 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal State Nudging: Reducing Skill Atrophy from AI Assistance
May 19, 2026Skill atrophy, the gradual decline of human capability under AI assistance, poses a safety risk in shared-control of semi-autonomous systems, where operators may be unable to distinguish their own inputs from autonomous corrections. We propose Proximal State Nudging (PSN), a shared autonomy algorithm that jointly optimizes for skill development and task performance by nudging users toward states estimated to be most learnable. We first show that PSN outperforms existing shared autonomy baselines in balancing student improvement in unassisted reward with overall shared performance, using simulated students in the classic LunarLander environment. We then present, to the best of our knowledge, the first human subject studies of a planner incorporating learning-compatible shared autonomy: across two driving tasks in the CARLA simulator (High Performance Racing and Parallel Parking, n = 60), PSN produces up to 7x larger gains in unassisted skill than standard blended shared autonomy, while incurring 50% fewer collisions than unassisted self-practice.
On the Strengths and Weaknesses of Data for Open-set Embodied Assistance
Mar 05, 2026Embodied foundation models are increasingly performant in real-world domains such as robotics or autonomous driving. These models are often deployed in interactive or assistive settings, where it is important that these assistive models generalize to new users and new tasks. Diverse interactive data generation offers a promising avenue for providing data-efficient generalization capabilities for interactive embodied foundation models. In this paper, we investigate the generalization capabilities of a multimodal foundation model fine-tuned on diverse interactive assistance data in a synthetic domain. We explore generalization along two axes: a) assistance with unseen categories of user behavior and b) providing guidance in new configurations not encountered during training. We study a broad capability called \textbf{Open-Set Corrective Assistance}, in which the model needs to inspect lengthy user behavior and provide assistance through either corrective actions or language-based feedback. This task remains unsolved in prior work, which typically assumes closed corrective categories or relies on external planners, making it a challenging testbed for evaluating the limits of assistive data. To support this task, we generate synthetic assistive datasets in Overcooked and fine-tune a LLaMA-based model to evaluate generalization to novel tasks and user behaviors. Our approach provides key insights into the nature of assistive datasets required to enable open-set assistive intelligence. In particular, we show that performant models benefit from datasets that cover different aspects of assistance, including multimodal grounding, defect inference, and exposure to diverse scenarios.
SAFe-Copilot: Unified Shared Autonomy Framework
Nov 06, 2025Autonomous driving systems remain brittle in rare, ambiguous, and out-of-distribution scenarios, where human driver succeed through contextual reasoning. Shared autonomy has emerged as a promising approach to mitigate such failures by incorporating human input when autonomy is uncertain. However, most existing methods restrict arbitration to low-level trajectories, which represent only geometric paths and therefore fail to preserve the underlying driving intent. We propose a unified shared autonomy framework that integrates human input and autonomous planners at a higher level of abstraction. Our method leverages Vision Language Models (VLMs) to infer driver intent from multi-modal cues -- such as driver actions and environmental context -- and to synthesize coherent strategies that mediate between human and autonomous control. We first study the framework in a mock-human setting, where it achieves perfect recall alongside high accuracy and precision. A human-subject survey further shows strong alignment, with participants agreeing with arbitration outcomes in 92% of cases. Finally, evaluation on the Bench2Drive benchmark demonstrates a substantial reduction in collision rate and improvement in overall performance compared to pure autonomy. Arbitration at the level of semantic, language-based representations emerges as a design principle for shared autonomy, enabling systems to exercise common-sense reasoning and maintain continuity with human intent.
ReGen: Generative Robot Simulation via Inverse Design
Nov 06, 2025Simulation plays a key role in scaling robot learning and validating policies, but constructing simulations remains a labor-intensive process. This paper introduces ReGen, a generative simulation framework that automates simulation design via inverse design. Given a robot's behavior -- such as a motion trajectory or an objective function -- and its textual description, ReGen infers plausible scenarios and environments that could have caused the behavior. ReGen leverages large language models to synthesize scenarios by expanding a directed graph that encodes cause-and-effect relationships, relevant entities, and their properties. This structured graph is then translated into a symbolic program, which configures and executes a robot simulation environment. Our framework supports (i) augmenting simulations based on ego-agent behaviors, (ii) controllable, counterfactual scenario generation, (iii) reasoning about agent cognition and mental states, and (iv) reasoning with distinct sensing modalities, such as braking due to faulty GPS signals. We demonstrate ReGen in autonomous driving and robot manipulation tasks, generating more diverse, complex simulated environments compared to existing simulations with high success rates, and enabling controllable generation for corner cases. This approach enhances the validation of robot policies and supports data or simulation augmentation, advancing scalable robot learning for improved generalization and robustness. We provide code and example videos at: https://regen-sim.github.io/
SimCoachCorpus: A naturalistic dataset with language and trajectories for embodied teaching
Sep 18, 2025Curated datasets are essential for training and evaluating AI approaches, but are often lacking in domains where language and physical action are deeply intertwined. In particular, few datasets capture how people acquire embodied skills through verbal instruction over time. To address this gap, we introduce SimCoachCorpus: a unique dataset of race car simulator driving that allows for the investigation of rich interactive phenomena during guided and unguided motor skill acquisition. In this dataset, 29 humans were asked to drive in a simulator around a race track for approximately ninety minutes. Fifteen participants were given personalized one-on-one instruction from a professional performance driving coach, and 14 participants drove without coaching. \name\ includes embodied features such as vehicle state and inputs, map (track boundaries and raceline), and cone landmarks. These are synchronized with concurrent verbal coaching from a professional coach and additional feedback at the end of each lap. We further provide annotations of coaching categories for each concurrent feedback utterance, ratings on students' compliance with coaching advice, and self-reported cognitive load and emotional state of participants (gathered from surveys during the study). The dataset includes over 20,000 concurrent feedback utterances, over 400 terminal feedback utterances, and over 40 hours of vehicle driving data. Our naturalistic dataset can be used for investigating motor learning dynamics, exploring linguistic phenomena, and training computational models of teaching. We demonstrate applications of this dataset for in-context learning, imitation learning, and topic modeling. The dataset introduced in this work will be released publicly upon publication of the peer-reviewed version of this paper. Researchers interested in early access may register at https://tinyurl.com/SimCoachCorpusForm.
