 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular 3D Reconstruction of Interacting Hands via Collision-Aware Factorized Refinements
Nov 01, 2021
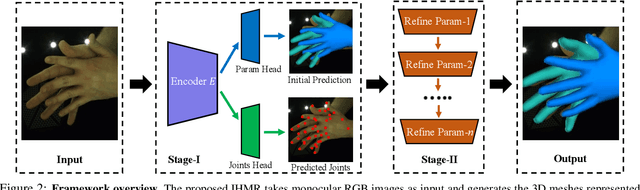
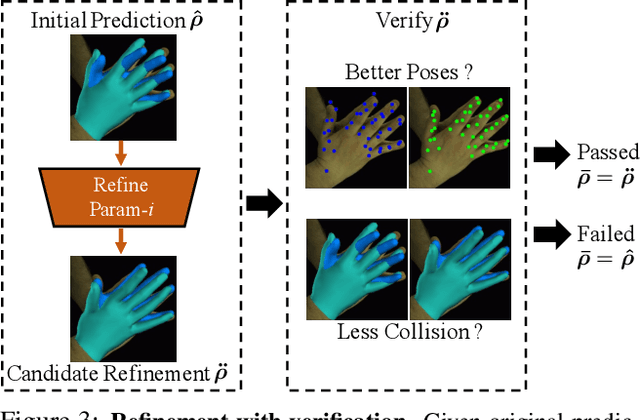
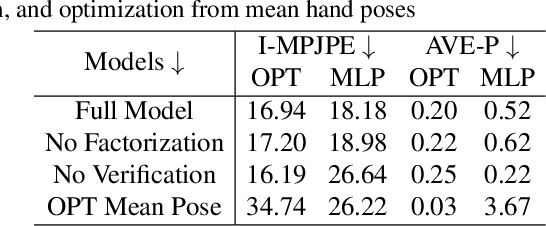
3D interacting hand reconstruction is essential to facilitate human-machine interaction and human behaviors understanding. Previous works in this field either rely on auxiliary inputs such as depth images or they can only handle a single hand if monocular single RGB images are used. Single-hand methods tend to generate collided hand meshes, when applied to closely interacting hands, since they cannot model the interactions between two hands explicitly. In this paper, we make the first attempt to reconstruct 3D interacting hands from monocular single RGB images. Our method can generate 3D hand meshes with both precise 3D poses and minimal collisions. This is made possible via a two-stage framework. Specifically, the first stage adopts a convolutional neural network to generate coarse predictions that tolerate collisions but encourage pose-accurate hand meshes. The second stage progressively ameliorates the collisions through a series of factorized refinements while retaining the preciseness of 3D poses. We carefully investigate potential implementations for the factorized refinement, considering the trade-off between efficiency and accuracy. Extensive quantitative and qualitative results on large-scale datasets such as InterHand2.6M demonstrate the effectiveness of the proposed approach.
STransGAN: An Empirical Study on Transformer in GANs
Oct 25, 2021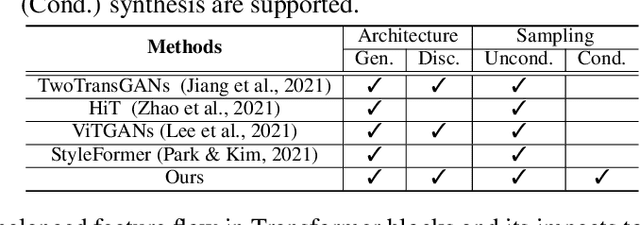
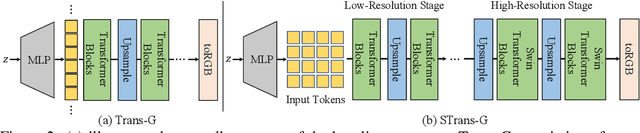
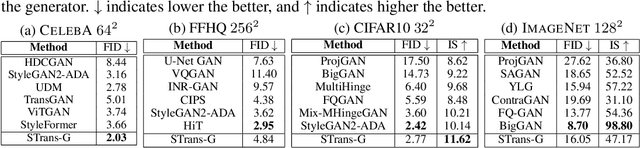

Transformer becomes prevalent in computer vision, especially for high-level vision tasks. However, deploying Transformer in the generative adversarial network (GAN) framework is still an open yet challenging problem. In this paper, we conduct a comprehensive empirical study to investigate the intrinsic properties of Transformer in GAN for high-fidelity image synthesis. Our analysis highlights the importance of feature locality in image generation. We first investigate the effective ways to implement local attention. We then examine the influence of residual connections in self-attention layers and propose a novel way to reduce their negative impacts on learning discriminators and conditional generators. Our study leads to a new design of Transformers in GAN, a convolutional neural network (CNN)-free generator termed as STrans-G, which achieves competitive results in both unconditional and conditional image generations. The Transformer-based discriminator, STrans-D, also significantly reduces its gap against the CNN-based discriminators.
