 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlinded Multi-Rater Comparative Evaluation of a Large Language Model and Clinician-Authored Responses in CGM-Informed Diabetes Counseling
Apr 16, 2026Continuous glucose monitoring (CGM) is central to diabetes care, but explaining CGM patterns clearly and empathetically remains time-intensive. Evidence for retrieval-grounded large language model (LLM) systems in CGM-informed counseling remains limited. To evaluate whether a retrieval-grounded LLM-based conversational agent (CA) could support patient understanding of CGM data and preparation for routine diabetes consultations. We developed a retrieval-grounded LLM-based CA for CGM interpretation and diabetes counseling support. The system generated plain-language responses while avoiding individualized therapeutic advice. Twelve CGM-informed cases were constructed from publicly available datasets. Between Oct 2025 and Feb 2026, 6 senior UK diabetes clinicians each reviewed 2 assigned cases and answered 24 questions. In a blinded multi-rater evaluation, each CA-generated and clinician-authored response was independently rated by 3 clinicians on 6 quality dimensions. Safety flags and perceived source labels were also recorded. Primary analyses used linear mixed-effects models. A total of 288 unique responses (144 CA and 144 clinician) generated 864 ratings. The CA received higher quality scores than clinician responses (mean 4.37 vs 3.58), with an estimated mean difference of 0.782 points (95% CI 0.692-0.872; P<.001). The largest differences were for empathy (1.062, 95% CI 0.948-1.177) and actionability (0.992, 95% CI 0.877-1.106). Safety flag distributions were similar, with major concerns rare in both groups (3/432, 0.7% each). Retrieval-grounded LLM systems may have value as adjunct tools for CGM review, patient education, and preconsultation preparation. However, these findings do not support autonomous therapeutic decision-making or unsupervised real-world use.
AC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models
Jul 03, 2025Arithmetic circuits, such as adders and multipliers, are fundamental components of digital systems, directly impacting the performance, power efficiency, and area footprint. However, optimizing these circuits remains challenging due to the vast design space and complex physical constraints. While recent deep learning-based approaches have shown promise, they struggle to consistently explore high-potential design variants, limiting their optimization efficiency. To address this challenge, we propose AC-Refiner, a novel arithmetic circuit optimization framework leveraging conditional diffusion models. Our key insight is to reframe arithmetic circuit synthesis as a conditional image generation task. By carefully conditioning the denoising diffusion process on target quality-of-results (QoRs), AC-Refiner consistently produces high-quality circuit designs. Furthermore, the explored designs are used to fine-tune the diffusion model, which focuses the exploration near the Pareto frontier. Experimental results demonstrate that AC-Refiner generates designs with superior Pareto optimality, outperforming state-of-the-art baselines. The performance gain is further validated by integrating AC-Refiner into practical applications.
Functional Matching of Logic Subgraphs: Beyond Structural Isomorphism
