 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Adaptation of 3D Geometric Foundation Models via Weak Supervision from Internet Video
Feb 08, 2026Geometric foundation models show promise in 3D reconstruction, yet their progress is severely constrained by the scarcity of diverse, large-scale 3D annotations. While Internet videos offer virtually unlimited raw data, utilizing them as a scaling source for geometric learning is challenging due to the absence of ground-truth geometry and the presence of observational noise. To address this, we propose SAGE, a framework for Scalable Adaptation of GEometric foundation models from raw video streams. SAGE leverages a hierarchical mining pipeline to transform videos into training trajectories and hybrid supervision: (1) Informative training trajectory selection; (2) Sparse Geometric Anchoring via SfM point clouds for global structural guidance; and (3) Dense Differentiable Consistency via 3D Gaussian rendering for multi-view constraints. To prevent catastrophic forgetting, we introduce a regularization strategy using anchor data. Extensive experiments show that SAGE significantly enhances zero-shot generalization, reducing Chamfer Distance by 20-42% on unseen benchmarks (7Scenes, TUM-RGBD, Matterport3D) compared to state-of-the-art baselines. To our knowledge, SAGE pioneers the adaptation of geometric foundation models via Internet video, establishing a scalable paradigm for general-purpose 3D learning.
PIO-FVLM: Rethinking Training-Free Visual Token Reduction for VLM Acceleration from an Inference-Objective Perspective
Feb 05, 2026Recently, reducing redundant visual tokens in vision-language models (VLMs) to accelerate VLM inference has emerged as a hot topic. However, most existing methods rely on heuristics constructed based on inter-visual-token similarity or cross-modal visual-text similarity, which gives rise to certain limitations in compression performance and practical deployment. In contrast, we propose PIO-FVLM from the perspective of inference objectives, which transforms visual token compression into preserving output result invariance and selects tokens primarily by their importance to this goal. Specially, vision tokens are reordered with the guidance of token-level gradient saliency generated by our designed layer-local proxy loss, a coarse constraint from the current layer to the final result. Then the most valuable vision tokens are selected following the non-maximum suppression (NMS) principle. The proposed PIO-FVLM is training-free and compatible with FlashAttention, friendly to practical application and deployment. It can be deployed independently as an encoder-free method, or combined with encoder compression approaches like VisionZip for use as an encoder-involved method. On LLaVA-Next-7B, PIO-FVLM retains just 11.1% of visual tokens but maintains 97.2% of the original performance, with a 2.67$\times$ prefill speedup, 2.11$\times$ inference speedup, 6.22$\times$ lower FLOPs, and 6.05$\times$ reduced KV Cache overhead. Our code is available at https://github.com/ocy1/PIO-FVLM.
AGILE: Hand-Object Interaction Reconstruction from Video via Agentic Generation
Feb 04, 2026Reconstructing dynamic hand-object interactions from monocular videos is critical for dexterous manipulation data collection and creating realistic digital twins for robotics and VR. However, current methods face two prohibitive barriers: (1) reliance on neural rendering often yields fragmented, non-simulation-ready geometries under heavy occlusion, and (2) dependence on brittle Structure-from-Motion (SfM) initialization leads to frequent failures on in-the-wild footage. To overcome these limitations, we introduce AGILE, a robust framework that shifts the paradigm from reconstruction to agentic generation for interaction learning. First, we employ an agentic pipeline where a Vision-Language Model (VLM) guides a generative model to synthesize a complete, watertight object mesh with high-fidelity texture, independent of video occlusions. Second, bypassing fragile SfM entirely, we propose a robust anchor-and-track strategy. We initialize the object pose at a single interaction onset frame using a foundation model and propagate it temporally by leveraging the strong visual similarity between our generated asset and video observations. Finally, a contact-aware optimization integrates semantic, geometric, and interaction stability constraints to enforce physical plausibility. Extensive experiments on HO3D, DexYCB, and in-the-wild videos reveal that AGILE outperforms baselines in global geometric accuracy while demonstrating exceptional robustness on challenging sequences where prior art frequently collapses. By prioritizing physical validity, our method produces simulation-ready assets validated via real-to-sim retargeting for robotic applications.
SALAD-Pan: Sensor-Agnostic Latent Adaptive Diffusion for Pan-Sharpening
Feb 04, 2026Recently, diffusion models bring novel insights for Pan-sharpening and notably boost fusion precision. However, most existing models perform diffusion in the pixel space and train distinct models for different multispectral (MS) imagery, suffering from high latency and sensor-specific limitations. In this paper, we present SALAD-Pan, a sensor-agnostic latent space diffusion method for efficient pansharpening. Specifically, SALAD-Pan trains a band-wise single-channel VAE to encode high-resolution multispectral (HRMS) into compact latent representations, supporting MS images with various channel counts and establishing a basis for acceleration. Then spectral physical properties, along with PAN and MS images, are injected into the diffusion backbone through unidirectional and bidirectional interactive control structures respectively, achieving high-precision fusion in the diffusion process. Finally, a lightweight cross-spectral attention module is added to the central layer of diffusion model, reinforcing spectral connections to boost spectral consistency and further elevate fusion precision. Experimental results on GaoFen-2, QuickBird, and WorldView-3 demonstrate that SALAD-Pan outperforms state-of-the-art diffusion-based methods across all three datasets, attains a 2-3x inference speedup, and exhibits robust zero-shot (cross-sensor) capability.
