 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models
Jul 03, 2025Arithmetic circuits, such as adders and multipliers, are fundamental components of digital systems, directly impacting the performance, power efficiency, and area footprint. However, optimizing these circuits remains challenging due to the vast design space and complex physical constraints. While recent deep learning-based approaches have shown promise, they struggle to consistently explore high-potential design variants, limiting their optimization efficiency. To address this challenge, we propose AC-Refiner, a novel arithmetic circuit optimization framework leveraging conditional diffusion models. Our key insight is to reframe arithmetic circuit synthesis as a conditional image generation task. By carefully conditioning the denoising diffusion process on target quality-of-results (QoRs), AC-Refiner consistently produces high-quality circuit designs. Furthermore, the explored designs are used to fine-tune the diffusion model, which focuses the exploration near the Pareto frontier. Experimental results demonstrate that AC-Refiner generates designs with superior Pareto optimality, outperforming state-of-the-art baselines. The performance gain is further validated by integrating AC-Refiner into practical applications.
Commonsense Generation and Evaluation for Dialogue Systems using Large Language Models
Jun 24, 2025This paper provides preliminary results on exploring the task of performing turn-level data augmentation for dialogue system based on different types of commonsense relationships, and the automatic evaluation of the generated synthetic turns. The proposed methodology takes advantage of the extended knowledge and zero-shot capabilities of pretrained Large Language Models (LLMs) to follow instructions, understand contextual information, and their commonsense reasoning capabilities. The approach draws inspiration from methodologies like Chain-of-Thought (CoT), applied more explicitly to the task of prompt-based generation for dialogue-based data augmentation conditioned on commonsense attributes, and the automatic evaluation of the generated dialogues. To assess the effectiveness of the proposed approach, first we extracted 200 randomly selected partial dialogues, from 5 different well-known dialogue datasets, and generate alternative responses conditioned on different event commonsense attributes. This novel dataset allows us to measure the proficiency of LLMs in generating contextually relevant commonsense knowledge, particularly up to 12 different specific ATOMIC [10] database relations. Secondly, we propose an evaluation framework to automatically detect the quality of the generated dataset inspired by the ACCENT [26] metric, which offers a nuanced approach to assess event commonsense. However, our method does not follow ACCENT's complex eventrelation tuple extraction process. Instead, we propose an instruction-based prompt for each commonsense attribute and use state-of-the-art LLMs to automatically detect the original attributes used when creating each augmented turn in the previous step. Preliminary results suggest that our approach effectively harnesses LLMs capabilities for commonsense reasoning and evaluation in dialogue systems.
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025
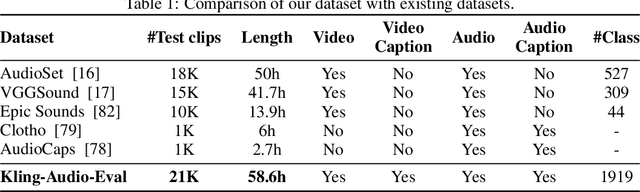
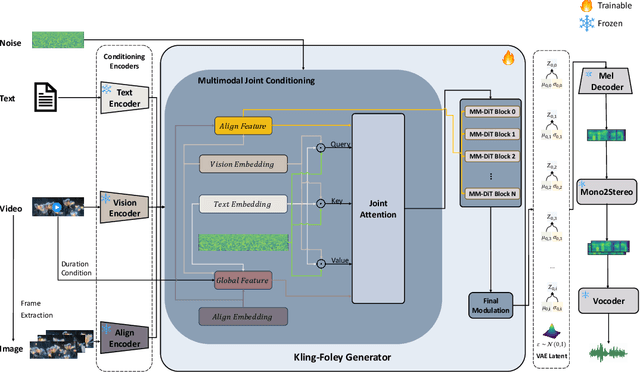
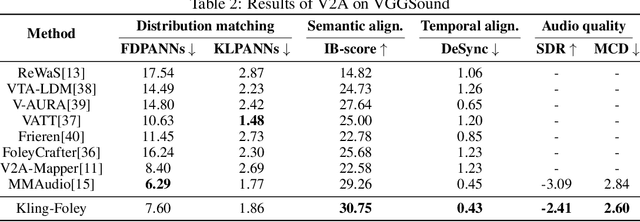
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
Bipedal Balance Control with Whole-body Musculoskeletal Standing and Falling Simulations
Jun 11, 2025Balance control is important for human and bipedal robotic systems. While dynamic balance during locomotion has received considerable attention, quantitative understanding of static balance and falling remains limited. This work presents a hierarchical control pipeline for simulating human balance via a comprehensive whole-body musculoskeletal system. We identified spatiotemporal dynamics of balancing during stable standing, revealed the impact of muscle injury on balancing behavior, and generated fall contact patterns that aligned with clinical data. Furthermore, our simulated hip exoskeleton assistance demonstrated improvement in balance maintenance and reduced muscle effort under perturbation. This work offers unique muscle-level insights into human balance dynamics that are challenging to capture experimentally. It could provide a foundation for developing targeted interventions for individuals with balance impairments and support the advancement of humanoid robotic systems.
