 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Norm Truncation: Robust Training in the Presence of Data Noise for Text Generation Models
Oct 02, 2023Text generation models are notoriously vulnerable to errors in the training data. With the wide-spread availability of massive amounts of web-crawled data becoming more commonplace, how can we enhance the robustness of models trained on a massive amount of noisy web-crawled text? In our work, we propose Error Norm Truncation (ENT), a robust enhancement method to the standard training objective that truncates noisy data. Compared to methods that only uses the negative log-likelihood loss to estimate data quality, our method provides a more accurate estimation by considering the distribution of non-target tokens, which is often overlooked by previous work. Through comprehensive experiments across language modeling, machine translation, and text summarization, we show that equipping text generation models with ENT improves generation quality over standard training and previous soft and hard truncation methods. Furthermore, we show that our method improves the robustness of models against two of the most detrimental types of noise in machine translation, resulting in an increase of more than 2 BLEU points over the MLE baseline when up to 50% of noise is added to the data.
The Trickle-down Impact of Reward consistency on RLHF
Sep 28, 2023



Standard practice within Reinforcement Learning from Human Feedback (RLHF) involves optimizing against a Reward Model (RM), which itself is trained to reflect human preferences for desirable generations. A notable subject that is understudied is the (in-)consistency of RMs -- whether they can recognize the semantic changes to different prompts and appropriately adapt their reward assignments -- and their impact on the downstream RLHF model. In this paper, we visit a series of research questions relevant to RM inconsistency: (1) How can we measure the consistency of reward models? (2) How consistent are the existing RMs and how can we improve them? (3) In what ways does reward inconsistency influence the chatbots resulting from the RLHF model training? We propose Contrast Instructions -- a benchmarking strategy for the consistency of RM. Each example in Contrast Instructions features a pair of lexically similar instructions with different ground truth responses. A consistent RM is expected to rank the corresponding instruction and response higher than other combinations. We observe that current RMs trained with the standard ranking objective fail miserably on Contrast Instructions compared to average humans. To show that RM consistency can be improved efficiently without using extra training budget, we propose two techniques ConvexDA and RewardFusion, which enhance reward consistency through extrapolation during the RM training and inference stage, respectively. We show that RLHF models trained with a more consistent RM yield more useful responses, suggesting that reward inconsistency exhibits a trickle-down effect on the downstream RLHF process.
GEAR: Augmenting Language Models with Generalizable and Efficient Tool Resolution
Jul 17, 2023



Augmenting large language models (LLM) to use external tools enhances their performance across a variety of tasks. However, prior works over-rely on task-specific demonstration of tool use that limits their generalizability and computational cost due to making many calls to large-scale LLMs. We introduce GEAR, a computationally efficient query-tool grounding algorithm that is generalizable to various tasks that require tool use while not relying on task-specific demonstrations. GEAR achieves better efficiency by delegating tool grounding and execution to small language models (SLM) and LLM, respectively; while leveraging semantic and pattern-based evaluation at both question and answer levels for generalizable tool grounding. We evaluate GEAR on 14 datasets across 6 downstream tasks, demonstrating its strong generalizability to novel tasks, tools and different SLMs. Despite offering more efficiency, GEAR achieves higher precision in tool grounding compared to prior strategies using LLM prompting, thus improving downstream accuracy at a reduced computational cost. For example, we demonstrate that GEAR-augmented GPT-J and GPT-3 outperform counterpart tool-augmented baselines because of better tool use.
"According to ..." Prompting Language Models Improves Quoting from Pre-Training Data
May 22, 2023Large Language Models (LLMs) may hallucinate and generate fake information, despite pre-training on factual data. Inspired by the journalistic device of "according to sources", we propose according-to prompting: directing LLMs to ground responses against previously observed text. To quantify this grounding, we propose a novel evaluation metric (QUIP-Score) that measures the extent to which model-produced answers are directly found in underlying text corpora. We illustrate with experiments on Wikipedia that these prompts improve grounding under our metrics, with the additional benefit of often improving end-task performance. Furthermore, prompts that ask the model to decrease grounding (or to ground to other corpora) decrease grounding, indicating the ability of language models to increase or decrease grounded generations on request.
Flatness-Aware Prompt Selection Improves Accuracy and Sample Efficiency
May 18, 2023