Improving Diffusion Language Model Decoding through Joint Search in Generation Order and Token Space
Jan 28, 2026Diffusion Language Models (DLMs) offer order-agnostic generation that can explore many possible decoding trajectories. However, current decoding methods commit to a single trajectory, limiting exploration in trajectory space. We introduce Order-Token Search to explore this space through jointly searching over generation order and token values. Its core is a likelihood estimator that scores denoising actions, enabling stable pruning and efficient exploration of diverse trajectories. Across mathematical reasoning and coding benchmarks, Order-Token Search consistently outperforms baselines on GSM8K, MATH500, Countdown, and HumanEval (3.1%, 3.8%, 7.9%, and 6.8% absolute over backbone), matching or surpassing diffu-GRPO post-trained d1-LLaDA. Our work establishes joint search as a key component for advancing decoding in DLMs.
PhysRVG: Physics-Aware Unified Reinforcement Learning for Video Generative Models
Jan 16, 2026Physical principles are fundamental to realistic visual simulation, but remain a significant oversight in transformer-based video generation. This gap highlights a critical limitation in rendering rigid body motion, a core tenet of classical mechanics. While computer graphics and physics-based simulators can easily model such collisions using Newton formulas, modern pretrain-finetune paradigms discard the concept of object rigidity during pixel-level global denoising. Even perfectly correct mathematical constraints are treated as suboptimal solutions (i.e., conditions) during model optimization in post-training, fundamentally limiting the physical realism of generated videos. Motivated by these considerations, we introduce, for the first time, a physics-aware reinforcement learning paradigm for video generation models that enforces physical collision rules directly in high-dimensional spaces, ensuring the physics knowledge is strictly applied rather than treated as conditions. Subsequently, we extend this paradigm to a unified framework, termed Mimicry-Discovery Cycle (MDcycle), which allows substantial fine-tuning while fully preserving the model's ability to leverage physics-grounded feedback. To validate our approach, we construct new benchmark PhysRVGBench and perform extensive qualitative and quantitative experiments to thoroughly assess its effectiveness.
Beyond Hard Masks: Progressive Token Evolution for Diffusion Language Models
Jan 12, 2026Diffusion Language Models (DLMs) offer a promising alternative for language modeling by enabling parallel decoding through iterative refinement. However, most DLMs rely on hard binary masking and discrete token assignments, which hinder the revision of early decisions and underutilize intermediate probabilistic representations. In this paper, we propose EvoToken-DLM, a novel diffusion-based language modeling approach that replaces hard binary masks with evolving soft token distributions. EvoToken-DLM enables a progressive transition from masked states to discrete outputs, supporting revisable decoding. To effectively support this evolution, we introduce continuous trajectory supervision, which aligns training objectives with iterative probabilistic updates. Extensive experiments across multiple benchmarks show that EvoToken-DLM consistently achieves superior performance, outperforming strong diffusion-based and masked DLM baselines. Project webpage: https://aim-uofa.github.io/EvoTokenDLM.
Preserving Source Video Realism: High-Fidelity Face Swapping for Cinematic Quality
Dec 08, 2025Video face swapping is crucial in film and entertainment production, where achieving high fidelity and temporal consistency over long and complex video sequences remains a significant challenge. Inspired by recent advances in reference-guided image editing, we explore whether rich visual attributes from source videos can be similarly leveraged to enhance both fidelity and temporal coherence in video face swapping. Building on this insight, this work presents LivingSwap, the first video reference guided face swapping model. Our approach employs keyframes as conditioning signals to inject the target identity, enabling flexible and controllable editing. By combining keyframe conditioning with video reference guidance, the model performs temporal stitching to ensure stable identity preservation and high-fidelity reconstruction across long video sequences. To address the scarcity of data for reference-guided training, we construct a paired face-swapping dataset, Face2Face, and further reverse the data pairs to ensure reliable ground-truth supervision. Extensive experiments demonstrate that our method achieves state-of-the-art results, seamlessly integrating the target identity with the source video's expressions, lighting, and motion, while significantly reducing manual effort in production workflows. Project webpage: https://aim-uofa.github.io/LivingSwap
R$^{2}$Seg: Training-Free OOD Medical Tumor Segmentation via Anatomical Reasoning and Statistical Rejection
Nov 16, 2025Foundation models for medical image segmentation struggle under out-of-distribution (OOD) shifts, often producing fragmented false positives on OOD tumors. We introduce R$^{2}$Seg, a training-free framework for robust OOD tumor segmentation that operates via a two-stage Reason-and-Reject process. First, the Reason step employs an LLM-guided anatomical reasoning planner to localize organ anchors and generate multi-scale ROIs. Second, the Reject step applies two-sample statistical testing to candidates generated by a frozen foundation model (BiomedParse) within these ROIs. This statistical rejection filter retains only candidates significantly different from normal tissue, effectively suppressing false positives. Our framework requires no parameter updates, making it compatible with zero-update test-time augmentation and avoiding catastrophic forgetting. On multi-center and multi-modal tumor segmentation benchmarks, R$^{2}$Seg substantially improves Dice, specificity, and sensitivity over strong baselines and the original foundation models. Code are available at https://github.com/Eurekashen/R2Seg.
