 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocMath-Eval: Evaluating Numerical Reasoning Capabilities of LLMs in Understanding Long Documents with Tabular Data
Nov 16, 2023



Recent LLMs have demonstrated remarkable performance in solving exam-like math word problems. However, the degree to which these numerical reasoning skills are effective in real-world scenarios, particularly in expert domains, is still largely unexplored. This paper introduces DocMath-Eval, a comprehensive benchmark specifically designed to evaluate the numerical reasoning and problem-solving capabilities of LLMs in the context of understanding and analyzing financial documents containing both text and tables. We evaluate a wide spectrum of 19 LLMs, including those specialized in coding and finance. We also incorporate different prompting strategies (i.e., Chain-of-Thoughts and Program-of-Thoughts) to comprehensively assess the capabilities and limitations of existing LLMs in DocMath-Eval. We found that, although the current best-performing system (i.e., GPT-4), can perform well on simple problems such as calculating the rate of increase in a financial metric within a short document context, it significantly lags behind human experts in more complex problems grounded in longer contexts. We believe DocMath-Eval can be used as a valuable benchmark to evaluate LLMs' capabilities to solve challenging numerical reasoning problems in expert domains. We will release the benchmark and code at https://github.com/yale-nlp/DocMath-Eval.
On Evaluating the Integration of Reasoning and Action in LLM Agents with Database Question Answering
Nov 16, 2023



This study introduces a new long-form database question answering dataset designed to evaluate how Large Language Models (LLMs) interact with a SQL interpreter. The task necessitates LLMs to strategically generate multiple SQL queries to retrieve sufficient data from a database, to reason with the acquired context, and to synthesize them into a comprehensive analytical narrative. Our findings highlight that this task poses great challenges even for the state-of-the-art GPT-4 model. We propose and evaluate two interaction strategies, and provide a fine-grained analysis of the individual stages within the interaction. A key discovery is the identification of two primary bottlenecks hindering effective interaction: the capacity for planning and the ability to generate multiple SQL queries. To address the challenge of accurately assessing answer quality, we introduce a multi-agent evaluation framework that simulates the academic peer-review process, enhancing the precision and reliability of our evaluations. This framework allows for a more nuanced understanding of the strengths and limitations of current LLMs in complex retrieval and reasoning tasks.
RobuT: A Systematic Study of Table QA Robustness Against Human-Annotated Adversarial Perturbations
Jun 25, 2023



Despite significant progress having been made in question answering on tabular data (Table QA), it's unclear whether, and to what extent existing Table QA models are robust to task-specific perturbations, e.g., replacing key question entities or shuffling table columns. To systematically study the robustness of Table QA models, we propose a benchmark called RobuT, which builds upon existing Table QA datasets (WTQ, WikiSQL-Weak, and SQA) and includes human-annotated adversarial perturbations in terms of table header, table content, and question. Our results indicate that both state-of-the-art Table QA models and large language models (e.g., GPT-3) with few-shot learning falter in these adversarial sets. We propose to address this problem by using large language models to generate adversarial examples to enhance training, which significantly improves the robustness of Table QA models. Our data and code is publicly available at https://github.com/yilunzhao/RobuT.
Large Language Models are Effective Table-to-Text Generators, Evaluators, and Feedback Providers
May 24, 2023



Large language models (LLMs) have shown remarkable ability on controllable text generation. However, the potential of LLMs in generating text from structured tables remains largely under-explored. In this paper, we study the capabilities of LLMs for table-to-text generation tasks, particularly aiming to investigate their performance in generating natural language statements that can be logically entailed by a provided table. First, we investigate how LLMs compare to state-of-the-art table-to-text fine-tuned models, and demonstrate that LLMs can generate statements with higher faithfulness compared with previous state-of-the-art fine-tuned models. Given this finding, we next explore whether LLMs can serve as faithfulness-level automated evaluation metrics. Through human evaluation, we show that evaluation metrics adopted from LLMs correlates better with human judgments compared with existing faithfulness-level metrics. Finally, we demonstrate that LLMs using chain-of-thought prompting can generate high-fidelity natural language feedback for other table-to-text models' generations, provide insights for future work regarding the distillation of text generation capabilities from LLMs to smaller models.
QTSumm: A New Benchmark for Query-Focused Table Summarization
May 23, 2023