Self-Supervised Representation Learning: Introduction, Advances and Challenges
Oct 18, 2021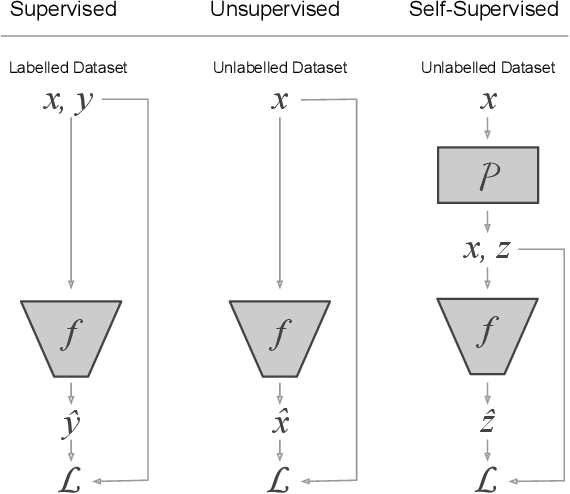
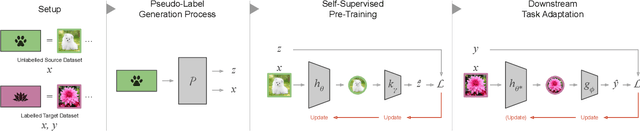
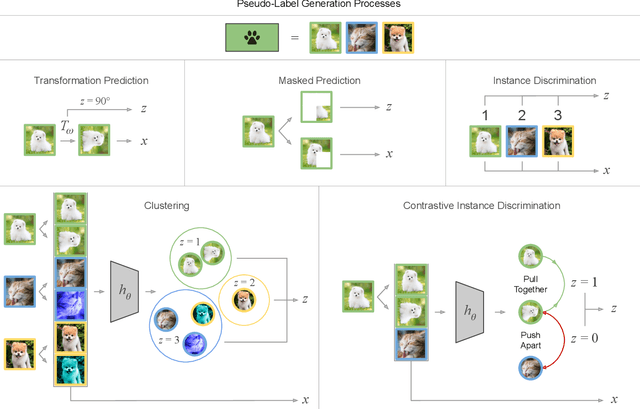

Self-supervised representation learning methods aim to provide powerful deep feature learning without the requirement of large annotated datasets, thus alleviating the annotation bottleneck that is one of the main barriers to practical deployment of deep learning today. These methods have advanced rapidly in recent years, with their efficacy approaching and sometimes surpassing fully supervised pre-training alternatives across a variety of data modalities including image, video, sound, text and graphs. This article introduces this vibrant area including key concepts, the four main families of approach and associated state of the art, and how self-supervised methods are applied to diverse modalities of data. We further discuss practical considerations including workflows, representation transferability, and compute cost. Finally, we survey the major open challenges in the field that provide fertile ground for future work.