With growing capabilities of large language models, prompting them has become the dominant way to access them. This has motivated the development of strategies for automatically selecting effective language prompts. In this paper, we introduce prompt flatness, a new metric to quantify the expected utility of a language prompt. This metric is inspired by flatness regularization in statistical learning that quantifies the robustness of the model towards its parameter perturbations. We provide theoretical foundations for this metric and its relationship with other prompt selection metrics, providing a comprehensive understanding of existing methods. Empirically, we show that combining prompt flatness with existing metrics improves both performance and sample efficiency. Our metric outperforms the previous prompt selection metrics with an average increase of 5% in accuracy and 10% in Pearson correlation across 6 classification benchmarks.
When Not to Trust Language Models: Investigating Effectiveness and Limitations of Parametric and Non-Parametric Memories
Dec 20, 2022Despite their impressive performance on diverse tasks, large language models (LMs) still struggle with tasks requiring rich world knowledge, implying the limitations of relying solely on their parameters to encode a wealth of world knowledge. This paper aims to understand LMs' strengths and limitations in memorizing factual knowledge, by conducting large-scale knowledge probing experiments of 10 models and 4 augmentation methods on PopQA, our new open-domain QA dataset with 14k questions. We find that LMs struggle with less popular factual knowledge, and that scaling fails to appreciably improve memorization of factual knowledge in the tail. We then show that retrieval-augmented LMs largely outperform orders of magnitude larger LMs, while unassisted LMs remain competitive in questions about high-popularity entities. Based on those findings, we devise a simple, yet effective, method for powerful and efficient retrieval-augmented LMs, which retrieves non-parametric memories only when necessary. Experimental results show that this significantly improves models' performance while reducing the inference costs.
Self-Instruct: Aligning Language Model with Self Generated Instructions
Dec 20, 2022Large "instruction-tuned" language models (finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is limited in quantity, diversity, and creativity, therefore hindering the generality of the tuned model. We introduce Self-Instruct, a framework for improving the instruction-following capabilities of pretrained language models by bootstrapping off its own generations. Our pipeline generates instruction, input, and output samples from a language model, then prunes them before using them to finetune the original model. Applying our method to vanilla GPT3, we demonstrate a 33% absolute improvement over the original model on Super-NaturalInstructions, on par with the performance of InstructGPT_001, which is trained with private user data and human annotations. For further evaluation, we curate a set of expert-written instructions for novel tasks, and show through human evaluation that tuning GPT3 with Self-Instruct outperforms using existing public instruction datasets by a large margin, leaving only a 5% absolute gap behind InstructGPT_001. Self-Instruct provides an almost annotation-free method for aligning pre-trained language models with instructions, and we release our large synthetic dataset to facilitate future studies on instruction tuning.
Generating Sequences by Learning to Self-Correct
Oct 31, 2022Sequence generation applications require satisfying semantic constraints, such as ensuring that programs are correct, using certain keywords, or avoiding undesirable content. Language models, whether fine-tuned or prompted with few-shot demonstrations, frequently violate these constraints, and lack a mechanism to iteratively revise their outputs. Moreover, some powerful language models are of extreme scale or inaccessible, making it inefficient, if not infeasible, to update their parameters for task-specific adaptation. We present Self-Correction, an approach that decouples an imperfect base generator (an off-the-shelf language model or supervised sequence-to-sequence model) from a separate corrector that learns to iteratively correct imperfect generations. To train the corrector, we propose an online training procedure that can use either scalar or natural language feedback on intermediate imperfect generations. We show that Self-Correction improves upon the base generator in three diverse generation tasks - mathematical program synthesis, lexically-constrained generation, and toxicity control - even when the corrector is much smaller than the base generator.
The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks
Oct 18, 2022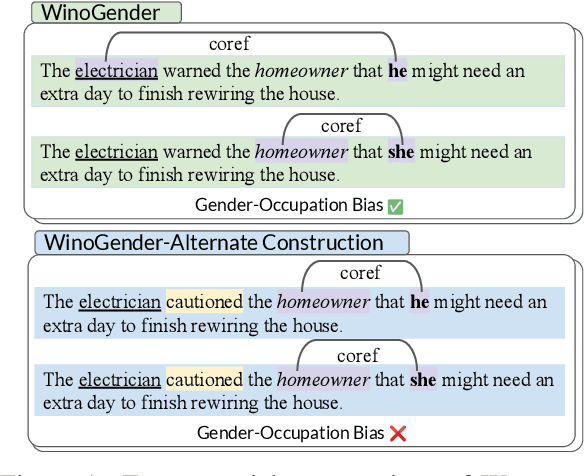
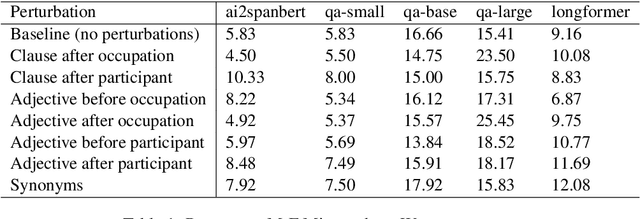


How reliably can we trust the scores obtained from social bias benchmarks as faithful indicators of problematic social biases in a given language model? In this work, we study this question by contrasting social biases with non-social biases stemming from choices made during dataset construction that might not even be discernible to the human eye. To do so, we empirically simulate various alternative constructions for a given benchmark based on innocuous modifications (such as paraphrasing or random-sampling) that maintain the essence of their social bias. On two well-known social bias benchmarks (Winogender and BiasNLI) we observe that these shallow modifications have a surprising effect on the resulting degree of bias across various models. We hope these troubling observations motivate more robust measures of social biases.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.