 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Stylized Trajectory Planning for Autonomous Driving via Diffusion Model
Feb 04, 2026Achieving safe and stylized trajectory planning in complex real-world scenarios remains a critical challenge for autonomous driving systems. This paper proposes the SDD Planner, a diffusion-based framework designed to effectively reconcile safety constraints with driving styles in real time. The framework integrates two core modules: a Multi-Source Style-Aware Encoder, which employs distance-sensitive attention to fuse dynamic agent data and environmental contexts for heterogeneous safety-style perception; and a Style-Guided Dynamic Trajectory Generator, which adaptively modulates priority weights within the diffusion denoising process to generate user-preferred yet safe trajectories. Extensive experiments demonstrate that SDD Planner achieves state-of-the-art performance. On the StyleDrive benchmark, it improves the SM-PDMS metric by 3.9% over WoTE, the strongest baseline. Furthermore, on the NuPlan Test14 and Test14-hard benchmarks, SDD Planner ranks first with overall scores of 91.76 and 80.32, respectively, outperforming leading methods such as PLUTO. Real-vehicle closed-loop tests further confirm that SDD Planner maintains high safety standards while aligning with preset driving styles, validating its practical applicability for real-world deployment.
Blockchain-Based Spectrum Resource Securitization via Semi-Fungible Token-Lock
Jan 22, 2026As 6G networks evolve, spectrum assets require flexible, dynamic, and efficient utilization, motivating blockchain based spectrum securitization. Existing approaches based on ERC404 style hybrid token models rely on frequent minting and burning during asset transfers, which disrupt token identity continuity and increase on chain overhead. This paper proposes the Semi Fungible Token Lock (SFT Lock) method, a lock/unlock based mechanism that preserves NFT identity and historical traceability while enabling fractional ownership and transferability. By replacing mint/burn operations with deterministic state transitions, SFT Lock ensures consistent lifecycle representation of spectrum assets and significantly reduces on chain operations. Based on this mechanism, a modular smart contract architecture is designed to support spectrum authorization, securitization, and sharing, and a staking mechanism is introduced to enhance asset liquidity. Experimental results on a private Ethereum network demonstrate that, compared with ERC404 style hybrid token models, the proposed method achieves substantial gas savings while maintaining functional correctness and traceability.
Clustering-Based User Selection in Federated Learning: Metadata Exploitation for 3GPP Networks
Jan 15, 2026Federated learning (FL) enables collaborative model training without sharing raw user data, but conventional simulations often rely on unrealistic data partitioning and current user selection methods ignore data correlation among users. To address these challenges, this paper proposes a metadatadriven FL framework. We first introduce a novel data partition model based on a homogeneous Poisson point process (HPPP), capturing both heterogeneity in data quantity and natural overlap among user datasets. Building on this model, we develop a clustering-based user selection strategy that leverages metadata, such as user location, to reduce data correlation and enhance label diversity across training rounds. Extensive experiments on FMNIST and CIFAR-10 demonstrate that the proposed framework improves model performance, stability, and convergence in non-IID scenarios, while maintaining comparable performance under IID settings. Furthermore, the method shows pronounced advantages when the number of selected users per round is small. These findings highlight the framework's potential for enhancing FL performance in realistic deployments and guiding future standardization.
Goal Force: Teaching Video Models To Accomplish Physics-Conditioned Goals
Jan 09, 2026Recent advancements in video generation have enabled the development of ``world models'' capable of simulating potential futures for robotics and planning. However, specifying precise goals for these models remains a challenge; text instructions are often too abstract to capture physical nuances, while target images are frequently infeasible to specify for dynamic tasks. To address this, we introduce Goal Force, a novel framework that allows users to define goals via explicit force vectors and intermediate dynamics, mirroring how humans conceptualize physical tasks. We train a video generation model on a curated dataset of synthetic causal primitives-such as elastic collisions and falling dominos-teaching it to propagate forces through time and space. Despite being trained on simple physics data, our model exhibits remarkable zero-shot generalization to complex, real-world scenarios, including tool manipulation and multi-object causal chains. Our results suggest that by grounding video generation in fundamental physical interactions, models can emerge as implicit neural physics simulators, enabling precise, physics-aware planning without reliance on external engines. We release all datasets, code, model weights, and interactive video demos at our project page.
