 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Architecture-Token-Bitwidth Multi-Axis Optimization of Vision Transformers for Semiconductor IC Packaging
May 03, 2026Vision Transformers (ViTs) have achieved strong performance in visual recognition, yet their deployment in resource-constrained industrial environments remains limited. Some main challenges are their high computational cost, memory requirement, and energy consumption. While individual efficiency techniques such as neural architecture search (NAS), token compression, and low-precision inference have been extensively studied, most prior work targets only a single optimization axis, limiting overall deployment gains while preserving accuracy. In this paper, we present one of the first holistic frameworks that jointly optimizes three complementary axes: architecture, token, and bit-width. Specifically, the framework identifies compact backbones via Neural Architecture Search (AutoFormer), reduces information processing via token merging (ToMe), and accelerates per-operation execution via fp16 mixed-precision inference. Starting from a DeiT-B/16 baseline, we first analyze accuracy-efficiency trade-offs on ImageNet-1K under aggressive compression. Then, we apply the selected configurations to a real-world in-house 3D X-ray semiconductor defect classification dataset for IC chip packaging inspection. Results show that the proposed multi-axis framework achieves more than 10 times improvement in throughput along with over 10 times reductions in parameter count, FLOPs, and energy consumption, while maintaining the required accuracy on the downstream industrial task. To the best of our knowledge, this is among the earliest works to jointly optimize architecture, token, and bit-width dimensions in ViTs and the first such resource-efficient, deployment-focused study tailored to semiconductor manufacturing.
ByteRover: Agent-Native Memory Through LLM-Curated Hierarchical Context
Apr 02, 2026Memory-Augmented Generation (MAG) extends large language models with external memory to support long-context reasoning, but existing approaches universally treat memory as an external service that agents call into, delegating storage to separate pipelines of chunking, embedding, and graph extraction. This architectural separation means the system that stores knowledge does not understand it, leading to semantic drift between what the agent intended to remember and what the pipeline actually captured, loss of coordination context across agents, and fragile recovery after failures. In this paper, we propose ByteRover, an agent-native memory architecture that inverts the memory pipeline: the same LLM that reasons about a task also curates, structures, and retrieves knowledge. ByteRover represents knowledge in a hierarchical Context Tree, a file-based knowledge graph organized as Domain, Topic, Subtopic, and Entry, where each entry carries explicit relations, provenance, and an Adaptive Knowledge Lifecycle (AKL) with importance scoring, maturity tiers, and recency decay. Retrieval uses a 5-tier progressive strategy that resolves most queries at sub-100 ms latency without LLM calls, escalating to agentic reasoning only for novel questions. Experiments on LoCoMo and LongMemEval demonstrate that ByteRover achieves state-of-the-art accuracy on LoCoMo and competitive results on LongMemEval while requiring zero external infrastructure, no vector database, no graph database, no embedding service, with all knowledge stored as human-readable markdown files on the local filesystem.
Toward Reliable Evaluation of LLM-Based Financial Multi-Agent Systems: Taxonomy, Coordination Primacy, and Cost Awareness
Mar 29, 2026Multi-agent systems based on large language models (LLMs) for financial trading have grown rapidly since 2023, yet the field lacks a shared framework for understanding what drives performance or for evaluating claims credibly. This survey makes three contributions. First, we introduce a four-dimensional taxonomy, covering architecture pattern, coordination mechanism, memory architecture, and tool integration; applied to 12 multi-agent systems and two single-agent baselines. Second, we formulate the Coordination Primacy Hypothesis (CPH): inter-agent coordination protocol design is a primary driver of trading decision quality, often exerting greater influence than model scaling. CPH is presented as a falsifiable research hypothesis supported by tiered structural evidence rather than as an empirically validated conclusion; its definitive validation requires evaluation infrastructure that does not yet exist in the field. Third, we document five pervasive evaluation failures (look-ahead bias, survivorship bias, backtesting overfitting, transaction cost neglect, and regime-shift blindness) and show that these can reverse the sign of reported returns. Building on the CPH and the evaluation critique, we introduce the Coordination Breakeven Spread (CBS), a metric for determining whether multi-agent coordination adds genuine value net of transaction costs, and propose minimum evaluation standards as prerequisites for validating the CPH.
SAFe-Copilot: Unified Shared Autonomy Framework
Nov 06, 2025Autonomous driving systems remain brittle in rare, ambiguous, and out-of-distribution scenarios, where human driver succeed through contextual reasoning. Shared autonomy has emerged as a promising approach to mitigate such failures by incorporating human input when autonomy is uncertain. However, most existing methods restrict arbitration to low-level trajectories, which represent only geometric paths and therefore fail to preserve the underlying driving intent. We propose a unified shared autonomy framework that integrates human input and autonomous planners at a higher level of abstraction. Our method leverages Vision Language Models (VLMs) to infer driver intent from multi-modal cues -- such as driver actions and environmental context -- and to synthesize coherent strategies that mediate between human and autonomous control. We first study the framework in a mock-human setting, where it achieves perfect recall alongside high accuracy and precision. A human-subject survey further shows strong alignment, with participants agreeing with arbitration outcomes in 92% of cases. Finally, evaluation on the Bench2Drive benchmark demonstrates a substantial reduction in collision rate and improvement in overall performance compared to pure autonomy. Arbitration at the level of semantic, language-based representations emerges as a design principle for shared autonomy, enabling systems to exercise common-sense reasoning and maintain continuity with human intent.