Evolutionary Profiles for Protein Fitness Prediction
Oct 08, 2025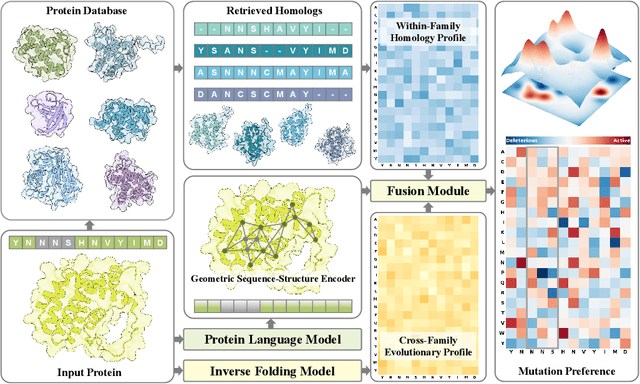
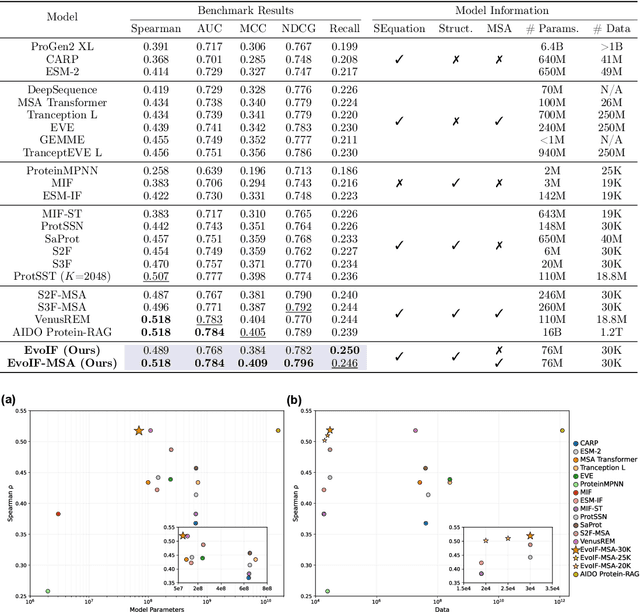
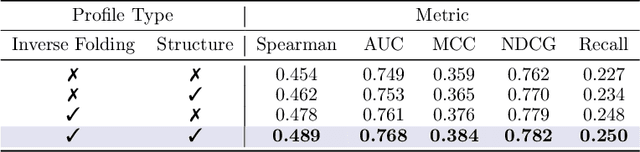
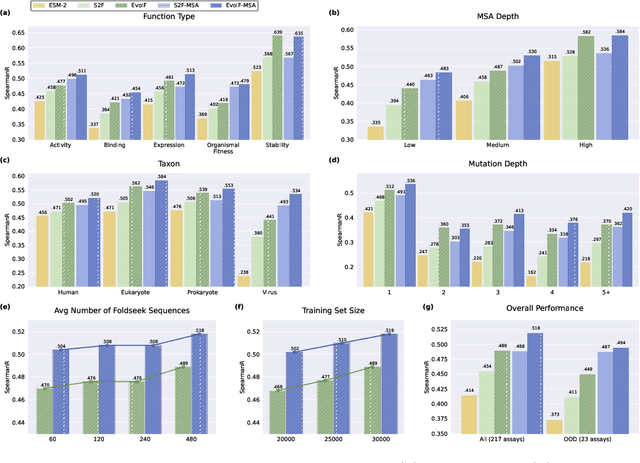
Predicting the fitness impact of mutations is central to protein engineering but constrained by limited assays relative to the size of sequence space. Protein language models (pLMs) trained with masked language modeling (MLM) exhibit strong zero-shot fitness prediction; we provide a unifying view by interpreting natural evolution as implicit reward maximization and MLM as inverse reinforcement learning (IRL), in which extant sequences act as expert demonstrations and pLM log-odds serve as fitness estimates. Building on this perspective, we introduce EvoIF, a lightweight model that integrates two complementary sources of evolutionary signal: (i) within-family profiles from retrieved homologs and (ii) cross-family structural-evolutionary constraints distilled from inverse folding logits. EvoIF fuses sequence-structure representations with these profiles via a compact transition block, yielding calibrated probabilities for log-odds scoring. On ProteinGym (217 mutational assays; >2.5M mutants), EvoIF and its MSA-enabled variant achieve state-of-the-art or competitive performance while using only 0.15% of the training data and fewer parameters than recent large models. Ablations confirm that within-family and cross-family profiles are complementary, improving robustness across function types, MSA depths, taxa, and mutation depths. The codes will be made publicly available at https://github.com/aim-uofa/EvoIF.