Towards a Theoretical Framework for Robust Node Deployment in Cooperative ISAC Networks
Jan 03, 2026This paper investigates node deployment strategies for robust multi-node cooperative localization in integrated sensing and communication (ISAC) networks.We first analyze how steering vector correlation across different positions affects localization performance and introduce a novel distance-weighted correlation metric to characterize this effect. Building upon this insight, we propose a deployment optimization framework that minimizes the maximum weighted steering vector correlation by optimizing simultaneously node positions and array orientations, thereby enhancing worst-case network robustness. Then, a genetic algorithm (GA) is developed to solve this min-max optimization, yielding optimized node positions and array orientations. Extensive simulations using both multiple signal classification (MUSIC) and neural-network (NN)-based localization validate the effectiveness of the proposed methods, demonstrating significant improvements in robust localization performance.
No Vision, No Wearables: 5G-based 2D Human Pose Recognition with Integrated Sensing and Communications
Dec 31, 2025With the increasing maturity of contactless human pose recognition (HPR) technology, indoor interactive applications have raised higher demands for natural, controller-free interaction methods. However, current mainstream HPR solutions relying on vision or radio-frequency (RF) (including WiFi, radar) still face various challenges in practical deployment, such as privacy concerns, susceptibility to occlusion, dedicated equipment and functions, and limited sensing resolution and range. 5G-based integrated sensing and communication (ISAC) technology, by merging communication and sensing functions, offers a new approach to address these challenges in contactless HPR. We propose a practical 5G-based ISAC system capable of inferring 2D HPR from uplink sounding reference signals (SRS). Specifically, rich features are extracted from multiple domains and employ an encoder to achieve unified alignment and representation in a latent space. Subsequently, low-dimensional features are fused to output the human pose state. Experimental results demonstrate that in typical indoor environments, our proposed 5G-based ISAC HPR system significantly outperforms current mainstream baseline solutions in HPR performance, providing a solid technical foundation for universal human-computer interaction.
OxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation
Dec 31, 2025Traditional recommendation systems suffer from inconsistency in multi-stage optimization objectives. Generative Recommendation (GR) mitigates them through an end-to-end framework; however, existing methods still rely on matching mechanisms based on inductive patterns. Although responsive, they lack the ability to uncover complex user intents that require deductive reasoning based on world knowledge. Meanwhile, LLMs show strong deep reasoning capabilities, but their latency and computational costs remain challenging for industrial applications. More critically, there are performance bottlenecks in multi-scenario scalability: as shown in Figure 1, existing solutions require independent training and deployment for each scenario, leading to low resource utilization and high maintenance costs-a challenge unaddressed in GR literature. To address these, we present OxygenREC, an industrial recommendation system that leverages Fast-Slow Thinking to deliver deep reasoning with strict latency and multi-scenario requirements of real-world environments. First, we adopt a Fast-Slow Thinking architecture. Slow thinking uses a near-line LLM pipeline to synthesize Contextual Reasoning Instructions, while fast thinking employs a high-efficiency encoder-decoder backbone for real-time generation. Second, to ensure reasoning instructions effectively enhance recommendation generation, we introduce a semantic alignment mechanism with Instruction-Guided Retrieval (IGR) to filter intent-relevant historical behaviors and use a Query-to-Item (Q2I) loss for instruction-item consistency. Finally, to resolve multi-scenario scalability, we transform scenario information into controllable instructions, using unified reward mapping and Soft Adaptive Group Clip Policy Optimization (SA-GCPO) to align policies with diverse business objectives, realizing a train-once-deploy-everywhere paradigm.
