 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Persuasive Language Generation for Automated Marketing
Feb 24, 2025



This paper develops an agentic framework that employs large language models (LLMs) to automate the generation of persuasive and grounded marketing content, using real estate listing descriptions as our focal application domain. Our method is designed to align the generated content with user preferences while highlighting useful factual attributes. This agent consists of three key modules: (1) Grounding Module, mimicking expert human behavior to predict marketable features; (2) Personalization Module, aligning content with user preferences; (3) Marketing Module, ensuring factual accuracy and the inclusion of localized features. We conduct systematic human-subject experiments in the domain of real estate marketing, with a focus group of potential house buyers. The results demonstrate that marketing descriptions generated by our approach are preferred over those written by human experts by a clear margin. Our findings suggest a promising LLM-based agentic framework to automate large-scale targeted marketing while ensuring responsible generation using only facts.
Beyond Reward Hacking: Causal Rewards for Large Language Model Alignment
Jan 16, 2025



Recent advances in large language models (LLMs) have demonstrated significant progress in performing complex tasks. While Reinforcement Learning from Human Feedback (RLHF) has been effective in aligning LLMs with human preferences, it is susceptible to spurious correlations in reward modeling. Consequently, it often introduces biases-such as length bias, sycophancy, conceptual bias, and discrimination that hinder the model's ability to capture true causal relationships. To address this, we propose a novel causal reward modeling approach that integrates causal inference to mitigate these spurious correlations. Our method enforces counterfactual invariance, ensuring reward predictions remain consistent when irrelevant variables are altered. Through experiments on both synthetic and real-world datasets, we show that our approach mitigates various types of spurious correlations effectively, resulting in more reliable and fair alignment of LLMs with human preferences. As a drop-in enhancement to the existing RLHF workflow, our causal reward modeling provides a practical way to improve the trustworthiness and fairness of LLM finetuning.
GRAPE: Generalizing Robot Policy via Preference Alignment
Nov 28, 2024



Despite the recent advancements of vision-language-action (VLA) models on a variety of robotics tasks, they suffer from critical issues such as poor generalizability to unseen tasks, due to their reliance on behavior cloning exclusively from successful rollouts. Furthermore, they are typically fine-tuned to replicate demonstrations collected by experts under different settings, thus introducing distribution bias and limiting their adaptability to diverse manipulation objectives, such as efficiency, safety, and task completion. To bridge this gap, we introduce GRAPE: Generalizing Robot Policy via Preference Alignment. Specifically, GRAPE aligns VLAs on a trajectory level and implicitly models reward from both successful and failure trials to boost generalizability to diverse tasks. Moreover, GRAPE breaks down complex manipulation tasks to independent stages and automatically guides preference modeling through customized spatiotemporal constraints with keypoints proposed by a large vision-language model. Notably, these constraints are flexible and can be customized to align the model with varying objectives, such as safety, efficiency, or task success. We evaluate GRAPE across a diverse array of tasks in both real-world and simulated environments. Experimental results demonstrate that GRAPE enhances the performance of state-of-the-art VLA models, increasing success rates on in-domain and unseen manipulation tasks by 51.79% and 60.36%, respectively. Additionally, GRAPE can be aligned with various objectives, such as safety and efficiency, reducing collision rates by 44.31% and rollout step-length by 11.15%, respectively. All code, models, and data are available at https://grape-vla.github.io/
Multi-IF: Benchmarking LLMs on Multi-Turn and Multilingual Instructions Following
Oct 21, 2024Large Language Models (LLMs) have demonstrated impressive capabilities in various tasks, including instruction following, which is crucial for aligning model outputs with user expectations. However, evaluating LLMs' ability to follow instructions remains challenging due to the complexity and subjectivity of human language. Current benchmarks primarily focus on single-turn, monolingual instructions, which do not adequately reflect the complexities of real-world applications that require handling multi-turn and multilingual interactions. To address this gap, we introduce Multi-IF, a new benchmark designed to assess LLMs' proficiency in following multi-turn and multilingual instructions. Multi-IF, which utilizes a hybrid framework combining LLM and human annotators, expands upon the IFEval by incorporating multi-turn sequences and translating the English prompts into another 7 languages, resulting in a dataset of 4,501 multilingual conversations, where each has three turns. Our evaluation of 14 state-of-the-art LLMs on Multi-IF reveals that it presents a significantly more challenging task than existing benchmarks. All the models tested showed a higher rate of failure in executing instructions correctly with each additional turn. For example, o1-preview drops from 0.877 at the first turn to 0.707 at the third turn in terms of average accuracy over all languages. Moreover, languages with non-Latin scripts (Hindi, Russian, and Chinese) generally exhibit higher error rates, suggesting potential limitations in the models' multilingual capabilities. We release Multi-IF prompts and the evaluation code base to encourage further research in this critical area.
Preference Optimization with Multi-Sample Comparisons
Oct 16, 2024Recent advancements in generative models, particularly large language models (LLMs) and diffusion models, have been driven by extensive pretraining on large datasets followed by post-training. However, current post-training methods such as reinforcement learning from human feedback (RLHF) and direct alignment from preference methods (DAP) primarily utilize single-sample comparisons. These approaches often fail to capture critical characteristics such as generative diversity and bias, which are more accurately assessed through multiple samples. To address these limitations, we introduce a novel approach that extends post-training to include multi-sample comparisons. To achieve this, we propose Multi-sample Direct Preference Optimization (mDPO) and Multi-sample Identity Preference Optimization (mIPO). These methods improve traditional DAP methods by focusing on group-wise characteristics. Empirically, we demonstrate that multi-sample comparison is more effective in optimizing collective characteristics~(e.g., diversity and bias) for generative models than single-sample comparison. Additionally, our findings suggest that multi-sample comparisons provide a more robust optimization framework, particularly for dataset with label noise.
MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?
Jul 05, 2024