Quickest Causal Change Point Detection by Adaptive Intervention
Jun 09, 2025We propose an algorithm for change point monitoring in linear causal models that accounts for interventions. Through a special centralization technique, we can concentrate the changes arising from causal propagation across nodes into a single dimension. Additionally, by selecting appropriate intervention nodes based on Kullback-Leibler divergence, we can amplify the change magnitude. We also present an algorithm for selecting the intervention values, which aids in the identification of the most effective intervention nodes. Two monitoring methods are proposed, each with an adaptive intervention policy to make a balance between exploration and exploitation. We theoretically demonstrate the first-order optimality of the proposed methods and validate their properties using simulation datasets and two real-world case studies.
Accelerating 3D Gaussian Splatting with Neural Sorting and Axis-Oriented Rasterization
Jun 08, 2025



3D Gaussian Splatting (3DGS) has recently gained significant attention for high-quality and efficient view synthesis, making it widely adopted in fields such as AR/VR, robotics, and autonomous driving. Despite its impressive algorithmic performance, real-time rendering on resource-constrained devices remains a major challenge due to tight power and area budgets. This paper presents an architecture-algorithm co-design to address these inefficiencies. First, we reveal substantial redundancy caused by repeated computation of common terms/expressions during the conventional rasterization. To resolve this, we propose axis-oriented rasterization, which pre-computes and reuses shared terms along both the X and Y axes through a dedicated hardware design, effectively reducing multiply-and-add (MAC) operations by up to 63%. Second, by identifying the resource and performance inefficiency of the sorting process, we introduce a novel neural sorting approach that predicts order-independent blending weights using an efficient neural network, eliminating the need for costly hardware sorters. A dedicated training framework is also proposed to improve its algorithmic stability. Third, to uniformly support rasterization and neural network inference, we design an efficient reconfigurable processing array that maximizes hardware utilization and throughput. Furthermore, we introduce a $\pi$-trajectory tile schedule, inspired by Morton encoding and Hilbert curve, to optimize Gaussian reuse and reduce memory access overhead. Comprehensive experiments demonstrate that the proposed design preserves rendering quality while achieving a speedup of $23.4\sim27.8\times$ and energy savings of $28.8\sim51.4\times$ compared to edge GPUs for real-world scenes. We plan to open-source our design to foster further development in this field.
Wavelet-based Disentangled Adaptive Normalization for Non-stationary Times Series Forecasting
Jun 06, 2025Forecasting non-stationary time series is a challenging task because their statistical properties often change over time, making it hard for deep models to generalize well. Instance-level normalization techniques can help address shifts in temporal distribution. However, most existing methods overlook the multi-component nature of time series, where different components exhibit distinct non-stationary behaviors. In this paper, we propose Wavelet-based Disentangled Adaptive Normalization (WDAN), a model-agnostic framework designed to address non-stationarity in time series forecasting. WDAN uses discrete wavelet transforms to break down the input into low-frequency trends and high-frequency fluctuations. It then applies tailored normalization strategies to each part. For trend components that exhibit strong non-stationarity, we apply first-order differencing to extract stable features used for predicting normalization parameters. Extensive experiments on multiple benchmarks demonstrate that WDAN consistently improves forecasting accuracy across various backbone model. Code is available at this repository: https://github.com/MonBG/WDAN.
