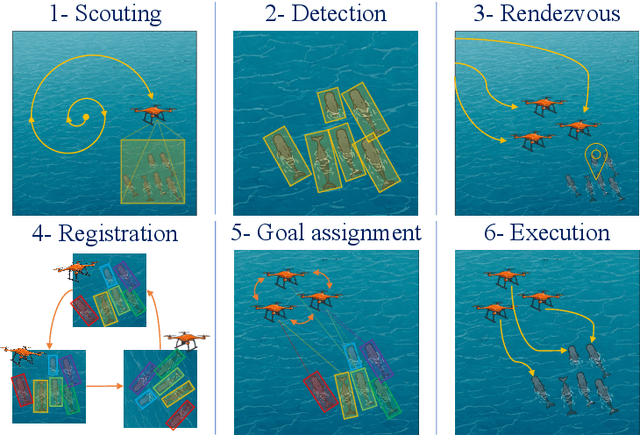
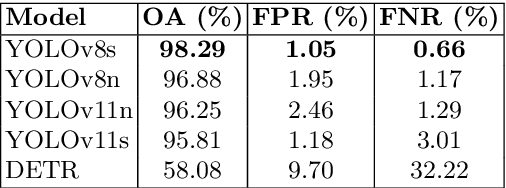


Wildlife field operations demand efficient parallel deployment methods to identify and interact with specific individuals, enabling simultaneous collective behavioral analysis, and health and safety interventions. Previous robotics solutions approach the problem from the herd perspective, or are manually operated and limited in scale. We propose a decentralized vision-based multi-quadrotor system for wildlife monitoring that is scalable, low-bandwidth, and sensor-minimal (single onboard RGB camera). Our approach enables robust identification and tracking of large species in their natural habitat. We develop novel vision-based coordination and tracking algorithms designed for dynamic, unstructured environments without reliance on centralized communication or control. We validate our system through real-world experiments, demonstrating reliable deployment in diverse field conditions.
A Roadmap for Climate-Relevant Robotics Research
Jul 15, 2025



Climate change is one of the defining challenges of the 21st century, and many in the robotics community are looking for ways to contribute. This paper presents a roadmap for climate-relevant robotics research, identifying high-impact opportunities for collaboration between roboticists and experts across climate domains such as energy, the built environment, transportation, industry, land use, and Earth sciences. These applications include problems such as energy systems optimization, construction, precision agriculture, building envelope retrofits, autonomous trucking, and large-scale environmental monitoring. Critically, we include opportunities to apply not only physical robots but also the broader robotics toolkit - including planning, perception, control, and estimation algorithms - to climate-relevant problems. A central goal of this roadmap is to inspire new research directions and collaboration by highlighting specific, actionable problems at the intersection of robotics and climate. This work represents a collaboration between robotics researchers and domain experts in various climate disciplines, and it serves as an invitation to the robotics community to bring their expertise to bear on urgent climate priorities.