While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output. To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes. To address this issue, we introduce MJ-Bench, a novel benchmark which incorporates a comprehensive preference dataset to evaluate multimodal judges in providing feedback for image generation models across four key perspectives: alignment, safety, image quality, and bias. Specifically, we evaluate a large variety of multimodal judges including smaller-sized CLIP-based scoring models, open-source VLMs (e.g. LLaVA family), and close-source VLMs (e.g. GPT-4o, Claude 3) on each decomposed subcategory of our preference dataset. Experiments reveal that close-source VLMs generally provide better feedback, with GPT-4o outperforming other judges in average. Compared with open-source VLMs, smaller-sized scoring models can provide better feedback regarding text-image alignment and image quality, while VLMs provide more accurate feedback regarding safety and generation bias due to their stronger reasoning capabilities. Further studies in feedback scale reveal that VLM judges can generally provide more accurate and stable feedback in natural language (Likert-scale) than numerical scales. Notably, human evaluations on end-to-end fine-tuned models using separate feedback from these multimodal judges provide similar conclusions, further confirming the effectiveness of MJ-Bench. All data, code, models are available at https://huggingface.co/MJ-Bench.
Beyond Reverse KL: Generalizing Direct Preference Optimization with Diverse Divergence Constraints
Sep 28, 2023The increasing capabilities of large language models (LLMs) raise opportunities for artificial general intelligence but concurrently amplify safety concerns, such as potential misuse of AI systems, necessitating effective AI alignment. Reinforcement Learning from Human Feedback (RLHF) has emerged as a promising pathway towards AI alignment but brings forth challenges due to its complexity and dependence on a separate reward model. Direct Preference Optimization (DPO) has been proposed as an alternative, and it remains equivalent to RLHF under the reverse KL regularization constraint. This paper presents $f$-DPO, a generalized approach to DPO by incorporating diverse divergence constraints. We show that under certain $f$-divergences, including Jensen-Shannon divergence, forward KL divergences and $\alpha$-divergences, the complex relationship between the reward and optimal policy can also be simplified by addressing the Karush-Kuhn-Tucker conditions. This eliminates the need for estimating the normalizing constant in the Bradley-Terry model and enables a tractable mapping between the reward function and the optimal policy. Our approach optimizes LLMs to align with human preferences in a more efficient and supervised manner under a broad set of divergence constraints. Empirically, adopting these divergences ensures a balance between alignment performance and generation diversity. Importantly, $f$-DPO outperforms PPO-based methods in divergence efficiency, and divergence constraints directly influence expected calibration error (ECE).
Follow-ups Also Matter: Improving Contextual Bandits via Post-serving Contexts
Sep 25, 2023