People primarily consult tables to conduct data analysis or answer specific questions. Text generation systems that can provide accurate table summaries tailored to users' information needs can facilitate more efficient access to relevant data insights. However, existing table-to-text generation studies primarily focus on converting tabular data into coherent statements, rather than addressing information-seeking purposes. In this paper, we define a new query-focused table summarization task, where text generation models have to perform human-like reasoning and analysis over the given table to generate a tailored summary, and we introduce a new benchmark named QTSumm for this task. QTSumm consists of 5,625 human-annotated query-summary pairs over 2,437 tables on diverse topics. Moreover, we investigate state-of-the-art models (i.e., text generation, table-to-text generation, and large language models) on the QTSumm dataset. Experimental results and manual analysis reveal that our benchmark presents significant challenges in table-to-text generation for future research.
Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
May 21, 2023In-context learning (ICL) has emerged as a new approach to various natural language processing tasks, utilizing large language models (LLMs) to make predictions based on context that has been supplemented with a few examples or task-specific instructions. In this paper, we aim to extend this method to question answering tasks that utilize structured knowledge sources, and improve Text-to-SQL systems by exploring various prompt design strategies for employing LLMs. We conduct a systematic investigation into different demonstration selection methods and optimal instruction formats for prompting LLMs in the Text-to-SQL task. Our approach involves leveraging the syntactic structure of an example's SQL query to retrieve demonstrations, and we demonstrate that pursuing both diversity and similarity in demonstration selection leads to enhanced performance. Furthermore, we show that LLMs benefit from database-related knowledge augmentations. Our most effective strategy outperforms the state-of-the-art system by 2.5 points (Execution Accuracy) and the best fine-tuned system by 5.1 points on the Spider dataset. These results highlight the effectiveness of our approach in adapting LLMs to the Text-to-SQL task, and we present an analysis of the factors contributing to the success of our strategy.
LoFT: Enhancing Faithfulness and Diversity for Table-to-Text Generation via Logic Form Control
Feb 06, 2023