ReGen: Generative Robot Simulation via Inverse Design
Nov 06, 2025Simulation plays a key role in scaling robot learning and validating policies, but constructing simulations remains a labor-intensive process. This paper introduces ReGen, a generative simulation framework that automates simulation design via inverse design. Given a robot's behavior -- such as a motion trajectory or an objective function -- and its textual description, ReGen infers plausible scenarios and environments that could have caused the behavior. ReGen leverages large language models to synthesize scenarios by expanding a directed graph that encodes cause-and-effect relationships, relevant entities, and their properties. This structured graph is then translated into a symbolic program, which configures and executes a robot simulation environment. Our framework supports (i) augmenting simulations based on ego-agent behaviors, (ii) controllable, counterfactual scenario generation, (iii) reasoning about agent cognition and mental states, and (iv) reasoning with distinct sensing modalities, such as braking due to faulty GPS signals. We demonstrate ReGen in autonomous driving and robot manipulation tasks, generating more diverse, complex simulated environments compared to existing simulations with high success rates, and enabling controllable generation for corner cases. This approach enhances the validation of robot policies and supports data or simulation augmentation, advancing scalable robot learning for improved generalization and robustness. We provide code and example videos at: https://regen-sim.github.io/
Generating Out-Of-Distribution Scenarios Using Language Models
Nov 25, 2024



The deployment of autonomous vehicles controlled by machine learning techniques requires extensive testing in diverse real-world environments, robust handling of edge cases and out-of-distribution scenarios, and comprehensive safety validation to ensure that these systems can navigate safely and effectively under unpredictable conditions. Addressing Out-Of-Distribution (OOD) driving scenarios is essential for enhancing safety, as OOD scenarios help validate the reliability of the models within the vehicle's autonomy stack. However, generating OOD scenarios is challenging due to their long-tailed distribution and rarity in urban driving dataset. Recently, Large Language Models (LLMs) have shown promise in autonomous driving, particularly for their zero-shot generalization and common-sense reasoning capabilities. In this paper, we leverage these LLM strengths to introduce a framework for generating diverse OOD driving scenarios. Our approach uses LLMs to construct a branching tree, where each branch represents a unique OOD scenario. These scenarios are then simulated in the CARLA simulator using an automated framework that aligns scene augmentation with the corresponding textual descriptions. We evaluate our framework through extensive simulations, and assess its performance via a diversity metric that measures the richness of the scenarios. Additionally, we introduce a new "OOD-ness" metric, which quantifies how much the generated scenarios deviate from typical urban driving conditions. Furthermore, we explore the capacity of modern Vision-Language Models (VLMs) to interpret and safely navigate through the simulated OOD scenarios. Our findings offer valuable insights into the reliability of language models in addressing OOD scenarios within the context of urban driving.
Text-to-Drive: Diverse Driving Behavior Synthesis via Large Language Models
Jun 06, 2024



Generating varied scenarios through simulation is crucial for training and evaluating safety-critical systems, such as autonomous vehicles. Yet, the task of modeling the trajectories of other vehicles to simulate diverse and meaningful close interactions remains prohibitively costly. Adopting language descriptions to generate driving behaviors emerges as a promising strategy, offering a scalable and intuitive method for human operators to simulate a wide range of driving interactions. However, the scarcity of large-scale annotated language-trajectory data makes this approach challenging. To address this gap, we propose Text-to-Drive (T2D) to synthesize diverse driving behaviors via Large Language Models (LLMs). We introduce a knowledge-driven approach that operates in two stages. In the first stage, we employ the embedded knowledge of LLMs to generate diverse language descriptions of driving behaviors for a scene. Then, we leverage LLM's reasoning capabilities to synthesize these behaviors in simulation. At its core, T2D employs an LLM to construct a state chart that maps low-level states to high-level abstractions. This strategy aids in downstream tasks such as summarizing low-level observations, assessing policy alignment with behavior description, and shaping the auxiliary reward, all without needing human supervision. With our knowledge-driven approach, we demonstrate that T2D generates more diverse trajectories compared to other baselines and offers a natural language interface that allows for interactive incorporation of human preference. Please check our website for more examples: https://text-to-drive.github.io/
Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes
Sep 15, 2023



We present an approach to estimating camera rotation in crowded, real-world scenes from handheld monocular video. While camera rotation estimation is a well-studied problem, no previous methods exhibit both high accuracy and acceptable speed in this setting. Because the setting is not addressed well by other datasets, we provide a new dataset and benchmark, with high-accuracy, rigorously verified ground truth, on 17 video sequences. Methods developed for wide baseline stereo (e.g., 5-point methods) perform poorly on monocular video. On the other hand, methods used in autonomous driving (e.g., SLAM) leverage specific sensor setups, specific motion models, or local optimization strategies (lagging batch processing) and do not generalize well to handheld video. Finally, for dynamic scenes, commonly used robustification techniques like RANSAC require large numbers of iterations, and become prohibitively slow. We introduce a novel generalization of the Hough transform on SO(3) to efficiently and robustly find the camera rotation most compatible with optical flow. Among comparably fast methods, ours reduces error by almost 50\% over the next best, and is more accurate than any method, irrespective of speed. This represents a strong new performance point for crowded scenes, an important setting for computer vision. The code and the dataset are available at https://fabiendelattre.com/robust-rotation-estimation.