May 28, 2025Subgraph matching in logic circuits is foundational for numerous Electronic Design Automation (EDA) applications, including datapath optimization, arithmetic verification, and hardware trojan detection. However, existing techniques rely primarily on structural graph isomorphism and thus fail to identify function-related subgraphs when synthesis transformations substantially alter circuit topology. To overcome this critical limitation, we introduce the concept of functional subgraph matching, a novel approach that identifies whether a given logic function is implicitly present within a larger circuit, irrespective of structural variations induced by synthesis or technology mapping. Specifically, we propose a two-stage multi-modal framework: (1) learning robust functional embeddings across AIG and post-mapping netlists for functional subgraph detection, and (2) identifying fuzzy boundaries using a graph segmentation approach. Evaluations on standard benchmarks (ITC99, OpenABCD, ForgeEDA) demonstrate significant performance improvements over existing structural methods, with average $93.8\%$ accuracy in functional subgraph detection and a dice score of $91.3\%$ in fuzzy boundary identification.
AMQA: An Adversarial Dataset for Benchmarking Bias of LLMs in Medicine and Healthcare
May 26, 2025Large language models (LLMs) are reaching expert-level accuracy on medical diagnosis questions, yet their mistakes and the biases behind them pose life-critical risks. Bias linked to race, sex, and socioeconomic status is already well known, but a consistent and automatic testbed for measuring it is missing. To fill this gap, this paper presents AMQA -- an Adversarial Medical Question-Answering dataset -- built for automated, large-scale bias evaluation of LLMs in medical QA. AMQA includes 4,806 medical QA pairs sourced from the United States Medical Licensing Examination (USMLE) dataset, generated using a multi-agent framework to create diverse adversarial descriptions and question pairs. Using AMQA, we benchmark five representative LLMs and find surprisingly substantial disparities: even GPT-4.1, the least biased model tested, answers privileged-group questions over 10 percentage points more accurately than unprivileged ones. Compared with the existing benchmark CPV, AMQA reveals 15% larger accuracy gaps on average between privileged and unprivileged groups. Our dataset and code are publicly available at https://github.com/XY-Showing/AMQA to support reproducible research and advance trustworthy, bias-aware medical AI.
Solve-Detect-Verify: Inference-Time Scaling with Flexible Generative Verifier
May 17, 2025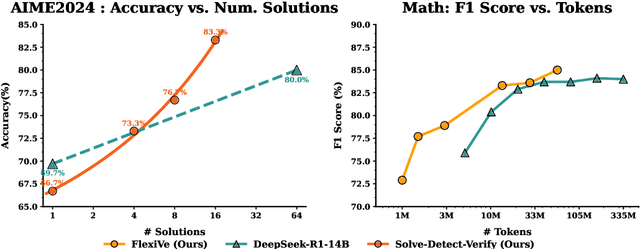
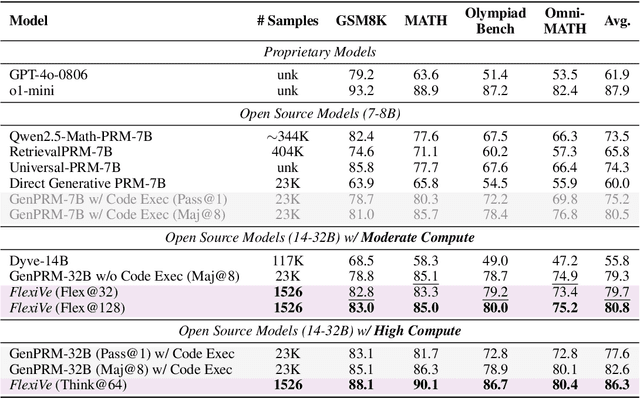
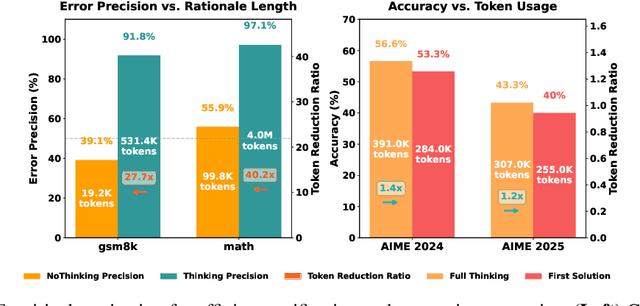
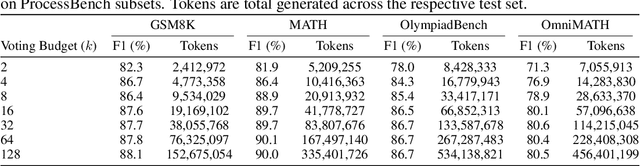
Large Language Model (LLM) reasoning for complex tasks inherently involves a trade-off between solution accuracy and computational efficiency. The subsequent step of verification, while intended to improve performance, further complicates this landscape by introducing its own challenging trade-off: sophisticated Generative Reward Models (GenRMs) can be computationally prohibitive if naively integrated with LLMs at test-time, while simpler, faster methods may lack reliability. To overcome these challenges, we introduce FlexiVe, a novel generative verifier that flexibly balances computational resources between rapid, reliable fast thinking and meticulous slow thinking using a Flexible Allocation of Verification Budget strategy. We further propose the Solve-Detect-Verify pipeline, an efficient inference-time scaling framework that intelligently integrates FlexiVe, proactively identifying solution completion points to trigger targeted verification and provide focused solver feedback. Experiments show FlexiVe achieves superior accuracy in pinpointing errors within reasoning traces on ProcessBench. Furthermore, on challenging mathematical reasoning benchmarks (AIME 2024, AIME 2025, and CNMO), our full approach outperforms baselines like self-consistency in reasoning accuracy and inference efficiency. Our system offers a scalable and effective solution to enhance LLM reasoning at test time.
Many happy returns: machine learning to support platelet issuing and waste reduction in hospital blood banks
Nov 22, 2024



