 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Pruning for Efficient 3D Gaussian Splatting via Coresets
Jul 02, 20263D Gaussian Splatting (3DGS) enables high-quality real-time novel-view synthesis, but practical scenes often contain millions of Gaussians, making compression essential for deployment on limited hardware. Existing reduction methods are effective but mostly heuristic: they provide no multiplicative approximation guarantee for the rendered objective, and thus rely heavily on costly post-pruning finetuning to recover quality. We ask a basic question: can a 3DGS scene be provably replaced by a much smaller weighted subset (coreset) while preserving the objective of interest? We first show that, in the unrestricted setting, no non-trivial multiplicative 3DGS coreset exists. We then show that multiplicative guarantees are not impossible, but resolution-dependent. For a prescribed rendering resolution, such as representative views or grids of views/rays, we provide the first weighted coreset construction theorem for 3DGS. The construction samples Gaussians by sensitivity: provable importance scores measuring each Gaussian's role in the full-scene objective. Finally, under explicit validity and log-transmittance stability assumptions, we turn this objective guarantee into a rendering guarantee. Empirically, our method is strongest where deployment needs it most: aggressive compression with no or minimal recovery compute. In prune-only and very short finetuning regimes, it achieves state-of-the-art performance, showing that principled importance estimation can be both theoretically meaningful and practically useful. Open-source code is available at https://github.com/waseem-m/3dgs_provable_coresets.
Supportive Token Revealing for Fast Diffusion Language Model Decoding
Jun 02, 2026Discrete diffusion language models can generate text efficiently by updating multiple masked positions in parallel, but this parallelism introduces a quality-latency trade-off. Aggressive decoding may commit mutually dependent tokens too early, while conservative decoding requires many denoising steps. Existing methods address this tension by deciding which tokens are safe to reveal using confidence or dependency criteria. However, avoiding unsafe commits does not necessarily make the remaining masked sequence easy to decode, since uncertain tokens may depend on masked tokens, creating a bottleneck for denoising steps. We propose AXON, a training-free module that can be added on top of existing parallel decoding strategies for diffusion language models. Rather than replacing the base decoder, AXON monitors the remaining uncertain masked tokens and intervenes only when their current state suggests that additional context is needed. It then shifts the criterion from which tokens are safest to reveal to which confident reveals would best support later denoising. AXON selects anchors, confident masked tokens that uncertain positions attend to, using attention, uncertainty, and confidence signals. Experiments on reasoning and code-generation benchmarks across multiple diffusion language models show that AXON improves the quality-latency trade-off of existing parallel decoders, often reducing the number of function evaluations while maintaining or improving accuracy.
Efficient Test-Time Finetuning of LLMs via Convex Reconstruction and Gradient Caching
May 28, 2026Test-time finetuning (TTFT) is a rapidly evolving paradigm that adapts a language model to each prompt by retrieving related sequences, updating the model on them, and then evaluating the prompt. However, TTFT is only practical if it is fast: selection and finetuning both happen per query, making each a direct bottleneck. Existing methods trade speed for quality: fast retrieval is often redundant, while stronger diversity-aware selection adds prohibitive per-query cost. We introduce HullFT, a geometric approach to TTFT that addresses both bottlenecks. Given a query, HullFT first represents the query embedding as a sparse convex combination of few training sequences, using efficient projection-free Frank-Wolfe optimization. This yields a support set that is inherently relevant and diverse. We then convert the fractional convex weights into an exact integer multiset for finetuning through a geometric integerization procedure. The resulting multiplicities naturally create repeated examples, which we exploit with Gradient Reuse to amortize forward-backward computation across repeated finetuning steps. Our experiments show that HullFT improves the quality-efficiency tradeoff over current state-of-the-art TTFT methods, achieving lower bits-per-byte at substantially lower total runtime.
