 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Robotic Assistant: Completing Collaborative Tasks with Dexterous Vision-Language-Action Models
Oct 29, 2025We adapt a pre-trained Vision-Language-Action (VLA) model (Open-VLA) for dexterous human-robot collaboration with minimal language prompting. Our approach adds (i) FiLM conditioning to visual backbones for task-aware perception, (ii) an auxiliary intent head that predicts collaborator hand pose and target cues, and (iii) action-space post-processing that predicts compact deltas (position/rotation) and PCA-reduced finger joints before mapping to full commands. Using a multi-view, teleoperated Franka and Mimic-hand dataset augmented with MediaPipe hand poses, we demonstrate that delta actions are well-behaved and that four principal components explain ~96% of hand-joint variance. Ablations identify action post-processing as the primary performance driver; auxiliary intent helps, FiLM is mixed, and a directional motion loss is detrimental. A real-time stack (~0.3 s latency on one RTX 4090) composes "pick-up" and "pass" into a long-horizon behavior. We surface "trainer overfitting" to specific demonstrators as the key limitation.
Beyond Anthropomorphism: Enhancing Grasping and Eliminating a Degree of Freedom by Fusing the Abduction of Digits Four and Five
Sep 16, 2025This paper presents the SABD hand, a 16-degree-of-freedom (DoF) robotic hand that departs from purely anthropomorphic designs to achieve an expanded grasp envelope, enable manipulation poses beyond human capability, and reduce the required number of actuators. This is achieved by combining the adduction/abduction (Add/Abd) joint of digits four and five into a single joint with a large range of motion. The combined joint increases the workspace of the digits by 400\% and reduces the required DoFs while retaining dexterity. Experimental results demonstrate that the combined Add/Abd joint enables the hand to grasp objects with a side distance of up to 200 mm. Reinforcement learning-based investigations show that the design enables grasping policies that are effective not only for handling larger objects but also for achieving enhanced grasp stability. In teleoperated trials, the hand successfully performed 86\% of attempted grasps on suitable YCB objects, including challenging non-anthropomorphic configurations. These findings validate the design's ability to enhance grasp stability, flexibility, and dexterous manipulation without added complexity, making it well-suited for a wide range of applications.
Towards Hallucination-Free Music: A Reinforcement Learning Preference Optimization Framework for Reliable Song Generation
Aug 07, 2025Recent advances in audio-based generative language models have accelerated AI-driven lyric-to-song generation. However, these models frequently suffer from content hallucination, producing outputs misaligned with the input lyrics and undermining musical coherence. Current supervised fine-tuning (SFT) approaches, limited by passive label-fitting, exhibit constrained self-improvement and poor hallucination mitigation. To address this core challenge, we propose a novel reinforcement learning (RL) framework leveraging preference optimization for hallucination control. Our key contributions include: (1) Developing a robust hallucination preference dataset constructed via phoneme error rate (PER) computation and rule-based filtering to capture alignment with human expectations; (2) Implementing and evaluating three distinct preference optimization strategies within the RL framework: Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and Group Relative Policy Optimization (GRPO). DPO operates off-policy to enhance positive token likelihood, achieving a significant 7.4% PER reduction. PPO and GRPO employ an on-policy approach, training a PER-based reward model to iteratively optimize sequences via reward maximization and KL-regularization, yielding PER reductions of 4.9% and 4.7%, respectively. Comprehensive objective and subjective evaluations confirm that our methods effectively suppress hallucinations while preserving musical quality. Crucially, this work presents a systematic, RL-based solution to hallucination control in lyric-to-song generation. The framework's transferability also unlocks potential for music style adherence and musicality enhancement, opening new avenues for future generative song research.
SongBloom: Coherent Song Generation via Interleaved Autoregressive Sketching and Diffusion Refinement
Jun 09, 2025Generating music with coherent structure, harmonious instrumental and vocal elements remains a significant challenge in song generation. Existing language models and diffusion-based methods often struggle to balance global coherence with local fidelity, resulting in outputs that lack musicality or suffer from incoherent progression and mismatched lyrics. This paper introduces $\textbf{SongBloom}$, a novel framework for full-length song generation that leverages an interleaved paradigm of autoregressive sketching and diffusion-based refinement. SongBloom employs an autoregressive diffusion model that combines the high fidelity of diffusion models with the scalability of language models. Specifically, it gradually extends a musical sketch from short to long and refines the details from coarse to fine-grained. The interleaved generation paradigm effectively integrates prior semantic and acoustic context to guide the generation process. Experimental results demonstrate that SongBloom outperforms existing methods across both subjective and objective metrics and achieves performance comparable to the state-of-the-art commercial music generation platforms. Audio samples are available on our demo page: https://cypress-yang.github.io/SongBloom\_demo.
LeVo: High-Quality Song Generation with Multi-Preference Alignment
Jun 09, 2025