Bridging External and Parametric Knowledge: Mitigating Hallucination of LLMs with Shared-Private Semantic Synergy in Dual-Stream Knowledge
Jun 06, 2025Retrieval-augmented generation (RAG) is a cost-effective approach to mitigate the hallucination of Large Language Models (LLMs) by incorporating the retrieved external knowledge into the generation process. However, external knowledge may conflict with the parametric knowledge of LLMs. Furthermore, current LLMs lack inherent mechanisms for resolving such knowledge conflicts, making traditional RAG methods suffer from degraded performance and stability. Thus, we propose a Dual-Stream Knowledge-Augmented Framework for Shared-Private Semantic Synergy (DSSP-RAG). Central to the framework is a novel approach that refines self-attention into a mixed-attention, distinguishing shared and private semantics for a controlled internal-external knowledge integration. To effectively facilitate DSSP in RAG, we further introduce an unsupervised hallucination detection method based on cognitive uncertainty, ensuring the necessity of introducing knowledge, and an Energy Quotient (EQ) based on attention difference matrices to reduce noise in the retrieved external knowledge. Extensive experiments on benchmark datasets show that DSSP-RAG can effectively resolve conflicts and enhance the complementarity of dual-stream knowledge, leading to superior performance over strong baselines.
Pangu DeepDiver: Adaptive Search Intensity Scaling via Open-Web Reinforcement Learning
May 30, 2025Information seeking demands iterative evidence gathering and reflective reasoning, yet large language models (LLMs) still struggle with it in open-web question answering. Existing methods rely on static prompting rules or training with Wikipedia-based corpora and retrieval environments, limiting adaptability to the real-world web environment where ambiguity, conflicting evidence, and noise are prevalent. These constrained training settings hinder LLMs from learning to dynamically decide when and where to search, and how to adjust search depth and frequency based on informational demands. We define this missing capacity as Search Intensity Scaling (SIS)--the emergent skill to intensify search efforts under ambiguous or conflicting conditions, rather than settling on overconfident, under-verification answers. To study SIS, we introduce WebPuzzle, the first dataset designed to foster information-seeking behavior in open-world internet environments. WebPuzzle consists of 24K training instances and 275 test questions spanning both wiki-based and open-web queries. Building on this dataset, we propose DeepDiver, a Reinforcement Learning (RL) framework that promotes SIS by encouraging adaptive search policies through exploration under a real-world open-web environment. Experimental results show that Pangu-7B-Reasoner empowered by DeepDiver achieve performance on real-web tasks comparable to the 671B-parameter DeepSeek-R1. We detail DeepDiver's training curriculum from cold-start supervised fine-tuning to a carefully designed RL phase, and present that its capability of SIS generalizes from closed-form QA to open-ended tasks such as long-form writing. Our contributions advance adaptive information seeking in LLMs and provide a valuable benchmark and dataset for future research.
Large-Scale Bayesian Tensor Reconstruction: An Approximate Message Passing Solution
May 22, 2025



Tensor CANDECOMP/PARAFAC decomposition (CPD) is a fundamental model for tensor reconstruction. Although the Bayesian framework allows for principled uncertainty quantification and automatic hyperparameter learning, existing methods do not scale well for large tensors because of high-dimensional matrix inversions. To this end, we introduce CP-GAMP, a scalable Bayesian CPD algorithm. This algorithm leverages generalized approximate message passing (GAMP) to avoid matrix inversions and incorporates an expectation-maximization routine to jointly infer the tensor rank and noise power. Through multiple experiments, for synthetic 100x100x100 rank 20 tensors with only 20% elements observed, the proposed algorithm reduces runtime by 82.7% compared to the state-of-the-art variational Bayesian CPD method, while maintaining comparable reconstruction accuracy.