Autonomous Sea Turtle Robot for Marine Fieldwork
Feb 24, 2026Autonomous robots can transform how we observe marine ecosystems, but close-range operation in reefs and other cluttered habitats remains difficult. Vehicles must maneuver safely near animals and fragile structures while coping with currents, variable illumination and limited sensing. Previous approaches simplify these problems by leveraging soft materials and bioinspired swimming designs, but such platforms remain limited in terms of deployable autonomy. Here we present a sea turtle-inspired autonomous underwater robot that closed the gap between bioinspired locomotion and field-ready autonomy through a tightly integrated, vision-driven control stack. The robot combines robust depth-heading stabilization with obstacle avoidance and target-centric control, enabling it to track and interact with moving objects in complex terrain. We validate the robot in controlled pool experiments and in a live coral reef exhibit at the New England Aquarium, demonstrating stable operation and reliable tracking of fast-moving marine animals and human divers. To the best of our knowledge, this is the first integrated biomimetic robotic system, combining novel hardware, control, and field experiments, deployed to track and monitor real marine animals in their natural environment. During off-tether experiments, we demonstrate safe navigation around obstacles (91\% success rate in the aquarium exhibit) and introduce a low-compute onboard tracking mode. Together, these results establish a practical route toward soft-rigid hybrid, bioinspired underwater robots capable of minimally disruptive exploration and close-range monitoring in sensitive ecosystems.
Robustness Is a Function, Not a Number: A Factorized Comprehensive Study of OOD Robustness in Vision-Based Driving
Feb 09, 2026Out of distribution (OOD) robustness in autonomous driving is often reduced to a single number, hiding what breaks a policy. We decompose environments along five axes: scene (rural/urban), season, weather, time (day/night), and agent mix; and measure performance under controlled $k$-factor perturbations ($k \in \{0,1,2,3\}$). Using closed loop control in VISTA, we benchmark FC, CNN, and ViT policies, train compact ViT heads on frozen foundation-model (FM) features, and vary ID support in scale, diversity, and temporal context. (1) ViT policies are markedly more OOD-robust than comparably sized CNN/FC, and FM features yield state-of-the-art success at a latency cost. (2) Naive temporal inputs (multi-frame) do not beat the best single-frame baseline. (3) The largest single factor drops are rural $\rightarrow$ urban and day $\rightarrow$ night ($\sim 31\%$ each); actor swaps $\sim 10\%$, moderate rain $\sim 7\%$; season shifts can be drastic, and combining a time flip with other changes further degrades performance. (4) FM-feature policies stay above $85\%$ under three simultaneous changes; non-FM single-frame policies take a large first-shift hit, and all no-FM models fall below $50\%$ by three changes. (5) Interactions are non-additive: some pairings partially offset, whereas season-time combinations are especially harmful. (6) Training on winter/snow is most robust to single-factor shifts, while a rural+summer baseline gives the best overall OOD performance. (7) Scaling traces/views improves robustness ($+11.8$ points from $5$ to $14$ traces), yet targeted exposure to hard conditions can substitute for scale. (8) Using multiple ID environments broadens coverage and strengthens weak cases (urban OOD $60.6\% \rightarrow 70.1\%$) with a small ID drop; single-ID preserves peak performance but in a narrow domain. These results yield actionable design rules for OOD-robust driving policies.
See Less, Drive Better: Generalizable End-to-End Autonomous Driving via Foundation Models Stochastic Patch Selection
Jan 15, 2026Recent advances in end-to-end autonomous driving show that policies trained on patch-aligned features extracted from foundation models generalize better to Out-of-Distribution (OOD). We hypothesize that due to the self-attention mechanism, each patch feature implicitly embeds/contains information from all other patches, represented in a different way and intensity, making these descriptors highly redundant. We quantify redundancy in such (BLIP2) features via PCA and cross-patch similarity: $90$% of variance is captured by $17/64$ principal components, and strong inter-token correlations are pervasive. Training on such overlapping information leads the policy to overfit spurious correlations, hurting OOD robustness. We present Stochastic-Patch-Selection (SPS), a simple yet effective approach for learning policies that are more robust, generalizable, and efficient. For every frame, SPS randomly masks a fraction of patch descriptors, not feeding them to the policy model, while preserving the spatial layout of the remaining patches. Thus, the policy is provided with different stochastic but complete views of the (same) scene: every random subset of patches acts like a different, yet still sensible, coherent projection of the world. The policy thus bases its decisions on features that are invariant to which specific tokens survive. Extensive experiments confirm that across all OOD scenarios, our method outperforms the state of the art (SOTA), achieving a $6.2$% average improvement and up to $20.4$% in closed-loop simulations, while being $2.4\times$ faster. We conduct ablations over masking rates and patch-feature reorganization, training and evaluating 9 systems, with 8 of them surpassing prior SOTA. Finally, we show that the same learned policy transfers to a physical, real-world car without any tuning.