Timing the Message: Language-Based Notifications for Time-Critical Assistive Settings
Sep 09, 2025In time-critical settings such as assistive driving, assistants often rely on alerts or haptic signals to prompt rapid human attention, but these cues usually leave humans to interpret situations and decide responses independently, introducing potential delays or ambiguity in meaning. Language-based assistive systems can instead provide instructions backed by context, offering more informative guidance. However, current approaches (e.g., social assistive robots) largely prioritize content generation while overlooking critical timing factors such as verbal conveyance duration, human comprehension delays, and subsequent follow-through duration. These timing considerations are crucial in time-critical settings, where even minor delays can substantially affect outcomes. We aim to study this inherent trade-off between timeliness and informativeness by framing the challenge as a sequential decision-making problem using an augmented-state Markov Decision Process. We design a framework combining reinforcement learning and a generated offline taxonomy dataset, where we balance the trade-off while enabling a scalable taxonomy dataset generation pipeline. Empirical evaluation with synthetic humans shows our framework improves success rates by over 40% compared to methods that ignore time delays, while effectively balancing timeliness and informativeness. It also exposes an often-overlooked trade-off between these two factors, opening new directions for optimizing communication in time-critical human-AI assistance.
Shared Autonomy for Proximal Teaching
Feb 27, 2025Motor skill learning often requires experienced professionals who can provide personalized instruction. Unfortunately, the availability of high-quality training can be limited for specialized tasks, such as high performance racing. Several recent works have leveraged AI-assistance to improve instruction of tasks ranging from rehabilitation to surgical robot tele-operation. However, these works often make simplifying assumptions on the student learning process, and fail to model how a teacher's assistance interacts with different individuals' abilities when determining optimal teaching strategies. Inspired by the idea of scaffolding from educational psychology, we leverage shared autonomy, a framework for combining user inputs with robot autonomy, to aid with curriculum design. Our key insight is that the way a student's behavior improves in the presence of assistance from an autonomous agent can highlight which sub-skills might be most ``learnable'' for the student, or within their Zone of Proximal Development. We use this to design Z-COACH, a method for using shared autonomy to provide personalized instruction targeting interpretable task sub-skills. In a user study (n=50), where we teach high performance racing in a simulated environment of the Thunderhill Raceway Park with the CARLA Autonomous Driving simulator, we show that Z-COACH helps identify which skills each student should first practice, leading to an overall improvement in driving time, behavior, and smoothness. Our work shows that increasingly available semi-autonomous capabilities (e.g. in vehicles, robots) can not only assist human users, but also help *teach* them.
Dreaming to Assist: Learning to Align with Human Objectives for Shared Control in High-Speed Racing
Oct 14, 2024Tight coordination is required for effective human-robot teams in domains involving fast dynamics and tactical decisions, such as multi-car racing. In such settings, robot teammates must react to cues of a human teammate's tactical objective to assist in a way that is consistent with the objective (e.g., navigating left or right around an obstacle). To address this challenge, we present Dream2Assist, a framework that combines a rich world model able to infer human objectives and value functions, and an assistive agent that provides appropriate expert assistance to a given human teammate. Our approach builds on a recurrent state space model to explicitly infer human intents, enabling the assistive agent to select actions that align with the human and enabling a fluid teaming interaction. We demonstrate our approach in a high-speed racing domain with a population of synthetic human drivers pursuing mutually exclusive objectives, such as "stay-behind" and "overtake". We show that the combined human-robot team, when blending its actions with those of the human, outperforms the synthetic humans alone as well as several baseline assistance strategies, and that intent-conditioning enables adherence to human preferences during task execution, leading to improved performance while satisfying the human's objective.
