 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025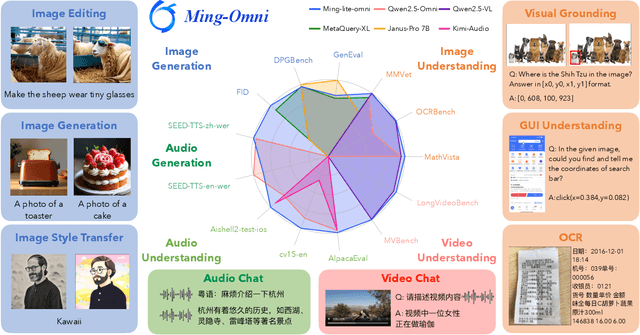
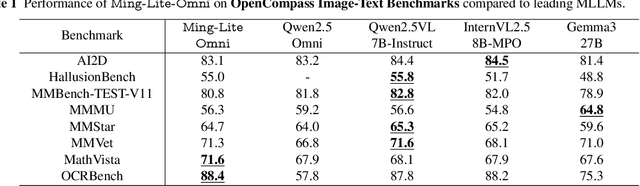
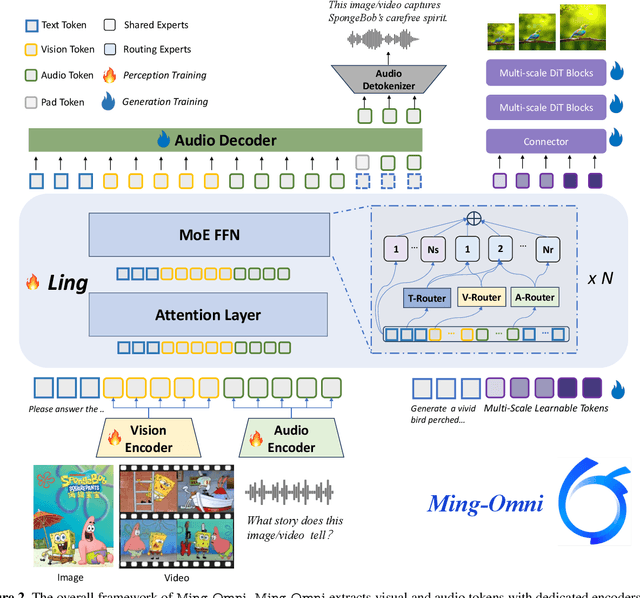
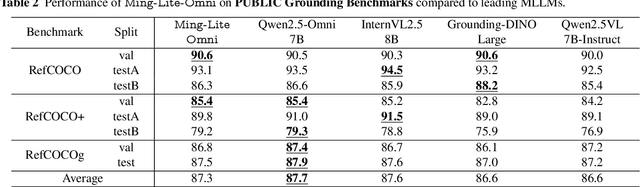
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
SHE-Net: Syntax-Hierarchy-Enhanced Text-Video Retrieval
Apr 22, 2024The user base of short video apps has experienced unprecedented growth in recent years, resulting in a significant demand for video content analysis. In particular, text-video retrieval, which aims to find the top matching videos given text descriptions from a vast video corpus, is an essential function, the primary challenge of which is to bridge the modality gap. Nevertheless, most existing approaches treat texts merely as discrete tokens and neglect their syntax structures. Moreover, the abundant spatial and temporal clues in videos are often underutilized due to the lack of interaction with text. To address these issues, we argue that using texts as guidance to focus on relevant temporal frames and spatial regions within videos is beneficial. In this paper, we propose a novel Syntax-Hierarchy-Enhanced text-video retrieval method (SHE-Net) that exploits the inherent semantic and syntax hierarchy of texts to bridge the modality gap from two perspectives. First, to facilitate a more fine-grained integration of visual content, we employ the text syntax hierarchy, which reveals the grammatical structure of text descriptions, to guide the visual representations. Second, to further enhance the multi-modal interaction and alignment, we also utilize the syntax hierarchy to guide the similarity calculation. We evaluated our method on four public text-video retrieval datasets of MSR-VTT, MSVD, DiDeMo, and ActivityNet. The experimental results and ablation studies confirm the advantages of our proposed method.
SNP-S3: Shared Network Pre-training and Significant Semantic Strengthening for Various Video-Text Tasks
Jan 31, 2024We present a framework for learning cross-modal video representations by directly pre-training on raw data to facilitate various downstream video-text tasks. Our main contributions lie in the pre-training framework and proxy tasks. First, based on the shortcomings of two mainstream pixel-level pre-training architectures (limited applications or less efficient), we propose Shared Network Pre-training (SNP). By employing one shared BERT-type network to refine textual and cross-modal features simultaneously, SNP is lightweight and could support various downstream applications. Second, based on the intuition that people always pay attention to several "significant words" when understanding a sentence, we propose the Significant Semantic Strengthening (S3) strategy, which includes a novel masking and matching proxy task to promote the pre-training performance. Experiments conducted on three downstream video-text tasks and six datasets demonstrate that, we establish a new state-of-the-art in pixel-level video-text pre-training; we also achieve a satisfactory balance between the pre-training efficiency and the fine-tuning performance. The codebase are available at https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/snps3_vtp.
