 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit and Merge: Aligning Position Biases in Large Language Model based Evaluators
Oct 09, 2023



Large language models (LLMs) have shown promise as automated evaluators for assessing the quality of answers generated by AI systems. However, these LLM-based evaluators exhibit position bias, or inconsistency, when used to evaluate candidate answers in pairwise comparisons, favoring either the first or second answer regardless of content. To address this limitation, we propose PORTIA, an alignment-based system designed to mimic human comparison strategies to calibrate position bias in a lightweight yet effective manner. Specifically, PORTIA splits the answers into multiple segments, aligns similar content across candidate answers, and then merges them back into a single prompt for evaluation by LLMs. We conducted extensive experiments with six diverse LLMs to evaluate 11,520 answer pairs. Our results show that PORTIA markedly enhances the consistency rates for all the models and comparison forms tested, achieving an average relative improvement of 47.46%. Remarkably, PORTIA enables less advanced GPT models to achieve 88% agreement with the state-of-the-art GPT-4 model at just 10% of the cost. Furthermore, it rectifies around 80% of the position bias instances within the GPT-4 model, elevating its consistency rate up to 98%. Subsequent human evaluations indicate that the PORTIA-enhanced GPT-3.5 model can even surpass the standalone GPT-4 in terms of alignment with human evaluators. These findings highlight PORTIA's ability to correct position bias, improve LLM consistency, and boost performance while keeping cost-efficiency. This represents a valuable step toward a more reliable and scalable use of LLMs for automated evaluations across diverse applications.
When Less is Enough: Positive and Unlabeled Learning Model for Vulnerability Detection
Aug 21, 2023



Automated code vulnerability detection has gained increasing attention in recent years. The deep learning (DL)-based methods, which implicitly learn vulnerable code patterns, have proven effective in vulnerability detection. The performance of DL-based methods usually relies on the quantity and quality of labeled data. However, the current labeled data are generally automatically collected, such as crawled from human-generated commits, making it hard to ensure the quality of the labels. Prior studies have demonstrated that the non-vulnerable code (i.e., negative labels) tends to be unreliable in commonly-used datasets, while vulnerable code (i.e., positive labels) is more determined. Considering the large numbers of unlabeled data in practice, it is necessary and worth exploring to leverage the positive data and large numbers of unlabeled data for more accurate vulnerability detection. In this paper, we focus on the Positive and Unlabeled (PU) learning problem for vulnerability detection and propose a novel model named PILOT, i.e., PositIve and unlabeled Learning mOdel for vulnerability deTection. PILOT only learns from positive and unlabeled data for vulnerability detection. It mainly contains two modules: (1) A distance-aware label selection module, aiming at generating pseudo-labels for selected unlabeled data, which involves the inter-class distance prototype and progressive fine-tuning; (2) A mixed-supervision representation learning module to further alleviate the influence of noise and enhance the discrimination of representations.
LIVABLE: Exploring Long-Tailed Classification of Software Vulnerability Types
Jun 12, 2023



Prior studies generally focus on software vulnerability detection and have demonstrated the effectiveness of Graph Neural Network (GNN)-based approaches for the task. Considering the various types of software vulnerabilities and the associated different degrees of severity, it is also beneficial to determine the type of each vulnerable code for developers. In this paper, we observe that the distribution of vulnerability type is long-tailed in practice, where a small portion of classes have massive samples (i.e., head classes) but the others contain only a few samples (i.e., tail classes). Directly adopting previous vulnerability detection approaches tends to result in poor detection performance, mainly due to two reasons. First, it is difficult to effectively learn the vulnerability representation due to the over-smoothing issue of GNNs. Second, vulnerability types in tails are hard to be predicted due to the extremely few associated samples.To alleviate these issues, we propose a Long-taIled software VulnerABiLity typE classification approach, called LIVABLE. LIVABLE mainly consists of two modules, including (1) vulnerability representation learning module, which improves the propagation steps in GNN to distinguish node representations by a differentiated propagation method. A sequence-to-sequence model is also involved to enhance the vulnerability representations. (2) adaptive re-weighting module, which adjusts the learning weights for different types according to the training epochs and numbers of associated samples by a novel training loss.