Compress to Impress: Efficient LLM Adaptation Using a Single Gradient Step on 100 Samples
Oct 23, 2025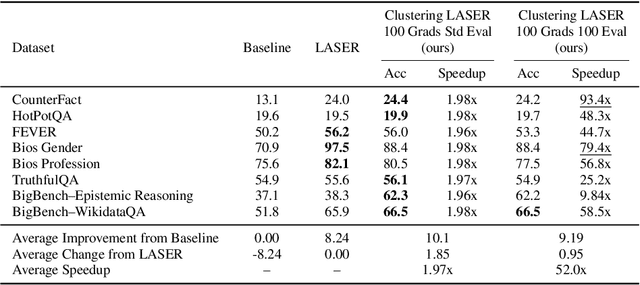
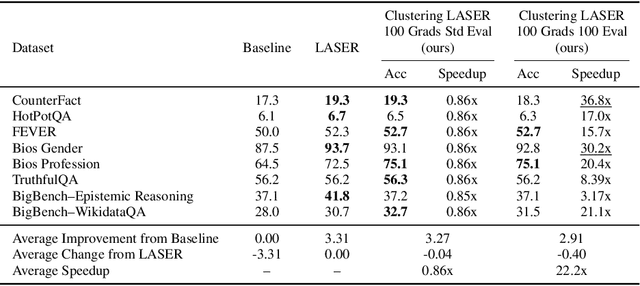
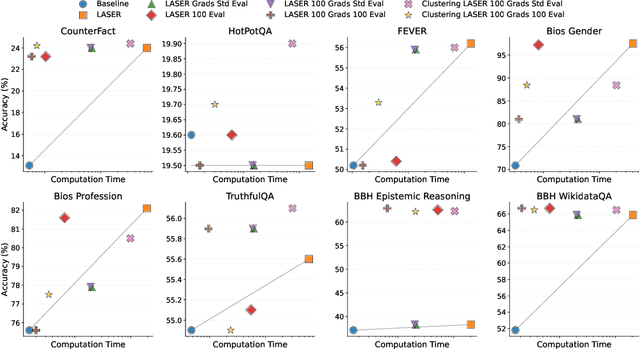
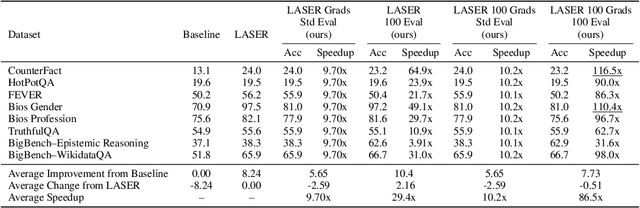
Recently, Sharma et al. suggested a method called Layer-SElective-Rank reduction (LASER) which demonstrated that pruning high-order components of carefully chosen LLM's weight matrices can boost downstream accuracy -- without any gradient-based fine-tuning. Yet LASER's exhaustive, per-matrix search (each requiring full-dataset forward passes) makes it impractical for rapid deployment. We demonstrate that this overhead can be removed and find that: (i) Only a small, carefully chosen subset of matrices needs to be inspected -- eliminating the layer-by-layer sweep, (ii) The gradient of each matrix's singular values pinpoints which matrices merit reduction, (iii) Increasing the factorization search space by allowing matrices rows to cluster around multiple subspaces and then decomposing each cluster separately further reduces overfitting on the original training data and further lifts accuracy by up to 24.6 percentage points, and finally, (iv) we discover that evaluating on just 100 samples rather than the full training data -- both for computing the indicative gradients and for measuring the final accuracy -- suffices to further reduce the search time; we explain that as adaptation to downstream tasks is dominated by prompting style, not dataset size. As a result, we show that combining these findings yields a fast and robust adaptation algorithm for downstream tasks. Overall, with a single gradient step on 100 examples and a quick scan of the top candidate layers and factorization techniques, we can adapt LLMs to new datasets -- entirely without fine-tuning.