Playing for 3D Human Recovery
Oct 14, 2021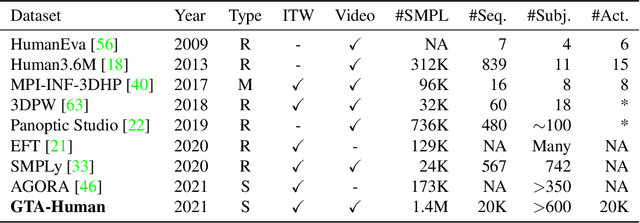

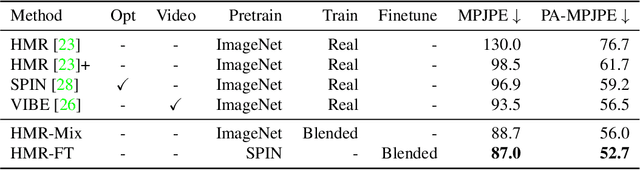
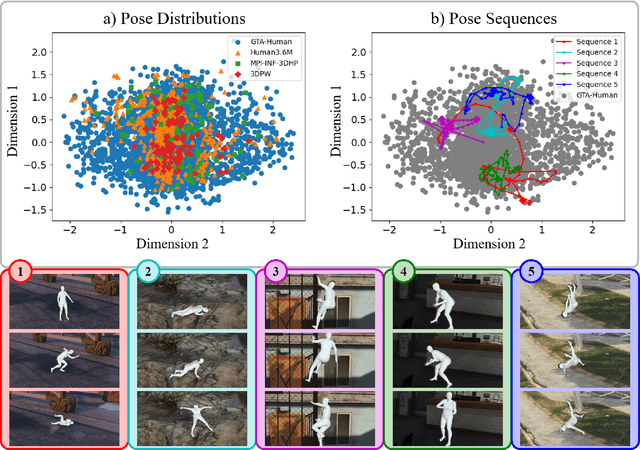
Image- and video-based 3D human recovery (i.e. pose and shape estimation) have achieved substantial progress. However, due to the prohibitive cost of motion capture, existing datasets are often limited in scale and diversity, which hinders the further development of more powerful models. In this work, we obtain massive human sequences as well as their 3D ground truths by playing video games. Specifically, we contribute, GTA-Human, a mega-scale and highly-diverse 3D human dataset generated with the GTA-V game engine. With a rich set of subjects, actions, and scenarios, GTA-Human serves as both an effective training source. Notably, the "unreasonable effectiveness of data" phenomenon is validated in 3D human recovery using our game-playing data. A simple frame-based baseline trained on GTA-Human already outperforms more sophisticated methods by a large margin; for video-based methods, GTA-Human demonstrates superiority over even the in-domain training set. We extend our study to larger models to observe the same consistent improvements, and the study on supervision signals suggests the rich collection of SMPL annotations is key. Furthermore, equipped with the diverse annotations in GTA-Human, we systematically investigate the performance of various methods under a wide spectrum of real-world variations, e.g. camera angles, poses, and occlusions. We hope our work could pave way for scaling up 3D human recovery to the real world.
Temporally Consistent Video Colorization with Deep Feature Propagation and Self-regularization Learning
Oct 09, 2021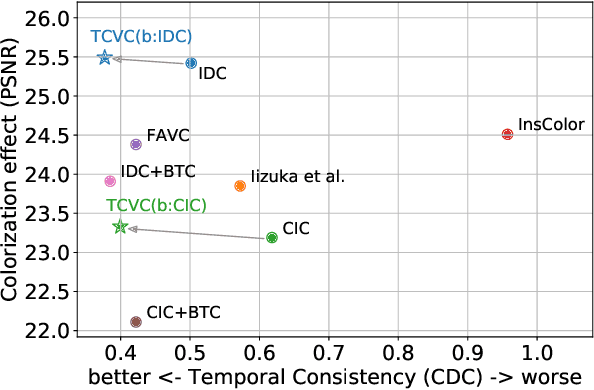
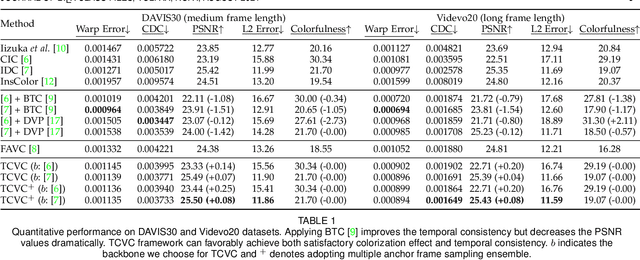

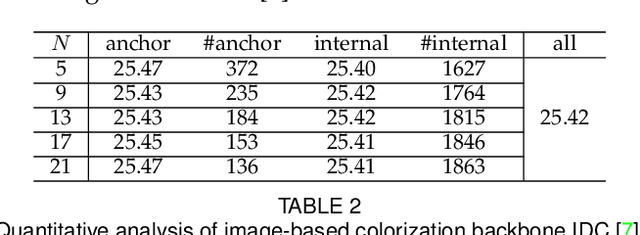
Video colorization is a challenging and highly ill-posed problem. Although recent years have witnessed remarkable progress in single image colorization, there is relatively less research effort on video colorization and existing methods always suffer from severe flickering artifacts (temporal inconsistency) or unsatisfying colorization performance. We address this problem from a new perspective, by jointly considering colorization and temporal consistency in a unified framework. Specifically, we propose a novel temporally consistent video colorization framework (TCVC). TCVC effectively propagates frame-level deep features in a bidirectional way to enhance the temporal consistency of colorization. Furthermore, TCVC introduces a self-regularization learning (SRL) scheme to minimize the prediction difference obtained with different time steps. SRL does not require any ground-truth color videos for training and can further improve temporal consistency. Experiments demonstrate that our method can not only obtain visually pleasing colorized video, but also achieve clearly better temporal consistency than state-of-the-art methods.
