 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOLT: Boost Large Vision-Language Model Without Training for Long-form Video Understanding
Mar 27, 2025Large video-language models (VLMs) have demonstrated promising progress in various video understanding tasks. However, their effectiveness in long-form video analysis is constrained by limited context windows. Traditional approaches, such as uniform frame sampling, often inevitably allocate resources to irrelevant content, diminishing their effectiveness in real-world scenarios. In this paper, we introduce BOLT, a method to BOost Large VLMs without additional Training through a comprehensive study of frame selection strategies. First, to enable a more realistic evaluation of VLMs in long-form video understanding, we propose a multi-source retrieval evaluation setting. Our findings reveal that uniform sampling performs poorly in noisy contexts, underscoring the importance of selecting the right frames. Second, we explore several frame selection strategies based on query-frame similarity and analyze their effectiveness at inference time. Our results show that inverse transform sampling yields the most significant performance improvement, increasing accuracy on the Video-MME benchmark from 53.8% to 56.1% and MLVU benchmark from 58.9% to 63.4%. Our code is available at https://github.com/sming256/BOLT.
MCTS-RAG: Enhancing Retrieval-Augmented Generation with Monte Carlo Tree Search
Mar 26, 2025



We introduce MCTS-RAG, a novel approach that enhances the reasoning capabilities of small language models on knowledge-intensive tasks by leveraging retrieval-augmented generation (RAG) to provide relevant context and Monte Carlo Tree Search (MCTS) to refine reasoning paths. MCTS-RAG dynamically integrates retrieval and reasoning through an iterative decision-making process. Unlike standard RAG methods, which typically retrieve information independently from reasoning and thus integrate knowledge suboptimally, or conventional MCTS reasoning, which depends solely on internal model knowledge without external facts, MCTS-RAG combines structured reasoning with adaptive retrieval. This integrated approach enhances decision-making, reduces hallucinations, and ensures improved factual accuracy and response consistency. The experimental results on multiple reasoning and knowledge-intensive datasets datasets (i.e., ComplexWebQA, GPQA, and FoolMeTwice) show that our method enables small-scale LMs to achieve performance comparable to frontier LLMs like GPT-4o by effectively scaling inference-time compute, setting a new standard for reasoning in small-scale models.
From Zero to Detail: Deconstructing Ultra-High-Definition Image Restoration from Progressive Spectral Perspective
Mar 17, 2025Ultra-high-definition (UHD) image restoration faces significant challenges due to its high resolution, complex content, and intricate details. To cope with these challenges, we analyze the restoration process in depth through a progressive spectral perspective, and deconstruct the complex UHD restoration problem into three progressive stages: zero-frequency enhancement, low-frequency restoration, and high-frequency refinement. Building on this insight, we propose a novel framework, ERR, which comprises three collaborative sub-networks: the zero-frequency enhancer (ZFE), the low-frequency restorer (LFR), and the high-frequency refiner (HFR). Specifically, the ZFE integrates global priors to learn global mapping, while the LFR restores low-frequency information, emphasizing reconstruction of coarse-grained content. Finally, the HFR employs our designed frequency-windowed kolmogorov-arnold networks (FW-KAN) to refine textures and details, producing high-quality image restoration. Our approach significantly outperforms previous UHD methods across various tasks, with extensive ablation studies validating the effectiveness of each component. The code is available at \href{https://github.com/NJU-PCALab/ERR}{here}.
HyperKAN: Hypergraph Representation Learning with Kolmogorov-Arnold Networks
Mar 16, 2025Hypergraph representation learning has garnered increasing attention across various domains due to its capability to model high-order relationships. Traditional methods often rely on hypergraph neural networks (HNNs) employing message passing mechanisms to aggregate vertex and hyperedge features. However, these methods are constrained by their dependence on hypergraph topology, leading to the challenge of imbalanced information aggregation, where high-degree vertices tend to aggregate redundant features, while low-degree vertices often struggle to capture sufficient structural features. To overcome the above challenges, we introduce HyperKAN, a novel framework for hypergraph representation learning that transcends the limitations of message-passing techniques. HyperKAN begins by encoding features for each vertex and then leverages Kolmogorov-Arnold Networks (KANs) to capture complex nonlinear relationships. By adjusting structural features based on similarity, our approach generates refined vertex representations that effectively addresses the challenge of imbalanced information aggregation. Experiments conducted on the real-world datasets demonstrate that HyperKAN significantly outperforms state of-the-art HNN methods, achieving nearly a 9% performance improvement on the Senate dataset.