Recent advances in large language models (LLMs) and audio language models have significantly improved music generation, particularly in lyrics-to-song generation. However, existing approaches still struggle with the complex composition of songs and the scarcity of high-quality data, leading to limitations in sound quality, musicality, instruction following, and vocal-instrument harmony. To address these challenges, we introduce LeVo, an LM-based framework consisting of LeLM and a music codec. LeLM is capable of parallelly modeling two types of tokens: mixed tokens, which represent the combined audio of vocals and accompaniment to achieve vocal-instrument harmony, and dual-track tokens, which separately encode vocals and accompaniment for high-quality song generation. It employs two decoder-only transformers and a modular extension training strategy to prevent interference between different token types. To further enhance musicality and instruction following, we introduce a multi-preference alignment method based on Direct Preference Optimization (DPO). This method handles diverse human preferences through a semi-automatic data construction process and DPO post-training. Experimental results demonstrate that LeVo consistently outperforms existing methods on both objective and subjective metrics. Ablation studies further justify the effectiveness of our designs. Audio examples are available at https://levo-demo.github.io/.
ZeroGUI: Automating Online GUI Learning at Zero Human Cost
May 29, 2025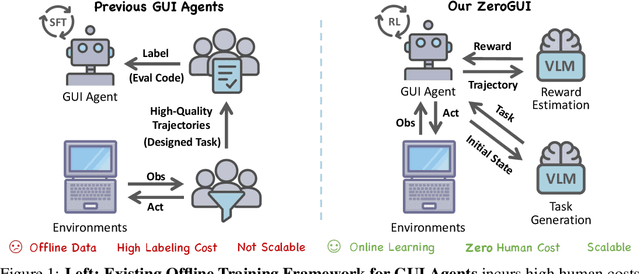
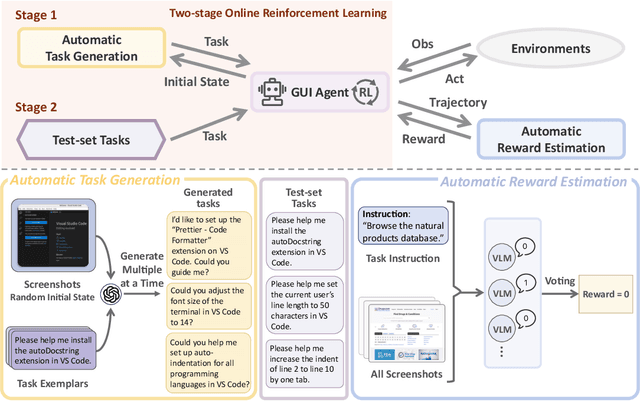


The rapid advancement of large Vision-Language Models (VLMs) has propelled the development of pure-vision-based GUI Agents, capable of perceiving and operating Graphical User Interfaces (GUI) to autonomously fulfill user instructions. However, existing approaches usually adopt an offline learning framework, which faces two core limitations: (1) heavy reliance on high-quality manual annotations for element grounding and action supervision, and (2) limited adaptability to dynamic and interactive environments. To address these limitations, we propose ZeroGUI, a scalable, online learning framework for automating GUI Agent training at Zero human cost. Specifically, ZeroGUI integrates (i) VLM-based automatic task generation to produce diverse training goals from the current environment state, (ii) VLM-based automatic reward estimation to assess task success without hand-crafted evaluation functions, and (iii) two-stage online reinforcement learning to continuously interact with and learn from GUI environments. Experiments on two advanced GUI Agents (UI-TARS and Aguvis) demonstrate that ZeroGUI significantly boosts performance across OSWorld and AndroidLab environments. The code is available at https://github.com/OpenGVLab/ZeroGUI.
MAPLE: Encoding Dexterous Robotic Manipulation Priors Learned From Egocentric Videos
Apr 08, 2025



Large-scale egocentric video datasets capture diverse human activities across a wide range of scenarios, offering rich and detailed insights into how humans interact with objects, especially those that require fine-grained dexterous control. Such complex, dexterous skills with precise controls are crucial for many robotic manipulation tasks, yet are often insufficiently addressed by traditional data-driven approaches to robotic manipulation. To address this gap, we leverage manipulation priors learned from large-scale egocentric video datasets to improve policy learning for dexterous robotic manipulation tasks. We present MAPLE, a novel method for dexterous robotic manipulation that exploits rich manipulation priors to enable efficient policy learning and better performance on diverse, complex manipulation tasks. Specifically, we predict hand-object contact points and detailed hand poses at the moment of hand-object contact and use the learned features to train policies for downstream manipulation tasks. Experimental results demonstrate the effectiveness of MAPLE across existing simulation benchmarks, as well as a newly designed set of challenging simulation tasks, which require fine-grained object control and complex dexterous skills. The benefits of MAPLE are further highlighted in real-world experiments using a dexterous robotic hand, whereas simultaneous evaluation across both simulation and real-world experiments has remained underexplored in prior work.
ORCA: An Open-Source, Reliable, Cost-Effective, Anthropomorphic Robotic Hand for Uninterrupted Dexterous Task Learning
Apr 05, 2025



General-purpose robots should possess humanlike dexterity and agility to perform tasks with the same versatility as us. A human-like form factor further enables the use of vast datasets of human-hand interactions. However, the primary bottleneck in dexterous manipulation lies not only in software but arguably even more in hardware. Robotic hands that approach human capabilities are often prohibitively expensive, bulky, or require enterprise-level maintenance, limiting their accessibility for broader research and practical applications. What if the research community could get started with reliable dexterous hands within a day? We present the open-source ORCA hand, a reliable and anthropomorphic 17-DoF tendon-driven robotic hand with integrated tactile sensors, fully assembled in less than eight hours and built for a material cost below 2,000 CHF. We showcase ORCA's key design features such as popping joints, auto-calibration, and tensioning systems that significantly reduce complexity while increasing reliability, accuracy, and robustness. We benchmark the ORCA hand across a variety of tasks, ranging from teleoperation and imitation learning to zero-shot sim-to-real reinforcement learning. Furthermore, we demonstrate its durability, withstanding more than 10,000 continuous operation cycles - equivalent to approximately 20 hours - without hardware failure, the only constraint being the duration of the experiment itself. All design files, source code, and documentation will be available at https://www.orcahand.com/.