Learning to Prompt for Vision-Language Models
Sep 21, 2021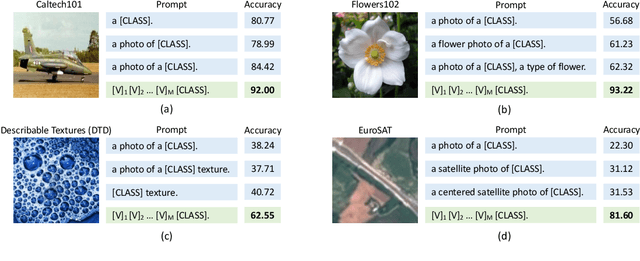
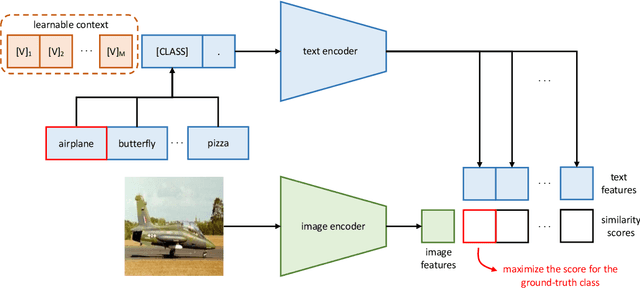
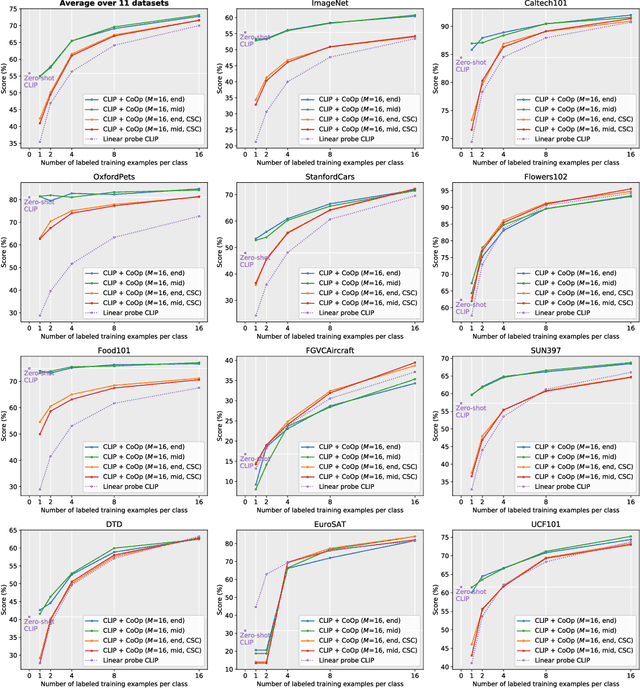
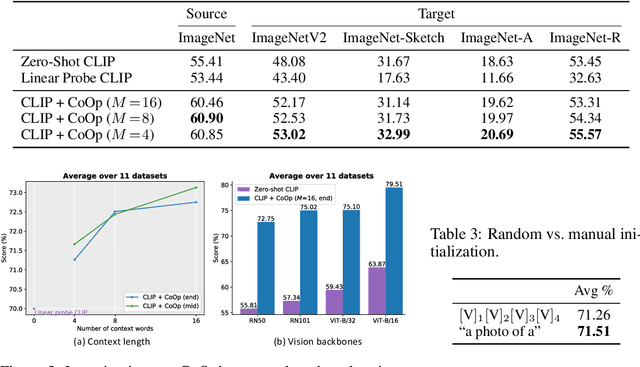
Vision-language pre-training has recently emerged as a promising alternative for representation learning. It shifts from the tradition of using images and discrete labels for learning a fixed set of weights, seen as visual concepts, to aligning images and raw text for two separate encoders. Such a paradigm benefits from a broader source of supervision and allows zero-shot transfer to downstream tasks since visual concepts can be diametrically generated from natural language, known as prompt. In this paper, we identify that a major challenge of deploying such models in practice is prompt engineering. This is because designing a proper prompt, especially for context words surrounding a class name, requires domain expertise and typically takes a significant amount of time for words tuning since a slight change in wording could have a huge impact on performance. Moreover, different downstream tasks require specific designs, further hampering the efficiency of deployment. To overcome this challenge, we propose a novel approach named context optimization (CoOp). The main idea is to model context in prompts using continuous representations and perform end-to-end learning from data while keeping the pre-trained parameters fixed. In this way, the design of task-relevant prompts can be fully automated. Experiments on 11 datasets show that CoOp effectively turns pre-trained vision-language models into data-efficient visual learners, requiring as few as one or two shots to beat hand-crafted prompts with a decent margin and able to gain significant improvements when using more shots (e.g., at 16 shots the average gain is around 17% with the highest reaching over 50%). CoOp also exhibits strong robustness to distribution shift.