Monte Carlo Diffusion for Generalizable Learning-Based RANSAC
Mar 12, 2025



Random Sample Consensus (RANSAC) is a fundamental approach for robustly estimating parametric models from noisy data. Existing learning-based RANSAC methods utilize deep learning to enhance the robustness of RANSAC against outliers. However, these approaches are trained and tested on the data generated by the same algorithms, leading to limited generalization to out-of-distribution data during inference. Therefore, in this paper, we introduce a novel diffusion-based paradigm that progressively injects noise into ground-truth data, simulating the noisy conditions for training learning-based RANSAC. To enhance data diversity, we incorporate Monte Carlo sampling into the diffusion paradigm, approximating diverse data distributions by introducing different types of randomness at multiple stages. We evaluate our approach in the context of feature matching through comprehensive experiments on the ScanNet and MegaDepth datasets. The experimental results demonstrate that our Monte Carlo diffusion mechanism significantly improves the generalization ability of learning-based RANSAC. We also develop extensive ablation studies that highlight the effectiveness of key components in our framework.
Multi-Modal Foundation Models for Computational Pathology: A Survey
Mar 12, 2025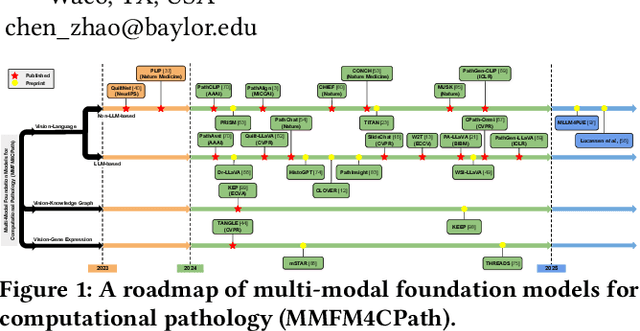
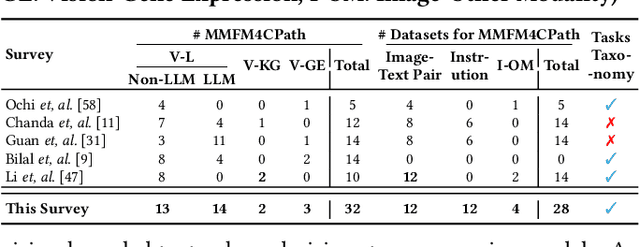

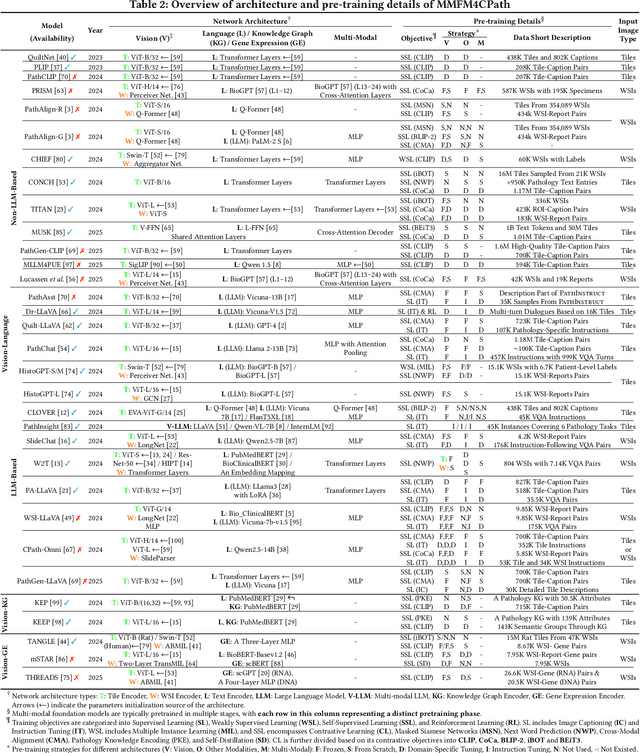
Foundation models have emerged as a powerful paradigm in computational pathology (CPath), enabling scalable and generalizable analysis of histopathological images. While early developments centered on uni-modal models trained solely on visual data, recent advances have highlighted the promise of multi-modal foundation models that integrate heterogeneous data sources such as textual reports, structured domain knowledge, and molecular profiles. In this survey, we provide a comprehensive and up-to-date review of multi-modal foundation models in CPath, with a particular focus on models built upon hematoxylin and eosin (H&E) stained whole slide images (WSIs) and tile-level representations. We categorize 32 state-of-the-art multi-modal foundation models into three major paradigms: vision-language, vision-knowledge graph, and vision-gene expression. We further divide vision-language models into non-LLM-based and LLM-based approaches. Additionally, we analyze 28 available multi-modal datasets tailored for pathology, grouped into image-text pairs, instruction datasets, and image-other modality pairs. Our survey also presents a taxonomy of downstream tasks, highlights training and evaluation strategies, and identifies key challenges and future directions. We aim for this survey to serve as a valuable resource for researchers and practitioners working at the intersection of pathology and AI.