MultiCoder: Multi-Programming-Lingual Pre-Training for Low-Resource Code Completion
Dec 19, 2022Code completion is a valuable topic in both academia and industry. Recently, large-scale mono-programming-lingual (MonoPL) pre-training models have been proposed to boost the performance of code completion. However, the code completion on low-resource programming languages (PL) is difficult for the data-driven paradigm, while there are plenty of developers using low-resource PLs. On the other hand, there are few studies exploring the effects of multi-programming-lingual (MultiPL) pre-training for the code completion, especially the impact on low-resource programming languages. To this end, we propose the MultiCoder to enhance the low-resource code completion via MultiPL pre-training and MultiPL Mixture-of-Experts (MoE) layers. We further propose a novel PL-level MoE routing strategy (PL-MoE) for improving the code completion on all PLs. Experimental results on CodeXGLUE and MultiCC demonstrate that 1) the proposed MultiCoder significantly outperforms the MonoPL baselines on low-resource programming languages, and 2) the PL-MoE module further boosts the performance on six programming languages. In addition, we analyze the effects of the proposed method in details and explore the effectiveness of our method in a variety of scenarios.
A Survey on Natural Language Processing for Programming
Dec 12, 2022Natural language processing for programming, which aims to use NLP techniques to assist programming, has experienced an explosion in recent years. However, there is no literature that systematically reviews related work from the full spectrum. In this paper, we comprehensively investigate existing work, ranging from early deductive models to the latest competition-level models. Another advantage of this paper is the completeness of the technique category, which provides easy access to locating and comparing future works.
Syntax-Guided Domain Adaptation for Aspect-based Sentiment Analysis
Nov 10, 2022



Aspect-based sentiment analysis (ABSA) aims at extracting opinionated aspect terms in review texts and determining their sentiment polarities, which is widely studied in both academia and industry. As a fine-grained classification task, the annotation cost is extremely high. Domain adaptation is a popular solution to alleviate the data deficiency issue in new domains by transferring common knowledge across domains. Most cross-domain ABSA studies are based on structure correspondence learning (SCL), and use pivot features to construct auxiliary tasks for narrowing down the gap between domains. However, their pivot-based auxiliary tasks can only transfer knowledge of aspect terms but not sentiment, limiting the performance of existing models. In this work, we propose a novel Syntax-guided Domain Adaptation Model, named SDAM, for more effective cross-domain ABSA. SDAM exploits syntactic structure similarities for building pseudo training instances, during which aspect terms of target domain are explicitly related to sentiment polarities. Besides, we propose a syntax-based BERT mask language model for further capturing domain-invariant features. Finally, to alleviate the sentiment inconsistency issue in multi-gram aspect terms, we introduce a span-based joint aspect term and sentiment analysis module into the cross-domain End2End ABSA. Experiments on five benchmark datasets show that our model consistently outperforms the state-of-the-art baselines with respect to Micro-F1 metric for the cross-domain End2End ABSA task.
