 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPSEBM: An Energy-Based Model with Progressive Parameter Selection for Continual Learning
Dec 17, 2025



Continual learning remains a fundamental challenge in machine learning, requiring models to learn from a stream of tasks without forgetting previously acquired knowledge. A major obstacle in this setting is catastrophic forgetting, where performance on earlier tasks degrades as new tasks are learned. In this paper, we introduce PPSEBM, a novel framework that integrates an Energy-Based Model (EBM) with Progressive Parameter Selection (PPS) to effectively address catastrophic forgetting in continual learning for natural language processing tasks. In PPSEBM, progressive parameter selection allocates distinct, task-specific parameters for each new task, while the EBM generates representative pseudo-samples from prior tasks. These generated samples actively inform and guide the parameter selection process, enhancing the model's ability to retain past knowledge while adapting to new tasks. Experimental results on diverse NLP benchmarks demonstrate that PPSEBM outperforms state-of-the-art continual learning methods, offering a promising and robust solution to mitigate catastrophic forgetting.
Dynamic Environment Responsive Online Meta-Learning with Fairness Awareness
Feb 19, 2024



The fairness-aware online learning framework has emerged as a potent tool within the context of continuous lifelong learning. In this scenario, the learner's objective is to progressively acquire new tasks as they arrive over time, while also guaranteeing statistical parity among various protected sub-populations, such as race and gender, when it comes to the newly introduced tasks. A significant limitation of current approaches lies in their heavy reliance on the i.i.d (independent and identically distributed) assumption concerning data, leading to a static regret analysis of the framework. Nevertheless, it's crucial to note that achieving low static regret does not necessarily translate to strong performance in dynamic environments characterized by tasks sampled from diverse distributions. In this paper, to tackle the fairness-aware online learning challenge in evolving settings, we introduce a unique regret measure, FairSAR, by incorporating long-term fairness constraints into a strongly adapted loss regret framework. Moreover, to determine an optimal model parameter at each time step, we introduce an innovative adaptive fairness-aware online meta-learning algorithm, referred to as FairSAOML. This algorithm possesses the ability to adjust to dynamic environments by effectively managing bias control and model accuracy. The problem is framed as a bi-level convex-concave optimization, considering both the model's primal and dual parameters, which pertain to its accuracy and fairness attributes, respectively. Theoretical analysis yields sub-linear upper bounds for both loss regret and the cumulative violation of fairness constraints. Our experimental evaluation on various real-world datasets in dynamic environments demonstrates that our proposed FairSAOML algorithm consistently outperforms alternative approaches rooted in the most advanced prior online learning methods.
Towards Fair Disentangled Online Learning for Changing Environments
May 31, 2023



In the problem of online learning for changing environments, data are sequentially received one after another over time, and their distribution assumptions may vary frequently. Although existing methods demonstrate the effectiveness of their learning algorithms by providing a tight bound on either dynamic regret or adaptive regret, most of them completely ignore learning with model fairness, defined as the statistical parity across different sub-population (e.g., race and gender). Another drawback is that when adapting to a new environment, an online learner needs to update model parameters with a global change, which is costly and inefficient. Inspired by the sparse mechanism shift hypothesis, we claim that changing environments in online learning can be attributed to partial changes in learned parameters that are specific to environments and the rest remain invariant to changing environments. To this end, in this paper, we propose a novel algorithm under the assumption that data collected at each time can be disentangled with two representations, an environment-invariant semantic factor and an environment-specific variation factor. The semantic factor is further used for fair prediction under a group fairness constraint. To evaluate the sequence of model parameters generated by the learner, a novel regret is proposed in which it takes a mixed form of dynamic and static regret metrics followed by a fairness-aware long-term constraint. The detailed analysis provides theoretical guarantees for loss regret and violation of cumulative fairness constraints. Empirical evaluations on real-world datasets demonstrate our proposed method sequentially outperforms baseline methods in model accuracy and fairness.
An Automated Vulnerability Detection Framework for Smart Contracts
Jan 20, 2023With the increase of the adoption of blockchain technology in providing decentralized solutions to various problems, smart contracts have become more popular to the point that billions of US Dollars are currently exchanged every day through such technology. Meanwhile, various vulnerabilities in smart contracts have been exploited by attackers to steal cryptocurrencies worth millions of dollars. The automatic detection of smart contract vulnerabilities therefore is an essential research problem. Existing solutions to this problem particularly rely on human experts to define features or different rules to detect vulnerabilities. However, this often causes many vulnerabilities to be ignored, and they are inefficient in detecting new vulnerabilities. In this study, to overcome such challenges, we propose a framework to automatically detect vulnerabilities in smart contracts on the blockchain. More specifically, first, we utilize novel feature vector generation techniques from bytecode of smart contract since the source code of smart contracts are rarely available in public. Next, the collected vectors are fed into our novel metric learning-based deep neural network(DNN) to get the detection result. We conduct comprehensive experiments on large-scale benchmarks, and the quantitative results demonstrate the effectiveness and efficiency of our approach.
Adaptive Fairness-Aware Online Meta-Learning for Changing Environments
May 26, 2022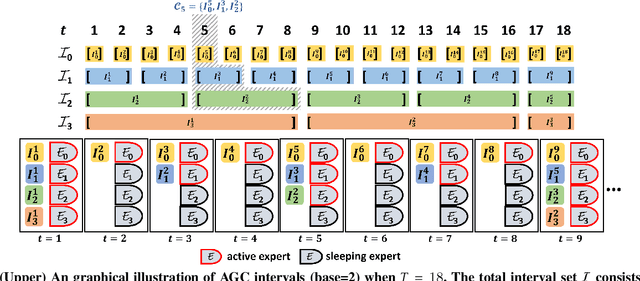

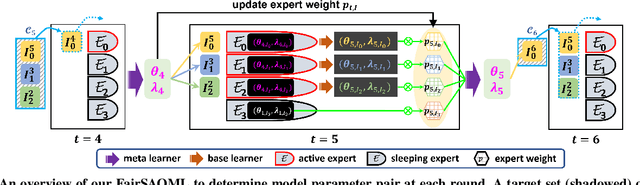

The fairness-aware online learning framework has arisen as a powerful tool for the continual lifelong learning setting. The goal for the learner is to sequentially learn new tasks where they come one after another over time and the learner ensures the statistic parity of the new coming task across different protected sub-populations (e.g. race and gender). A major drawback of existing methods is that they make heavy use of the i.i.d assumption for data and hence provide static regret analysis for the framework. However, low static regret cannot imply a good performance in changing environments where tasks are sampled from heterogeneous distributions. To address the fairness-aware online learning problem in changing environments, in this paper, we first construct a novel regret metric FairSAR by adding long-term fairness constraints onto a strongly adapted loss regret. Furthermore, to determine a good model parameter at each round, we propose a novel adaptive fairness-aware online meta-learning algorithm, namely FairSAOML, which is able to adapt to changing environments in both bias control and model precision. The problem is formulated in the form of a bi-level convex-concave optimization with respect to the model's primal and dual parameters that are associated with the model's accuracy and fairness, respectively. The theoretic analysis provides sub-linear upper bounds for both loss regret and violation of cumulative fairness constraints. Our experimental evaluation on different real-world datasets with settings of changing environments suggests that the proposed FairSAOML significantly outperforms alternatives based on the best prior online learning approaches.