Logical Table-to-Text (LT2T) generation is tasked with generating logically faithful sentences from tables. There currently exists two challenges in the field: 1) Faithfulness: how to generate sentences that are factually correct given the table content; 2) Diversity: how to generate multiple sentences that offer different perspectives on the table. This work proposes LoFT, which utilizes logic forms as fact verifiers and content planners to control LT2T generation. Experimental results on the LogicNLG dataset demonstrate that LoFT is the first model that addresses unfaithfulness and lack of diversity issues simultaneously. Our code is publicly available at https://github.com/Yale-LILY/LoFT.
Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation
Dec 15, 2022Human evaluation is the foundation upon which the evaluation of both summarization systems and automatic metrics rests. However, existing human evaluation protocols and benchmarks for summarization either exhibit low inter-annotator agreement or lack the scale needed to draw statistically significant conclusions, and an in-depth analysis of human evaluation is lacking. In this work, we address the shortcomings of existing summarization evaluation along the following axes: 1) We propose a modified summarization salience protocol, Atomic Content Units (ACUs), which relies on fine-grained semantic units and allows for high inter-annotator agreement. 2) We curate the Robust Summarization Evaluation (RoSE) benchmark, a large human evaluation dataset consisting of over 22k summary-level annotations over state-of-the-art systems on three datasets. 3) We compare our ACU protocol with three other human evaluation protocols, underscoring potential confounding factors in evaluation setups. 4) We evaluate existing automatic metrics using the collected human annotations across evaluation protocols and demonstrate how our benchmark leads to more statistically stable and significant results. Furthermore, our findings have important implications for evaluating large language models (LLMs), as we show that LLMs adjusted by human feedback (e.g., GPT-3.5) may overfit unconstrained human evaluation, which is affected by the annotators' prior, input-agnostic preferences, calling for more robust, targeted evaluation methods.
FOLIO: Natural Language Reasoning with First-Order Logic
Sep 02, 2022
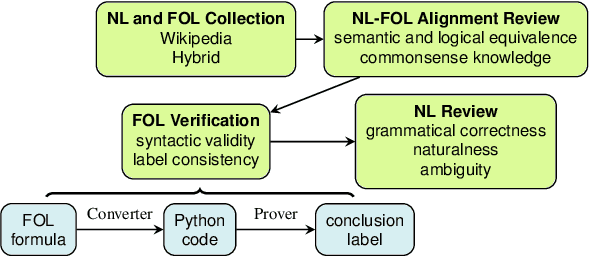
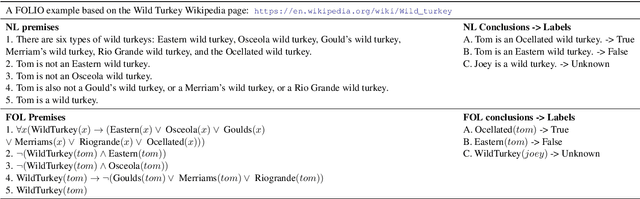
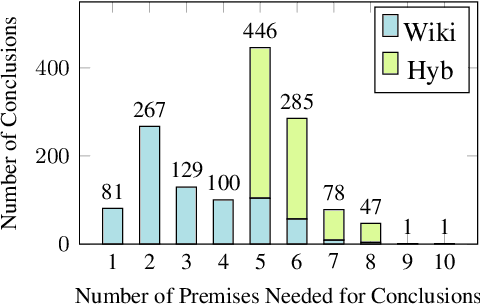
We present FOLIO, a human-annotated, open-domain, and logically complex and diverse dataset for reasoning in natural language (NL), equipped with first order logic (FOL) annotations. FOLIO consists of 1,435 examples (unique conclusions), each paired with one of 487 sets of premises which serve as rules to be used to deductively reason for the validity of each conclusion. The logical correctness of premises and conclusions is ensured by their parallel FOL annotations, which are automatically verified by our FOL inference engine. In addition to the main NL reasoning task, NL-FOL pairs in FOLIO automatically constitute a new NL-FOL translation dataset using FOL as the logical form. Our experiments on FOLIO systematically evaluate the FOL reasoning ability of supervised fine-tuning on medium-sized language models (BERT, RoBERTa) and few-shot prompting on large language models (GPT-NeoX, OPT, GPT-3, Codex). For NL-FOL translation, we experiment with GPT-3 and Codex. Our results show that one of the most capable Large Language Model (LLM) publicly available, GPT-3 davinci, achieves only slightly better than random results with few-shot prompting on a subset of FOLIO, and the model is especially bad at predicting the correct truth values for False and Unknown conclusions. Our dataset and code are available at https://github.com/Yale-LILY/FOLIO.
Leveraging Locality in Abstractive Text Summarization
May 25, 2022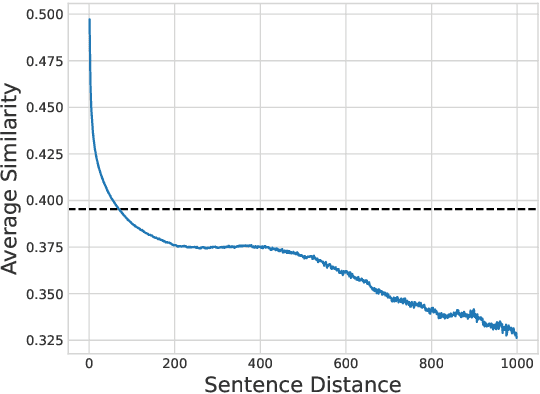
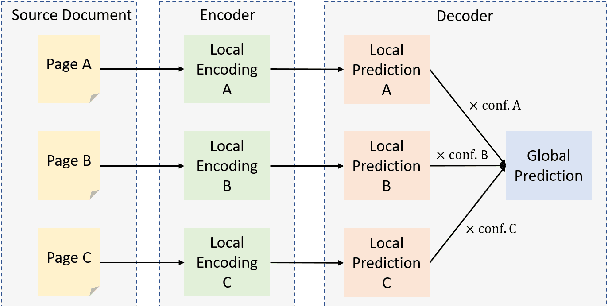
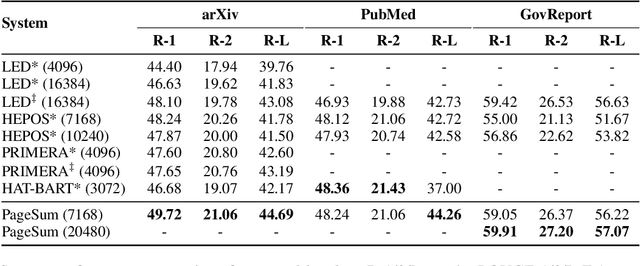
Despite the successes of neural attention models for natural language generation tasks, the quadratic memory complexity of the self-attention module with respect to the input length hinders their applications in long text summarization. Instead of designing more efficient attention modules, we approach this problem by investigating if models with a restricted context can have competitive performance compared with the memory-efficient attention models that maintain a global context by treating the input as an entire sequence. Our model is applied to individual pages, which contain parts of inputs grouped by the principle of locality, during both encoding and decoding stages. We empirically investigated three kinds of localities in text summarization at different levels, ranging from sentences to documents. Our experimental results show that our model can have better performance compared with strong baseline models with efficient attention modules, and our analysis provides further insights of our locality-aware modeling strategy.