Once is Enough: A Light-Weight Cross-Attention for Fast Sentence Pair Modeling
Oct 11, 2022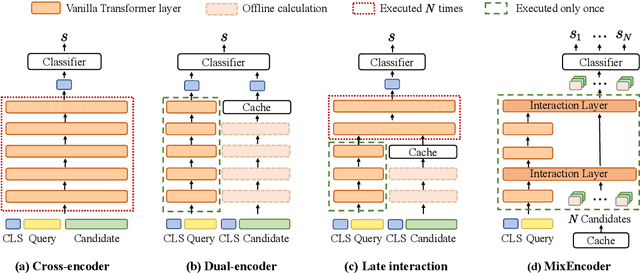

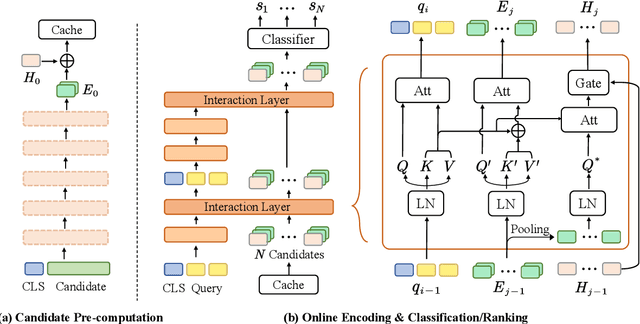
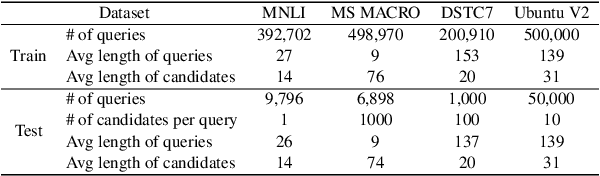
Transformer-based models have achieved great success on sentence pair modeling tasks, such as answer selection and natural language inference (NLI). These models generally perform cross-attention over input pairs, leading to prohibitive computational costs. Recent studies propose dual-encoder and late interaction architectures for faster computation. However, the balance between the expressive of cross-attention and computation speedup still needs better coordinated. To this end, this paper introduces a novel paradigm MixEncoder for efficient sentence pair modeling. MixEncoder involves a light-weight cross-attention mechanism. It conducts query encoding only once while modeling the query-candidate interaction in parallel. Extensive experiments conducted on four tasks demonstrate that our MixEncoder can speed up sentence pairing by over 113x while achieving comparable performance as the more expensive cross-attention models.
Knowledge-aware Neural Networks with Personalized Feature Referencing for Cold-start Recommendation
Sep 28, 2022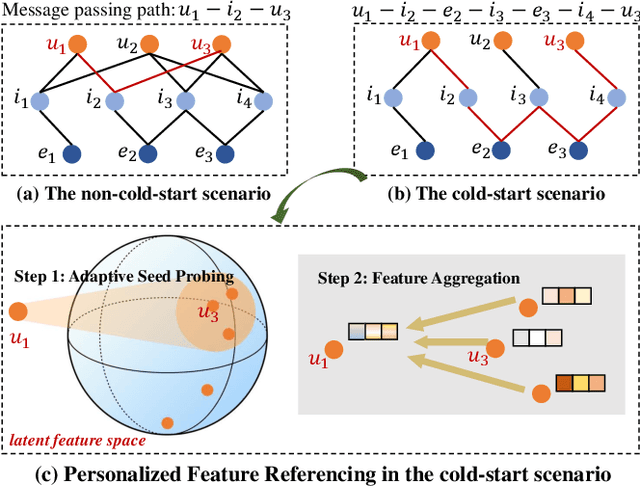
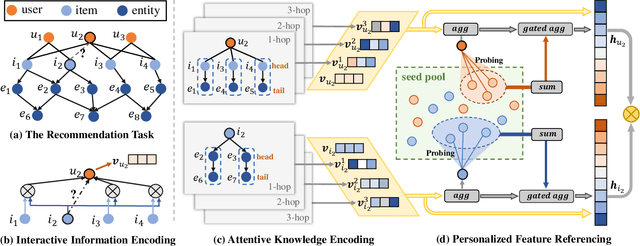
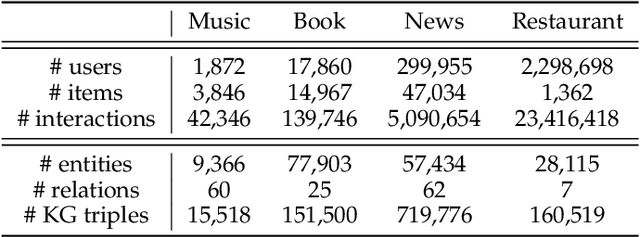
Incorporating knowledge graphs (KGs) as side information in recommendation has recently attracted considerable attention. Despite the success in general recommendation scenarios, prior methods may fall short of performance satisfaction for the cold-start problem in which users are associated with very limited interactive information. Since the conventional methods rely on exploring the interaction topology, they may however fail to capture sufficient information in cold-start scenarios. To mitigate the problem, we propose a novel Knowledge-aware Neural Networks with Personalized Feature Referencing Mechanism, namely KPER. Different from most prior methods which simply enrich the targets' semantics from KGs, e.g., product attributes, KPER utilizes the KGs as a "semantic bridge" to extract feature references for cold-start users or items. Specifically, given cold-start targets, KPER first probes semantically relevant but not necessarily structurally close users