 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mixture Density via Natural Gradient Expectation Maximization
Feb 11, 2026Mixture density networks are neural networks that produce Gaussian mixtures to represent continuous multimodal conditional densities. Standard training procedures involve maximum likelihood estimation using the negative log-likelihood (NLL) objective, which suffers from slow convergence and mode collapse. In this work, we improve the optimization of mixture density networks by integrating their information geometry. Specifically, we interpret mixture density networks as deep latent-variable models and analyze them through an expectation maximization framework, which reveals surprising theoretical connections to natural gradient descent. We then exploit such connections to derive the natural gradient expectation maximization (nGEM) objective. We show that empirically nGEM achieves up to 10$\times$ faster convergence while adding almost zerocomputational overhead, and scales well to high-dimensional data where NLL otherwise fails.
CreatiDesign: A Unified Multi-Conditional Diffusion Transformer for Creative Graphic Design
May 25, 2025Graphic design plays a vital role in visual communication across advertising, marketing, and multimedia entertainment. Prior work has explored automated graphic design generation using diffusion models, aiming to streamline creative workflows and democratize design capabilities. However, complex graphic design scenarios require accurately adhering to design intent specified by multiple heterogeneous user-provided elements (\eg images, layouts, and texts), which pose multi-condition control challenges for existing methods. Specifically, previous single-condition control models demonstrate effectiveness only within their specialized domains but fail to generalize to other conditions, while existing multi-condition methods often lack fine-grained control over each sub-condition and compromise overall compositional harmony. To address these limitations, we introduce CreatiDesign, a systematic solution for automated graphic design covering both model architecture and dataset construction. First, we design a unified multi-condition driven architecture that enables flexible and precise integration of heterogeneous design elements with minimal architectural modifications to the base diffusion model. Furthermore, to ensure that each condition precisely controls its designated image region and to avoid interference between conditions, we propose a multimodal attention mask mechanism. Additionally, we develop a fully automated pipeline for constructing graphic design datasets, and introduce a new dataset with 400K samples featuring multi-condition annotations, along with a comprehensive benchmark. Experimental results show that CreatiDesign outperforms existing models by a clear margin in faithfully adhering to user intent.
EVE: Efficient zero-shot text-based Video Editing with Depth Map Guidance and Temporal Consistency Constraints
Aug 21, 2023



Motivated by the superior performance of image diffusion models, more and more researchers strive to extend these models to the text-based video editing task. Nevertheless, current video editing tasks mainly suffer from the dilemma between the high fine-tuning cost and the limited generation capacity. Compared with images, we conjecture that videos necessitate more constraints to preserve the temporal consistency during editing. Towards this end, we propose EVE, a robust and efficient zero-shot video editing method. Under the guidance of depth maps and temporal consistency constraints, EVE derives satisfactory video editing results with an affordable computational and time cost. Moreover, recognizing the absence of a publicly available video editing dataset for fair comparisons, we construct a new benchmark ZVE-50 dataset. Through comprehensive experimentation, we validate that EVE could achieve a satisfactory trade-off between performance and efficiency. We will release our dataset and codebase to facilitate future researchers.
CelebHair: A New Large-Scale Dataset for Hairstyle Recommendation based on CelebA
Apr 14, 2021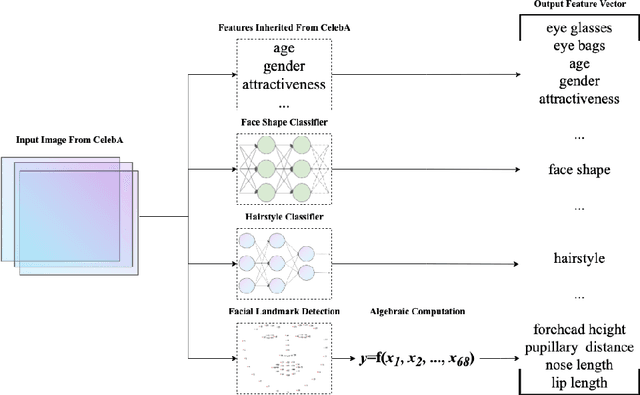


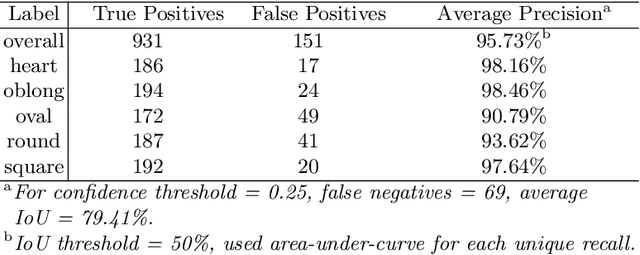
In this paper, we present a new large-scale dataset for hairstyle recommendation, CelebHair, based on the celebrity facial attributes dataset, CelebA. Our dataset inherited the majority of facial images along with some beauty-related facial attributes from CelebA. Additionally, we employed facial landmark detection techniques to extract extra features such as nose length and pupillary distance, and deep convolutional neural networks for face shape and hairstyle classification. Empirical comparison has demonstrated the superiority of our dataset to other existing hairstyle-related datasets regarding variety, veracity, and volume. Analysis and experiments have been conducted on the dataset in order to evaluate its robustness and usability.