Decentralized Vision-Based Autonomous Aerial Wildlife Monitoring
Aug 20, 2025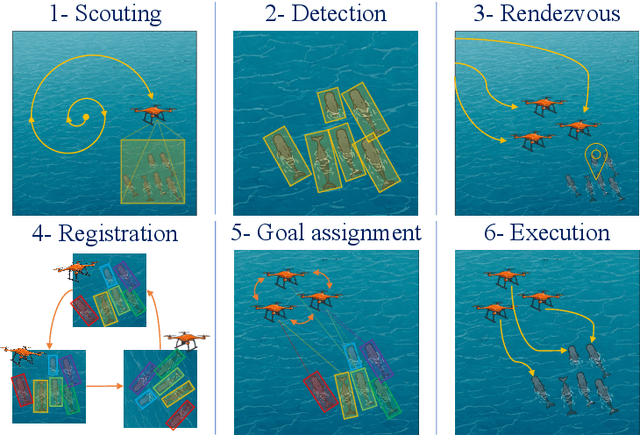
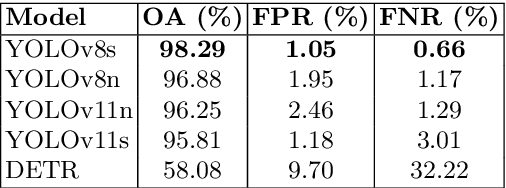


Wildlife field operations demand efficient parallel deployment methods to identify and interact with specific individuals, enabling simultaneous collective behavioral analysis, and health and safety interventions. Previous robotics solutions approach the problem from the herd perspective, or are manually operated and limited in scale. We propose a decentralized vision-based multi-quadrotor system for wildlife monitoring that is scalable, low-bandwidth, and sensor-minimal (single onboard RGB camera). Our approach enables robust identification and tracking of large species in their natural habitat. We develop novel vision-based coordination and tracking algorithms designed for dynamic, unstructured environments without reliance on centralized communication or control. We validate our system through real-world experiments, demonstrating reliable deployment in diverse field conditions.
Prompts to Summaries: Zero-Shot Language-Guided Video Summarization
Jun 12, 2025



The explosive growth of video data intensified the need for flexible user-controllable summarization tools that can operate without domain-specific training data. Existing methods either rely on datasets, limiting generalization, or cannot incorporate user intent expressed in natural language. We introduce Prompts-to-Summaries: the first zero-shot, text-queryable video summarizer that converts off-the-shelf video-language models (VidLMs) captions into user-guided skims via large language models (LLMs) judging, without the use of training data at all, beating all unsupervised and matching supervised methods. Our pipeline (i) segments raw video footage into coherent scenes, (ii) generates rich scene-level descriptions through a memory-efficient, batch-style VidLM prompting scheme that scales to hours-long videos on a single GPU, (iii) leverages an LLM as a judge to assign scene-level importance scores under a carefully crafted prompt, and finally, (iv) propagates those scores to short segments level via two new metrics: consistency (temporal coherency) and uniqueness (novelty), yielding fine-grained frame importance. On SumMe and TVSum, our data-free approach surpasses all prior data-hungry unsupervised methods. It also performs competitively on the Query-Focused Video Summarization (QFVS) benchmark, despite using no training data and the competing methods requiring supervised frame-level importance. To spur further research, we release VidSum-Reason, a new query-driven dataset featuring long-tailed concepts and multi-step reasoning; our framework attains robust F1 scores and serves as the first challenging baseline. Overall, our results demonstrate that pretrained multimodal models, when orchestrated with principled prompting and score propagation, already provide a powerful foundation for universal, text-queryable video summarization.
DataS^3: Dataset Subset Selection for Specialization
Apr 22, 2025



In many real-world machine learning (ML) applications (e.g. detecting broken bones in x-ray images, detecting species in camera traps), in practice models need to perform well on specific deployments (e.g. a specific hospital, a specific national park) rather than the domain broadly. However, deployments often have imbalanced, unique data distributions. Discrepancy between the training distribution and the deployment distribution can lead to suboptimal performance, highlighting the need to select deployment-specialized subsets from the available training data. We formalize dataset subset selection for specialization (DS3): given a training set drawn from a general distribution and a (potentially unlabeled) query set drawn from the desired deployment-specific distribution, the goal is to select a subset of the training data that optimizes deployment performance. We introduce DataS^3; the first dataset and benchmark designed specifically for the DS3 problem. DataS^3 encompasses diverse real-world application domains, each with a set of distinct deployments to specialize in. We conduct a comprehensive study evaluating algorithms from various families--including coresets, data filtering, and data curation--on DataS^3, and find that general-distribution methods consistently fail on deployment-specific tasks. Additionally, we demonstrate the existence of manually curated (deployment-specific) expert subsets that outperform training on all available data with accuracy gains up to 51.3 percent. Our benchmark highlights the critical role of tailored dataset curation in enhancing performance and training efficiency on deployment-specific distributions, which we posit will only become more important as global, public datasets become available across domains and ML models are deployed in the real world.