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection
Feb 27, 2025Temporal action detection (TAD) is a fundamental video understanding task that aims to identify human actions and localize their temporal boundaries in videos. Although this field has achieved remarkable progress in recent years, further progress and real-world applications are impeded by the absence of a standardized framework. Currently, different methods are compared under different implementation settings, evaluation protocols, etc., making it difficult to assess the real effectiveness of a specific technique. To address this issue, we propose \textbf{OpenTAD}, a unified TAD framework consolidating 16 different TAD methods and 9 standard datasets into a modular codebase. In OpenTAD, minimal effort is required to replace one module with a different design, train a feature-based TAD model in end-to-end mode, or switch between the two. OpenTAD also facilitates straightforward benchmarking across various datasets and enables fair and in-depth comparisons among different methods. With OpenTAD, we comprehensively study how innovations in different network components affect detection performance and identify the most effective design choices through extensive experiments. This study has led to a new state-of-the-art TAD method built upon existing techniques for each component. We have made our code and models available at https://github.com/sming256/OpenTAD.
FedDA-TSformer: Federated Domain Adaptation with Vision TimeSformer for Left Ventricle Segmentation on Gated Myocardial Perfusion SPECT Image
Feb 23, 2025Background and Purpose: Functional assessment of the left ventricle using gated myocardial perfusion (MPS) single-photon emission computed tomography relies on the precise extraction of the left ventricular contours while simultaneously ensuring the security of patient data. Methods: In this paper, we introduce the integration of Federated Domain Adaptation with TimeSformer, named 'FedDA-TSformer' for left ventricle segmentation using MPS. FedDA-TSformer captures spatial and temporal features in gated MPS images, leveraging spatial attention, temporal attention, and federated learning for improved domain adaptation while ensuring patient data security. In detail, we employed Divide-Space-Time-Attention mechanism to extract spatio-temporal correlations from the multi-centered MPS datasets, ensuring that predictions are spatio-temporally consistent. To achieve domain adaptation, we align the model output on MPS from three different centers using local maximum mean discrepancy (LMMD) loss. This approach effectively addresses the dual requirements of federated learning and domain adaptation, enhancing the model's performance during training with multi-site datasets while ensuring the protection of data from different hospitals. Results: Our FedDA-TSformer was trained and evaluated using MPS datasets collected from three hospitals, comprising a total of 150 subjects. Each subject's cardiac cycle was divided into eight gates. The model achieved Dice Similarity Coefficients (DSC) of 0.842 and 0.907 for left ventricular (LV) endocardium and epicardium segmentation, respectively. Conclusion: Our proposed FedDA-TSformer model addresses the challenge of multi-center generalization, ensures patient data privacy protection, and demonstrates effectiveness in left ventricular (LV) segmentation.
A Survey on Computational Pathology Foundation Models: Datasets, Adaptation Strategies, and Evaluation Tasks
Jan 27, 2025Computational pathology foundation models (CPathFMs) have emerged as a powerful approach for analyzing histopathological data, leveraging self-supervised learning to extract robust feature representations from unlabeled whole-slide images. These models, categorized into uni-modal and multi-modal frameworks, have demonstrated promise in automating complex pathology tasks such as segmentation, classification, and biomarker discovery. However, the development of CPathFMs presents significant challenges, such as limited data accessibility, high variability across datasets, the necessity for domain-specific adaptation, and the lack of standardized evaluation benchmarks. This survey provides a comprehensive review of CPathFMs in computational pathology, focusing on datasets, adaptation strategies, and evaluation tasks. We analyze key techniques, such as contrastive learning and multi-modal integration, and highlight existing gaps in current research. Finally, we explore future directions from four perspectives for advancing CPathFMs. This survey serves as a valuable resource for researchers, clinicians, and AI practitioners, guiding the advancement of CPathFMs toward robust and clinically applicable AI-driven pathology solutions.
MMVU: Measuring Expert-Level Multi-Discipline Video Understanding
Jan 21, 2025



We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions spanning 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features three key advancements. First, it challenges models to apply domain-specific knowledge and perform expert-level reasoning to analyze specialized-domain videos, moving beyond the basic visual perception typically assessed in current video benchmarks. Second, each example is annotated by human experts from scratch. We implement strict data quality controls to ensure the high quality of the dataset. Finally, each example is enriched with expert-annotated reasoning rationals and relevant domain knowledge, facilitating in-depth analysis. We conduct an extensive evaluation of 32 frontier multimodal foundation models on MMVU. The latest System-2-capable models, o1 and Gemini 2.0 Flash Thinking, achieve the highest performance among the tested models. However, they still fall short of matching human expertise. Through in-depth error analyses and case studies, we offer actionable insights for future advancements in expert-level, knowledge-intensive video understanding for specialized domains.