or items as adaptive seeds for referencing features. Then a Gated Information Aggregation module is introduced to learn the combinatorial latent features for cold-start users and items. Our extensive experiments over four real-world datasets show that, KPER consistently outperforms all competing methods in cold-start scenarios, whilst maintaining superiority in general scenarios without compromising overall performance, e.g., by achieving 0.81%-16.08% and 1.01%-14.49% performance improvement across all datasets in Top-10 recommendation.
No More Fine-Tuning? An Experimental Evaluation of Prompt Tuning in Code Intelligence
Jul 24, 2022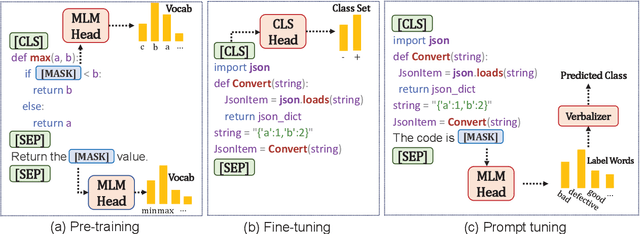
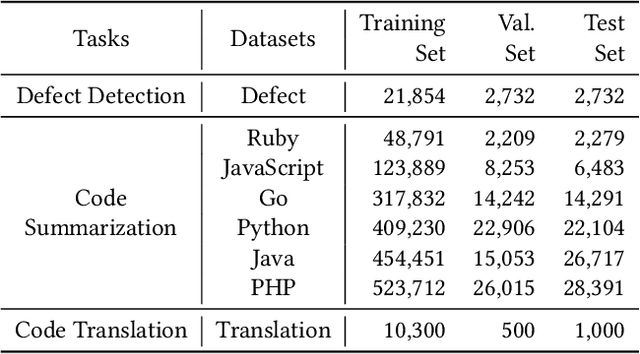
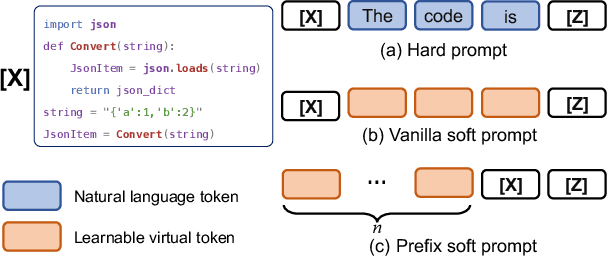
Pre-trained models have been shown effective in many code intelligence tasks. These models are pre-trained on large-scale unlabeled corpus and then fine-tuned in downstream tasks. However, as the inputs to pre-training and downstream tasks are in different forms, it is hard to fully explore the knowledge of pre-trained models. Besides, the performance of fine-tuning strongly relies on the amount of downstream data, while in practice, the scenarios with scarce data are common. Recent studies in the natural language processing (NLP) field show that prompt tuning, a new paradigm for tuning, alleviates the above issues and achieves promising results in various NLP tasks. In prompt tuning, the prompts inserted during tuning provide task-specific knowledge, which is especially beneficial for tasks with relatively scarce data. In this paper, we empirically evaluate the usage and effect of prompt tuning in code intelligence tasks. We conduct prompt tuning on popular pre-trained models CodeBERT and CodeT5 and experiment with three code intelligence tasks including defect prediction, code summarization, and code translation. Our experimental results show that prompt tuning consistently outperforms fine-tuning in all three tasks. In addition, prompt tuning shows great potential in low-resource scenarios, e.g., improving the BLEU scores of fine-tuning by more than 26\% on average for code summarization. Our results suggest that instead of fine-tuning, we could adapt prompt tuning for code intelligence tasks to achieve better performance, especially when lacking task-specific data.
