 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoleyGenEx: Unified Video-to-Audio Generation with Multi-Modal Control, Temporal Alignment, and Semantic Precision
Jun 12, 2026We present FoleyGenEx, a unified video-to-audio (VTA) framework integrating multi-modal control, frame-level temporal alignment, and fine-grained semantics, enabling synchronized, versatile audio synthesis for diverse tasks. Existing VTA methods either have multi-modal control but weak temporal alignment or strong alignment but lack reference audio conditioning and semantic precision. FoleyGenEx fills this gap via three core innovations: a conditional injection mechanism for audio-controlled VTA and Foley extension, a multi-modal dynamic masking strategy preserving training synchronization, and an adverb-based data augmentation algorithm leveraging signal processing and large language models to enhance textual supervision with nuanced semantics. Experiments on AudioCaps, VGGSound, and Greatest Hits demonstrate its competitive controllable VTA performance against existing methods. Demo samples are available at https://foleygenex.github.io/FoleyGenEx.
* Accepted by INTERSPEECH 2026
Audio Imitator: Controlling Timbre and Tempo in Video2Audio Synthesis with Audio Reference
Jun 05, 2026Video-to-audio generation has made significant progress in achieving semantic consistency and temporal alignment from silent videos. However, audio contains rich stylistic attributes such as timbre and tempo that are difficult to infer from visual and textual inputs alone. While reference audio can serve as additional conditioning, it is typically treated as a holistic signal, limiting fine-grained style control. We propose AudioIM, an attribute-aware framework that explicitly models timbre and tempo as separate control factors rather than relying on holistic prompt conditioning. Dual encoders extract complementary timbre-related and tempo-related representations, which are injected through global conditioning. A masking-based training strategy enables effective latent prompt conditioning at inference. Experiments on VGGSound show improved style similarity while preserving semantic alignment and synchronization. Audio samples are available at: https://anonymousdemo757.github.io/.
Klear: Unified Multi-Task Audio-Video Joint Generation
Jan 07, 2026Audio-video joint generation has progressed rapidly, yet substantial challenges still remain. Non-commercial approaches still suffer audio-visual asynchrony, poor lip-speech alignment, and unimodal degradation, which can be stemmed from weak audio-visual correspondence modeling, limited generalization, and scarce high-quality dense-caption data. To address these issues, we introduce Klear and delve into three axes--model architecture, training strategy, and data curation. Architecturally, we adopt a single-tower design with unified DiT blocks and an Omni-Full Attention mechanism, achieving tight audio-visual alignment and strong scalability. Training-wise, we adopt a progressive multitask regime--random modality masking to joint optimization across tasks, and a multistage curriculum, yielding robust representations, strengthening A-V aligned world knowledge, and preventing unimodal collapse. For datasets, we present the first large-scale audio-video dataset with dense captions, and introduce a novel automated data-construction pipeline which annotates and filters millions of diverse, high-quality, strictly aligned audio-video-caption triplets. Building on this, Klear scales to large datasets, delivering high-fidelity, semantically and temporally aligned, instruction-following generation in both joint and unimodal settings while generalizing robustly to out-of-distribution scenarios. Across tasks, it substantially outperforms prior methods by a large margin and achieves performance comparable to Veo 3, offering a unified, scalable path toward next-generation audio-video synthesis.
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025
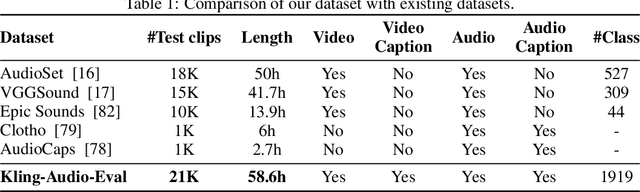
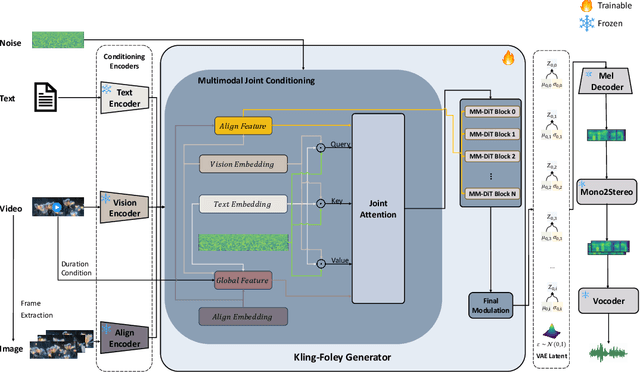
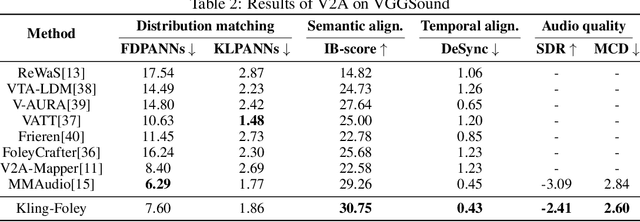
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.