Different Approaches Towards Vertical Track Irregularity Prediction -- A Comparative Study
Dec 05, 2020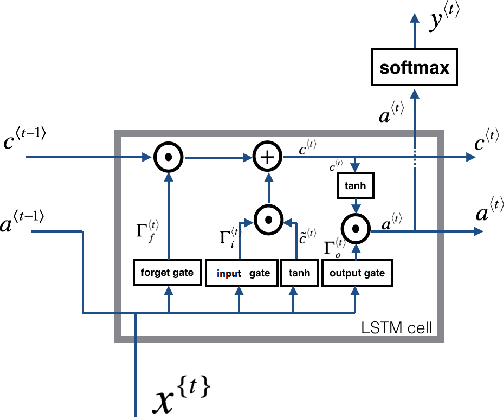
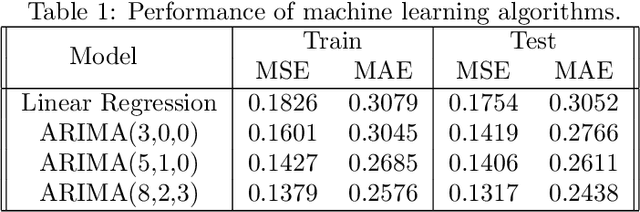
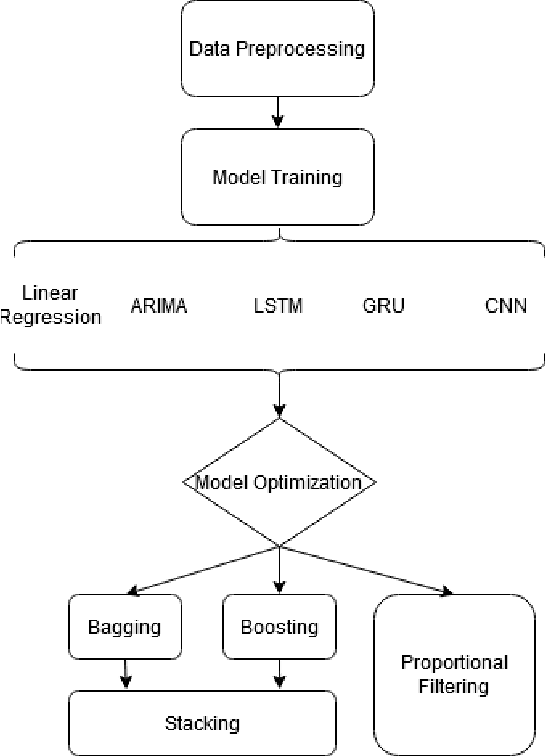
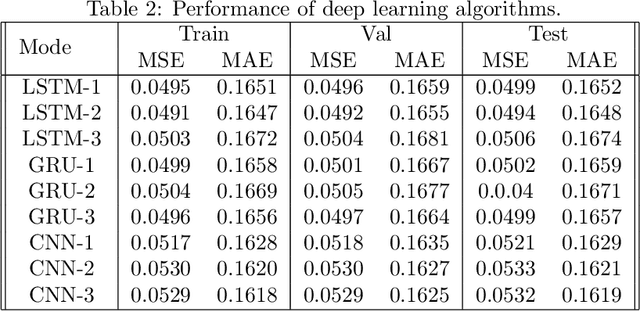
Railway systems require regular manual maintenance, a large part of which is dedicated to track deformation inspection. Such deformation might severely impact trains' runtime security, whereas such inspections remain costly as for both finance and manpower. Therefore, a more precise, efficient and automated approach to detect potential railway track deformation is in urgent needs. In this paper, we proposed an applicational framework for predicting vertical track irregularities. Our researches are based on large-scale real-world datasets produced by several operating railways in China. We explored several different sampling methods and compared traditional machine learning algorithms for time-series prediction with popular deep learning techniques. Different ensemble learning methods are also employed for further optimization. The conclusion is reached that neural networks turn out to be the most performant and accurate.