Interpretable Reinforcement Learning for Robotics and Continuous Control
Nov 16, 2023



Interpretability in machine learning is critical for the safe deployment of learned policies across legally-regulated and safety-critical domains. While gradient-based approaches in reinforcement learning have achieved tremendous success in learning policies for continuous control problems such as robotics and autonomous driving, the lack of interpretability is a fundamental barrier to adoption. We propose Interpretable Continuous Control Trees (ICCTs), a tree-based model that can be optimized via modern, gradient-based, reinforcement learning approaches to produce high-performing, interpretable policies. The key to our approach is a procedure for allowing direct optimization in a sparse decision-tree-like representation. We validate ICCTs against baselines across six domains, showing that ICCTs are capable of learning policies that parity or outperform baselines by up to 33% in autonomous driving scenarios while achieving a 300x-600x reduction in the number of parameters against deep learning baselines. We prove that ICCTs can serve as universal function approximators and display analytically that ICCTs can be verified in linear time. Furthermore, we deploy ICCTs in two realistic driving domains, based on interstate Highway-94 and 280 in the US. Finally, we verify ICCT's utility with end-users and find that ICCTs are rated easier to simulate, quicker to validate, and more interpretable than neural networks.
FedPC: Federated Learning for Language Generation with Personal and Context Preference Embeddings
Oct 07, 2022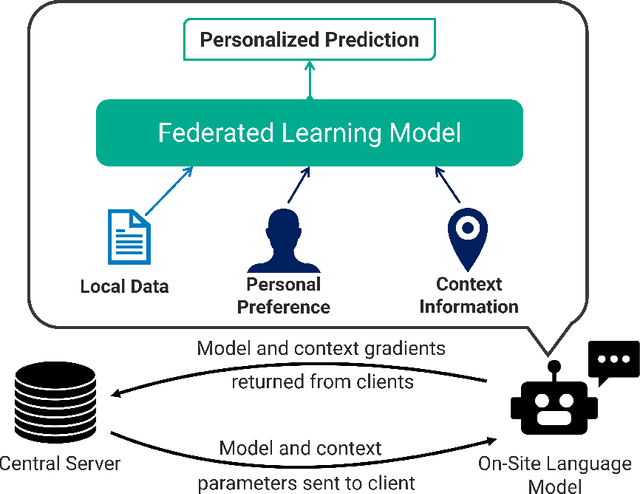
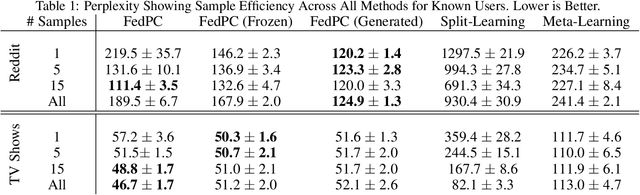
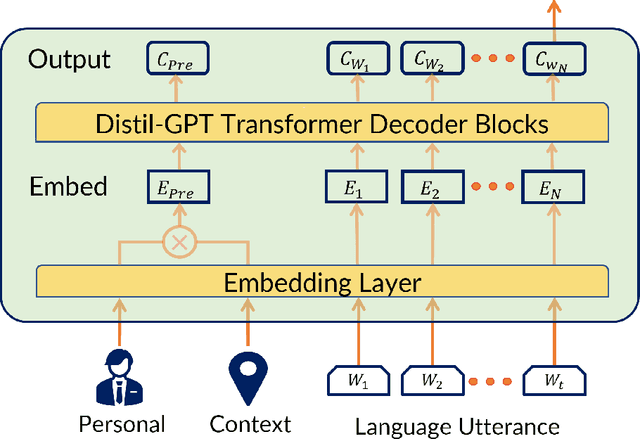
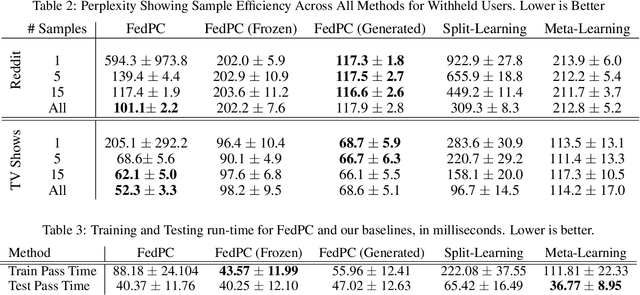
Federated learning is a training paradigm that learns from multiple distributed users without aggregating data on a centralized server. Such a paradigm promises the ability to deploy machine-learning at-scale to a diverse population of end-users without first collecting a large, labeled dataset for all possible tasks. As federated learning typically averages learning updates across a decentralized population, there is a growing need for personalization of federated learning systems (i.e conversational agents must be able to personalize to a specific user's preferences). In this work, we propose a new direction for personalization research within federated learning, leveraging both personal embeddings and shared context embeddings. We also present an approach to predict these ``preference'' embeddings, enabling personalization without backpropagation. Compared to state-of-the-art personalization baselines, our approach achieves a 50\% improvement in test-time perplexity using 0.001\% of the memory required by baseline approaches, and achieving greater sample- and compute-efficiency.