ReconfigISP: Reconfigurable Camera Image Processing Pipeline
Sep 10, 2021

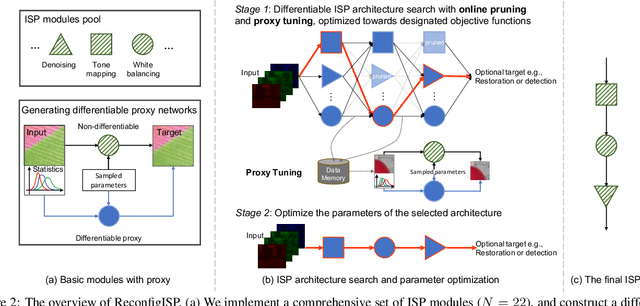
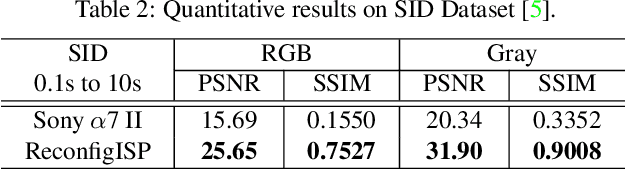
Image Signal Processor (ISP) is a crucial component in digital cameras that transforms sensor signals into images for us to perceive and understand. Existing ISP designs always adopt a fixed architecture, e.g., several sequential modules connected in a rigid order. Such a fixed ISP architecture may be suboptimal for real-world applications, where camera sensors, scenes and tasks are diverse. In this study, we propose a novel Reconfigurable ISP (ReconfigISP) whose architecture and parameters can be automatically tailored to specific data and tasks. In particular, we implement several ISP modules, and enable backpropagation for each module by training a differentiable proxy, hence allowing us to leverage the popular differentiable neural architecture search and effectively search for the optimal ISP architecture. A proxy tuning mechanism is adopted to maintain the accuracy of proxy networks in all cases. Extensive experiments conducted on image restoration and object detection, with different sensors, light conditions and efficiency constraints, validate the effectiveness of ReconfigISP. Only hundreds of parameters need tuning for every task.
Talk-to-Edit: Fine-Grained Facial Editing via Dialog
Sep 09, 2021


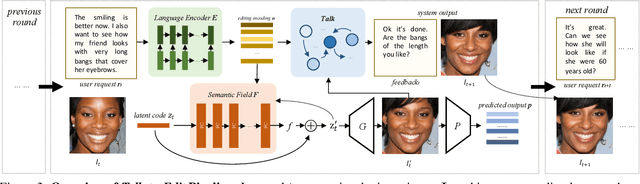
Facial editing is an important task in vision and graphics with numerous applications. However, existing works are incapable to deliver a continuous and fine-grained editing mode (e.g., editing a slightly smiling face to a big laughing one) with natural interactions with users. In this work, we propose Talk-to-Edit, an interactive facial editing framework that performs fine-grained attribute manipulation through dialog between the user and the system. Our key insight is to model a continual "semantic field" in the GAN latent space. 1) Unlike previous works that regard the editing as traversing straight lines in the latent space, here the fine-grained editing is formulated as finding a curving trajectory that respects fine-grained attribute landscape on the semantic field. 2) The curvature at each step is location-specific and determined by the input image as well as the users' language requests. 3) To engage the users in a meaningful dialog, our system generates language feedback by considering both the user request and the current state of the semantic field. We also contribute CelebA-Dialog, a visual-language facial editing dataset to facilitate large-scale study. Specifically, each image has manually annotated fine-grained attribute annotations as well as template-based textual descriptions in natural language. Extensive quantitative and qualitative experiments demonstrate the superiority of our framework in terms of 1) the smoothness of fine-grained editing, 2) the identity/attribute preservation, and 3) the visual photorealism and dialog fluency. Notably, user study validates that our overall system is consistently favored by around 80% of the participants. Our project page is https://www.mmlab-ntu.com/project/talkedit/.