Empower Low-Altitude Economy: A Reliability-Aware Dynamic Weighting Allocation for Multi-modal UAV Beam Prediction
Dec 30, 2025The low-altitude economy (LAE) is rapidly expanding driven by urban air mobility, logistics drones, and aerial sensing, while fast and accurate beam prediction in uncrewed aerial vehicles (UAVs) communications is crucial for achieving reliable connectivity. Current research is shifting from single-signal to multi-modal collaborative approaches. However, existing multi-modal methods mostly employ fixed or empirical weights, assuming equal reliability across modalities at any given moment. Indeed, the importance of different modalities fluctuates dramatically with UAV motion scenarios, and static weighting amplifies the negative impact of degraded modalities. Furthermore, modal mismatch and weak alignment further undermine cross-scenario generalization. To this end, we propose a reliability-aware dynamic weighting scheme applied to a semantic-aware multi-modal beam prediction framework, named SaM2B. Specifically, SaM2B leverages lightweight cues such as environmental visual, flight posture, and geospatial data to adaptively allocate contributions across modalities at different time points through reliability-aware dynamic weight updates. Moreover, by utilizing cross-modal contrastive learning, we align the "multi-source representation beam semantics" associated with specific beam information to a shared semantic space, thereby enhancing discriminative power and robustness under modal noise and distribution shifts. Experiments on real-world low-altitude UAV datasets show that SaM2B achieves more satisfactory results than baseline methods.
Instance Communication System for Intelligent Connected Vehicles: Bridging the Gap from Semantic to Instance-Level Transmission
Dec 27, 2025Intelligent Connected Vehicles (ICVs) rely on high-speed data transmission for efficient and safety-critical services. However, the scarcity of wireless resources limits the capabilities of ICVs. Semantic Communication (SemCom) systems can alleviate this issue by extracting and transmitting task-relevant information, termed semantic information, instead of the entire raw data. Despite this, we reveal that residual redundancy persists within SemCom systems, where not all instances under the same semantic category are equally critical for downstream tasks. To tackle this issue, we introduce Instance Communication (InsCom), which elevates communication from the semantic level to the instance level for ICVs. Specifically, InsCom uses a scene graph generation model to identify all image instances and analyze their inter-relationships, thus distinguishing between semantically identical instances. Additionally, it applies user-configurable, task-critical criteria based on subject semantics and relation-object pairs to filter recognized instances. Consequently, by transmitting only task-critical instances, InsCom significantly reduces data redundancy, substantially enhancing transmission efficiency within limited wireless resources. Evaluations across various datasets and wireless channel conditions show that InsCom achieves a data volume reduction of over 7.82 times and a quality improvement ranging from 1.75 to 14.03 dB compared to the state-of-the-art SemCom systems.
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025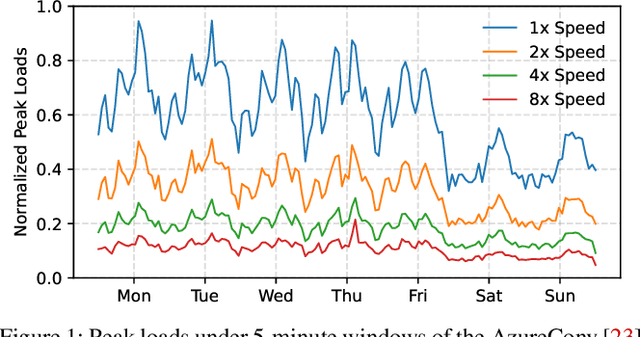
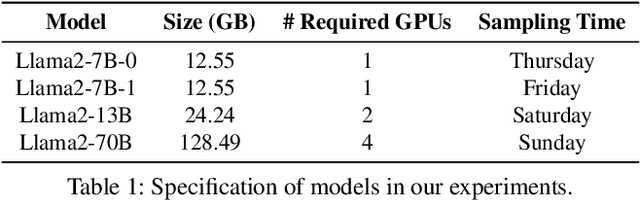
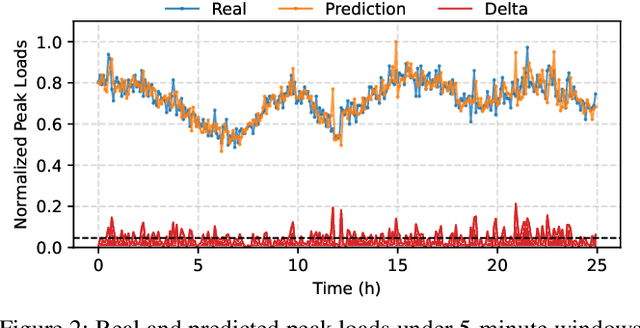
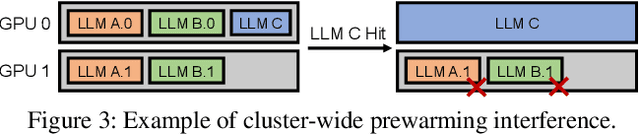
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.