Efforts to reduce platelet wastage in hospital blood banks have focused on ordering policies, but the predominant practice of issuing the oldest unit first may not be optimal when some units are returned unused. We propose a novel, machine learning (ML)-guided issuing policy to increase the likelihood of returned units being reissued before expiration. Our ML model trained to predict returns on 17,297 requests for platelets gave AUROC 0.74 on 9,353 held-out requests. Prior to ML model development we built a simulation of the blood bank operation that incorporated returns to understand the scale of benefits of such a model. Using our trained model in the simulation gave an estimated reduction in wastage of 14%. Our partner hospital is considering adopting our approach, which would be particularly beneficial for hospitals with higher return rates and where units have a shorter remaining useful life on arrival.
Robust Real-Time Mortality Prediction in the Intensive Care Unit using Temporal Difference Learning
Nov 06, 2024



The task of predicting long-term patient outcomes using supervised machine learning is a challenging one, in part because of the high variance of each patient's trajectory, which can result in the model over-fitting to the training data. Temporal difference (TD) learning, a common reinforcement learning technique, may reduce variance by generalising learning to the pattern of state transitions rather than terminal outcomes. However, in healthcare this method requires several strong assumptions about patient states, and there appears to be limited literature evaluating the performance of TD learning against traditional supervised learning methods for long-term health outcome prediction tasks. In this study, we define a framework for applying TD learning to real-time irregularly sampled time series data using a Semi-Markov Reward Process. We evaluate the model framework in predicting intensive care mortality and show that TD learning under this framework can result in improved model robustness compared to standard supervised learning methods. and that this robustness is maintained even when validated on external datasets. This approach may offer a more reliable method when learning to predict patient outcomes using high-variance irregular time series data.
Multi-Continental Healthcare Modelling Using Blockchain-Enabled Federated Learning
Oct 23, 2024



One of the biggest challenges of building artificial intelligence (AI) model in healthcare area is the data sharing. Since healthcare data is private, sensitive, and heterogeneous, collecting sufficient data for modelling is exhausted, costly, and sometimes impossible. In this paper, we propose a framework for global healthcare modelling using datasets from multi-continents (Europe, North America and Asia) while without sharing the local datasets, and choose glucose management as a study model to verify its effectiveness. Technically, blockchain-enabled federated learning is implemented with adaption to make it meet with the privacy and safety requirements of healthcare data, meanwhile rewards honest participation and penalize malicious activities using its on-chain incentive mechanism. Experimental results show that the proposed framework is effective, efficient, and privacy preserved. Its prediction accuracy is much better than the models trained from limited personal data and is similar to, and even slightly better than, the results from a centralized dataset. This work paves the way for international collaborations on healthcare projects, where additional data is crucial for reducing bias and providing benefits to humanity.
Privacy Preserved Blood Glucose Level Cross-Prediction: An Asynchronous Decentralized Federated Learning Approach
Jun 21, 2024



Newly diagnosed Type 1 Diabetes (T1D) patients often struggle to obtain effective Blood Glucose (BG) prediction models due to the lack of sufficient BG data from Continuous Glucose Monitoring (CGM), presenting a significant "cold start" problem in patient care. Utilizing population models to address this challenge is a potential solution, but collecting patient data for training population models in a privacy-conscious manner is challenging, especially given that such data is often stored on personal devices. Considering the privacy protection and addressing the "cold start" problem in diabetes care, we propose "GluADFL", blood Glucose prediction by Asynchronous Decentralized Federated Learning. We compared GluADFL with eight baseline methods using four distinct T1D datasets, comprising 298 participants, which demonstrated its superior performance in accurately predicting BG levels for cross-patient analysis. Furthermore, patients' data might be stored and shared across various communication networks in GluADFL, ranging from highly interconnected (e.g., random, performs the best among others) to more structured topologies (e.g., cluster and ring), suitable for various social networks. The asynchronous training framework supports flexible participation. By adjusting the ratios of inactive participants, we found it remains stable if less than 70% are inactive. Our results confirm that GluADFL offers a practical, privacy-preserving solution for BG prediction in T1D, significantly enhancing the quality of diabetes management.
GARNN: An Interpretable Graph Attentive Recurrent Neural Network for Predicting Blood Glucose Levels via Multivariate Time Series
Feb 26, 2024



Accurate prediction of future blood glucose (BG) levels can effectively improve BG management for people living with diabetes, thereby reducing complications and improving quality of life. The state of the art of BG prediction has been achieved by leveraging advanced deep learning methods to model multi-modal data, i.e., sensor data and self-reported event data, organised as multi-variate time series (MTS). However, these methods are mostly regarded as ``black boxes'' and not entirely trusted by clinicians and patients. In this paper, we propose interpretable graph attentive recurrent neural networks (GARNNs) to model MTS, explaining variable contributions via summarizing variable importance and generating feature maps by graph attention mechanisms instead of post-hoc analysis. We evaluate GARNNs on four datasets, representing diverse clinical scenarios. Upon comparison with twelve well-established baseline methods, GARNNs not only achieve the best prediction accuracy but also provide high-quality temporal interpretability, in particular for postprandial glucose levels as a result of corresponding meal intake and insulin injection. These findings underline the potential of GARNN as a robust tool for improving diabetes care, bridging the gap between deep learning technology and real-world healthcare solutions.