3D Human Texture Estimation from a Single Image with Transformers
Sep 06, 2021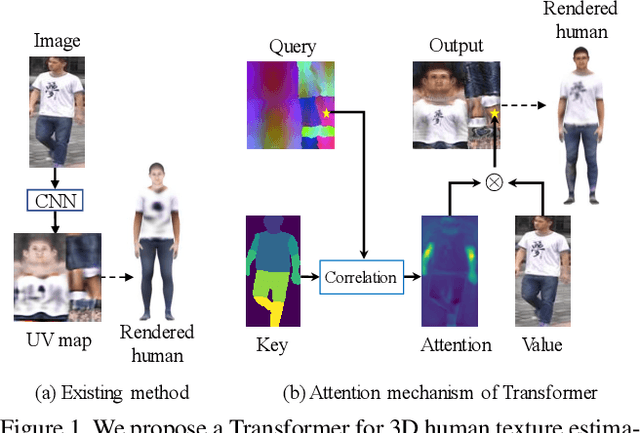
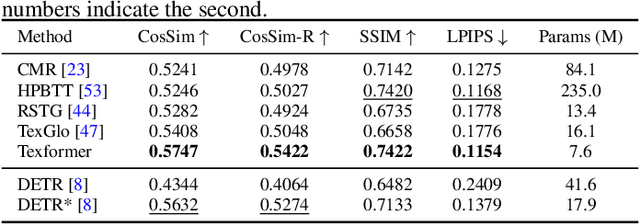
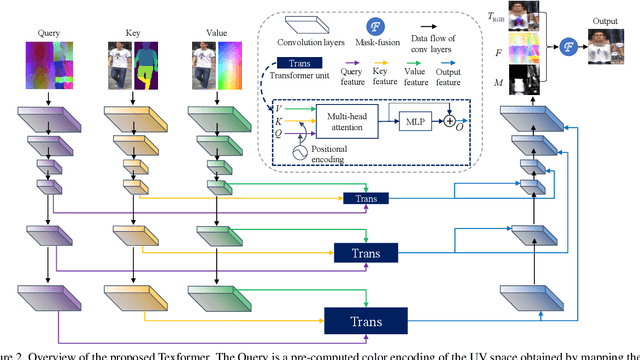
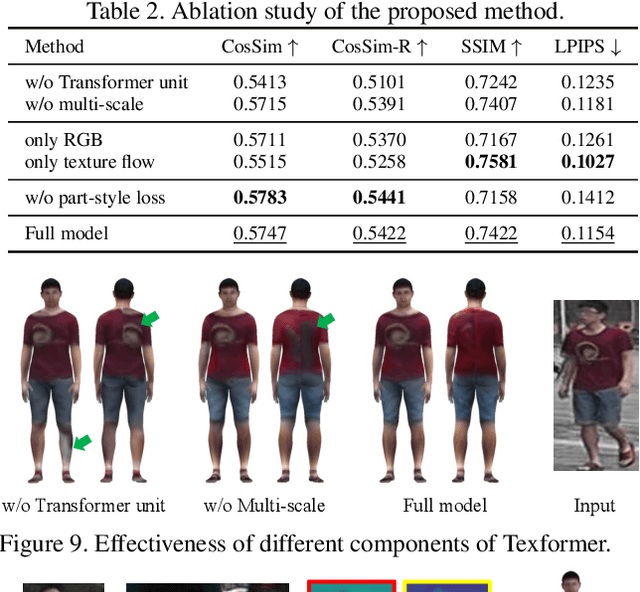
We propose a Transformer-based framework for 3D human texture estimation from a single image. The proposed Transformer is able to effectively exploit the global information of the input image, overcoming the limitations of existing methods that are solely based on convolutional neural networks. In addition, we also propose a mask-fusion strategy to combine the advantages of the RGB-based and texture-flow-based models. We further introduce a part-style loss to help reconstruct high-fidelity colors without introducing unpleasant artifacts. Extensive experiments demonstrate the effectiveness of the proposed method against state-of-the-art 3D human texture estimation approaches both quantitatively and qualitatively.