M2-RAAP: A Multi-Modal Recipe for Advancing Adaptation-based Pre-training towards Effective and Efficient Zero-shot Video-text Retrieval
Jan 31, 2024



We present a Multi-Modal Recipe for Advancing Adaptation-based Pre-training towards effective and efficient zero-shot video-text retrieval, dubbed M2-RAAP. Upon popular image-text models like CLIP, most current adaptation-based video-text pre-training methods are confronted by three major issues, i.e., noisy data corpus, time-consuming pre-training, and limited performance gain. Towards this end, we conduct a comprehensive study including four critical steps in video-text pre-training. Specifically, we investigate 1) data filtering and refinement, 2) video input type selection, 3) temporal modeling, and 4) video feature enhancement. We then summarize this empirical study into the M2-RAAP recipe, where our technical contributions lie in 1) the data filtering and text re-writing pipeline resulting in 1M high-quality bilingual video-text pairs, 2) the replacement of video inputs with key-frames to accelerate pre-training, and 3) the Auxiliary-Caption-Guided (ACG) strategy to enhance video features. We conduct extensive experiments by adapting three image-text foundation models on two refined video-text datasets from different languages, validating the robustness and reproducibility of M2-RAAP for adaptation-based pre-training. Results demonstrate that M2-RAAP yields superior performance with significantly reduced data (-90%) and time consumption (-95%), establishing a new SOTA on four English zero-shot retrieval datasets and two Chinese ones. We are preparing our refined bilingual data annotations and codebase, which will be available at https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/M2_RAAP.
EVE: Efficient zero-shot text-based Video Editing with Depth Map Guidance and Temporal Consistency Constraints
Aug 21, 2023



Motivated by the superior performance of image diffusion models, more and more researchers strive to extend these models to the text-based video editing task. Nevertheless, current video editing tasks mainly suffer from the dilemma between the high fine-tuning cost and the limited generation capacity. Compared with images, we conjecture that videos necessitate more constraints to preserve the temporal consistency during editing. Towards this end, we propose EVE, a robust and efficient zero-shot video editing method. Under the guidance of depth maps and temporal consistency constraints, EVE derives satisfactory video editing results with an affordable computational and time cost. Moreover, recognizing the absence of a publicly available video editing dataset for fair comparisons, we construct a new benchmark ZVE-50 dataset. Through comprehensive experimentation, we validate that EVE could achieve a satisfactory trade-off between performance and efficiency. We will release our dataset and codebase to facilitate future researchers.
Stacked Hybrid-Attention and Group Collaborative Learning for Unbiased Scene Graph Generation
Apr 02, 2022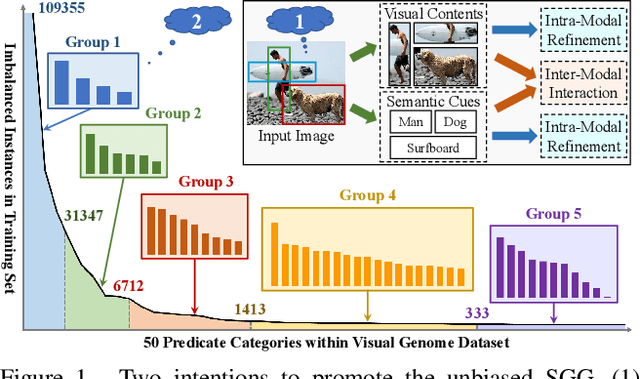
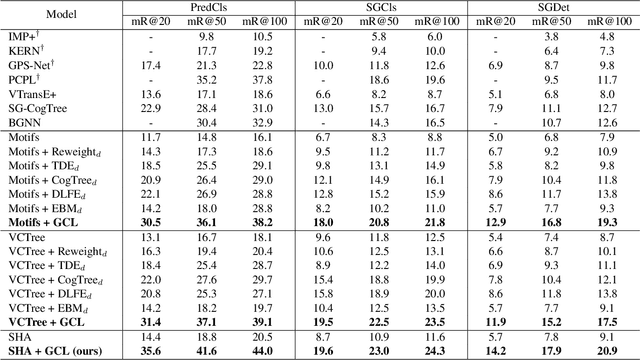
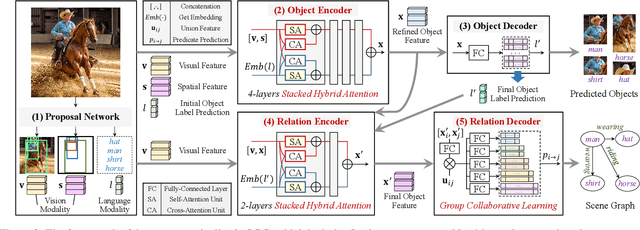
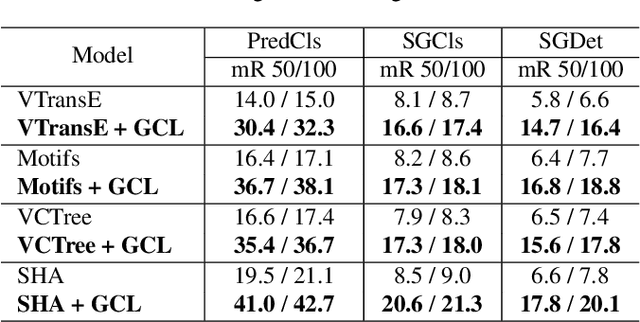
Scene Graph Generation, which generally follows a regular encoder-decoder pipeline, aims to first encode the visual contents within the given image and then parse them into a compact summary graph. Existing SGG approaches generally not only neglect the insufficient modality fusion between vision and language, but also fail to provide informative predicates due to the biased relationship predictions, leading SGG far from practical. Towards this end, in this paper, we first present a novel Stacked Hybrid-Attention network, which facilitates the intra-modal refinement as well as the inter-modal interaction, to serve as the encoder. We then devise an innovative Group Collaborative Learning strategy to optimize the decoder. Particularly, based upon the observation that the recognition capability of one classifier is limited towards an extremely unbalanced dataset, we first deploy a group of classifiers that are expert in distinguishing different subsets of classes, and then cooperatively optimize them from two aspects to promote the unbiased SGG. Experiments conducted on VG and GQA datasets demonstrate that, we not only establish a new state-of-the-art in the unbiased metric, but also nearly double the performance compared with two baselines.