Review-Based Tip Generation for Music Songs
May 14, 2022

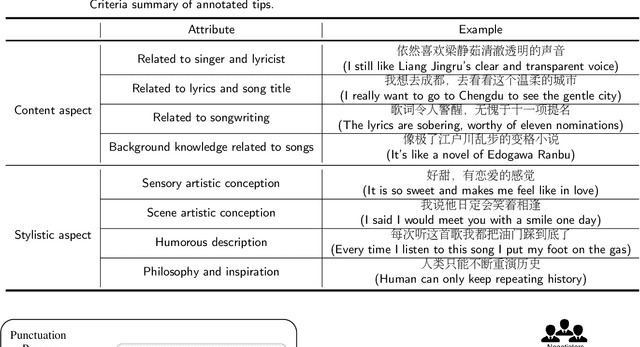
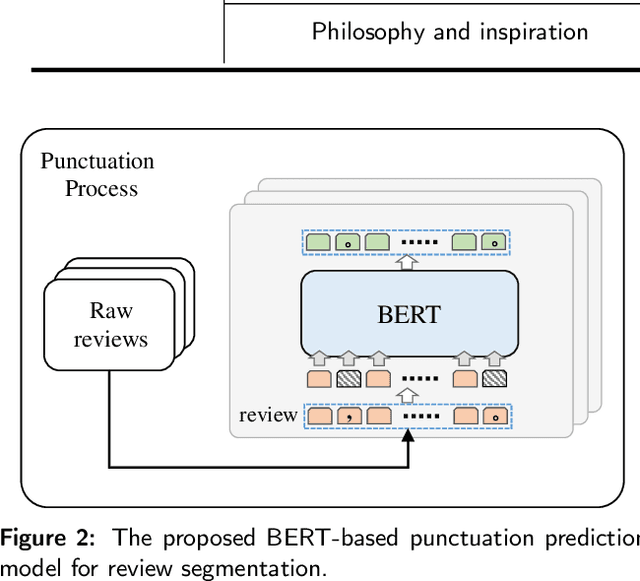
Reviews of songs play an important role in online music service platforms. Prior research shows that users can make quicker and more informed decisions when presented with meaningful song reviews. However, reviews of music songs are generally long in length and most of them are non-informative for users. It is difficult for users to efficiently grasp meaningful messages for making decisions. To solve this problem, one practical strategy is to provide tips, i.e., short, concise, empathetic, and self-contained descriptions about songs. Tips are produced from song reviews and should express non-trivial insight about the songs. To the best of our knowledge, no prior studies have explored the tip generation task in music domain. In this paper, we create a dataset named MTips for the task and propose a framework named GenTMS for automatically generating tips from song reviews. The dataset involves 8,003 Chinese tips/non-tips from 128 songs which are distributed in five different song genres. Experimental results show that GenTMS achieves top-10 precision at 85.56%, outperforming the baseline models by at least 3.34%. Besides, to simulate the practical usage of our proposed framework, we also experiment with previously-unseen songs, during which GenTMS also achieves the best performance with top-10 precision at 78.89% on average. The results demonstrate the effectiveness of the proposed framework in tip generation of the music domain.