* ICCV 2021 Oral, Project: https://www.mmlab-ntu.com/project/texformer, Code: https://github.com/xuxy09/Texformer
K-Net: Towards Unified Image Segmentation
Jun 28, 2021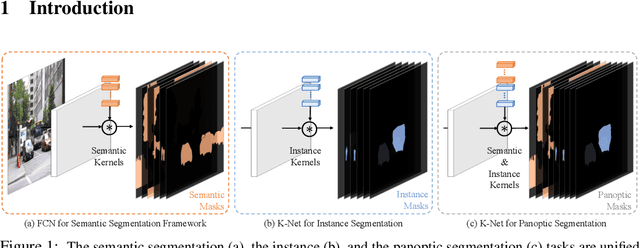
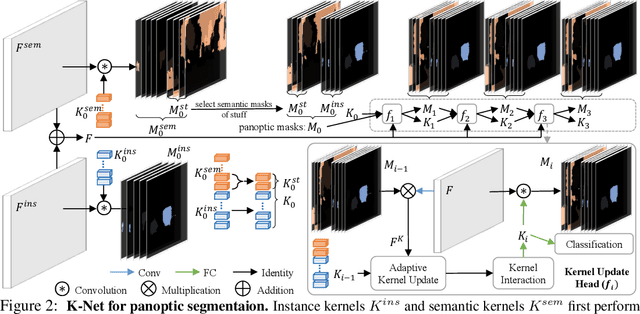
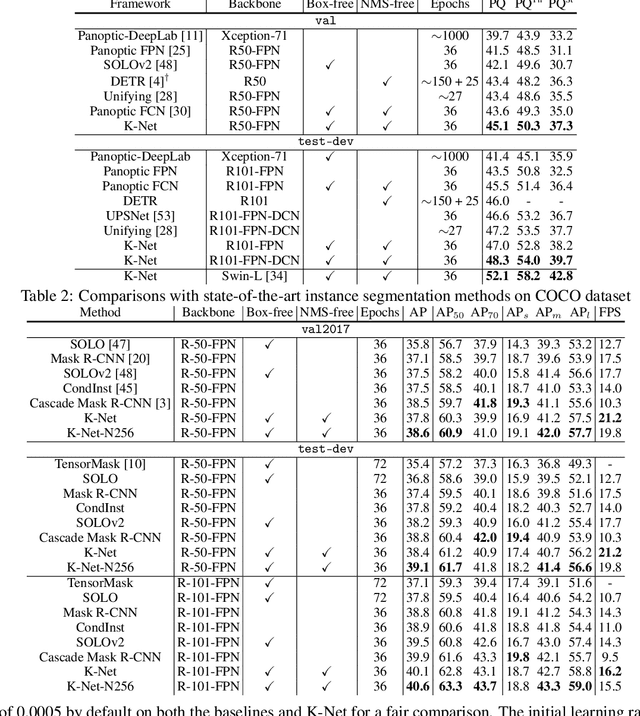

Semantic, instance, and panoptic segmentations have been addressed using different and specialized frameworks despite their underlying connections. This paper presents a unified, simple, and effective framework for these essentially similar tasks. The framework, named K-Net, segments both instances and semantic categories consistently by a group of learnable kernels, where each kernel is responsible for generating a mask for either a potential instance or a stuff class. To remedy the difficulties of distinguishing various instances, we propose a kernel update strategy that enables each kernel dynamic and conditional on its meaningful group in the input image. K-Net can be trained in an end-to-end manner with bipartite matching, and its training and inference are naturally NMS-free and box-free. Without bells and whistles, K-Net surpasses all previous state-of-the-art single-model results of panoptic segmentation on MS COCO and semantic segmentation on ADE20K with 52.1% PQ and 54.3% mIoU, respectively. Its instance segmentation performance is also on par with Cascade Mask R-CNNon MS COCO with 60%-90% faster inference speeds. Code and models will be released at https://github.com/open-mmlab/mmdetection.