Contextual Explainable Video Representation: Human Perception-based Understanding
Dec 17, 2022



Video understanding is a growing field and a subject of intense research, which includes many interesting tasks to understanding both spatial and temporal information, e.g., action detection, action recognition, video captioning, video retrieval. One of the most challenging problems in video understanding is dealing with feature extraction, i.e. extract contextual visual representation from given untrimmed video due to the long and complicated temporal structure of unconstrained videos. Different from existing approaches, which apply a pre-trained backbone network as a black-box to extract visual representation, our approach aims to extract the most contextual information with an explainable mechanism. As we observed, humans typically perceive a video through the interactions between three main factors, i.e., the actors, the relevant objects, and the surrounding environment. Therefore, it is very crucial to design a contextual explainable video representation extraction that can capture each of such factors and model the relationships between them. In this paper, we discuss approaches, that incorporate the human perception process into modeling actors, objects, and the environment. We choose video paragraph captioning and temporal action detection to illustrate the effectiveness of human perception based-contextual representation in video understanding. Source code is publicly available at https://github.com/UARK-AICV/Video_Representation.
FORECASTER: A Continual Lifelong Learning Approach to Improve Hardware Efficiency
Apr 27, 2020
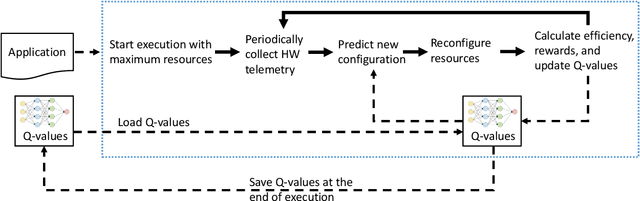
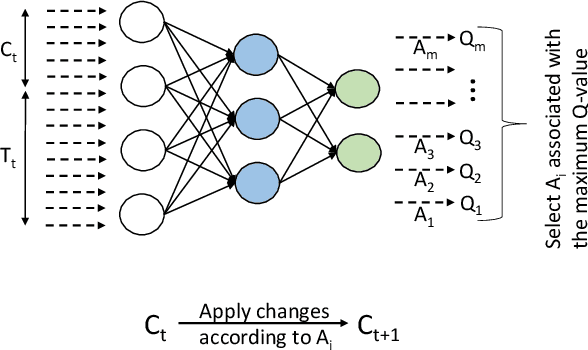
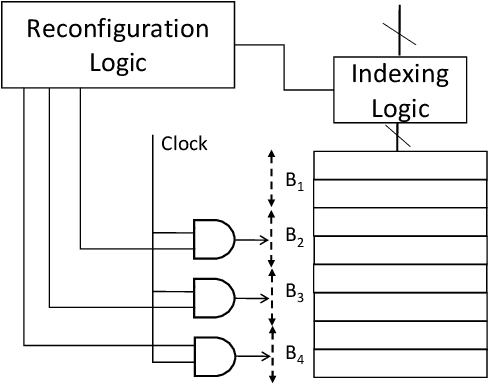
Computer applications are continuously evolving. However, significant knowledge can be harvested from older applications or versions and applied in the context of newer applications or versions. Such a vision can be realized with Continual Lifelong Learning. Therefore, we propose to employ continual lifelong learning to dynamically tune hardware configurations based on application behavior. The goal of such tuning is to maximize hardware efficiency (i.e., maximize an application performance while minimizing the hardware energy consumption). Our proposed approach, FORECASTER, uses deep reinforcement learning to continually learn during the execution of an application as well as propagate and utilize the accumulated knowledge during subsequent executions of the same or new application. We propose a novel hardware and ISA support to implement deep reinforcement learning. We implement FORECASTER and compare its performance against prior learning-based hardware reconfiguration approaches. Our results show that FORECASTER can save an average 16% of system power over the baseline setup with full usage of hardware while sacrificing an average of 4.7% of execution time.