Standard contextual bandit problem assumes that all the relevant contexts are observed before the algorithm chooses an arm. This modeling paradigm, while useful, often falls short when dealing with problems in which valuable additional context can be observed after arm selection. For example, content recommendation platforms like Youtube, Instagram, Tiktok also observe valuable follow-up information pertinent to the user's reward after recommendation (e.g., how long the user stayed, what is the user's watch speed, etc.). To improve online learning efficiency in these applications, we study a novel contextual bandit problem with post-serving contexts and design a new algorithm, poLinUCB, that achieves tight regret under standard assumptions. Core to our technical proof is a robustified and generalized version of the well-known Elliptical Potential Lemma (EPL), which can accommodate noise in data. Such robustification is necessary for tackling our problem, and we believe it could also be of general interest. Extensive empirical tests on both synthetic and real-world datasets demonstrate the significant benefit of utilizing post-serving contexts as well as the superior performance of our algorithm over the state-of-the-art approaches.
Active Policy Improvement from Multiple Black-box Oracles
Jun 17, 2023Reinforcement learning (RL) has made significant strides in various complex domains. However, identifying an effective policy via RL often necessitates extensive exploration. Imitation learning aims to mitigate this issue by using expert demonstrations to guide exploration. In real-world scenarios, one often has access to multiple suboptimal black-box experts, rather than a single optimal oracle. These experts do not universally outperform each other across all states, presenting a challenge in actively deciding which oracle to use and in which state. We introduce MAPS and MAPS-SE, a class of policy improvement algorithms that perform imitation learning from multiple suboptimal oracles. In particular, MAPS actively selects which of the oracles to imitate and improve their value function estimates, and MAPS-SE additionally leverages an active state exploration criterion to determine which states one should explore. We provide a comprehensive theoretical analysis and demonstrate that MAPS and MAPS-SE enjoy sample efficiency advantage over the state-of-the-art policy improvement algorithms. Empirical results show that MAPS-SE significantly accelerates policy optimization via state-wise imitation learning from multiple oracles across a broad spectrum of control tasks in the DeepMind Control Suite. Our code is publicly available at: https://github.com/ripl/maps.
Teaching an Active Learner with Contrastive Examples
Oct 29, 2021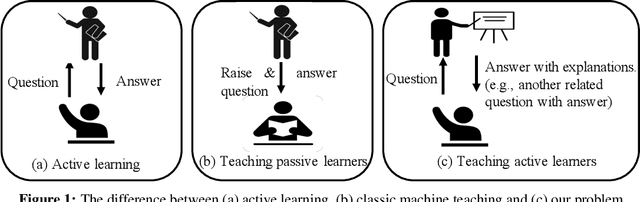
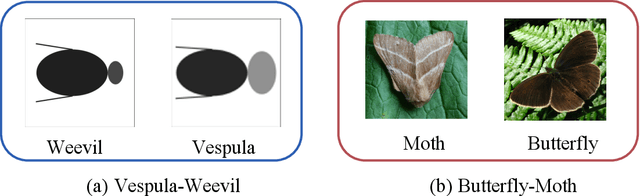
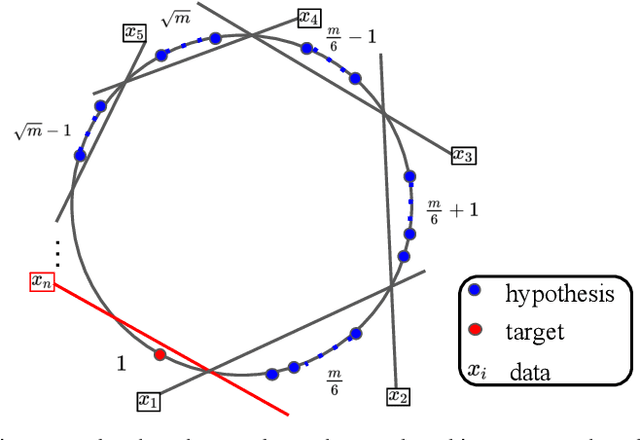
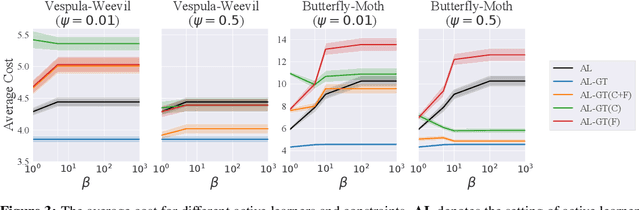
We study the problem of active learning with the added twist that the learner is assisted by a helpful teacher. We consider the following natural interaction protocol: At each round, the learner proposes a query asking for the label of an instance $x^q$, the teacher provides the requested label $\{x^q, y^q\}$ along with explanatory information to guide the learning process. In this paper, we view this information in the form of an additional contrastive example ($\{x^c, y^c\}$) where $x^c$ is picked from a set constrained by $x^q$ (e.g., dissimilar instances with the same label). Our focus is to design a teaching algorithm that can provide an informative sequence of contrastive examples to the learner to speed up the learning process. We show that this leads to a challenging sequence optimization problem where the algorithm's choices at a given round depend on the history of interactions. We investigate an efficient teaching algorithm that adaptively picks these contrastive examples. We derive strong performance guarantees for our algorithm based on two problem-dependent parameters and further show that for specific types of active learners (e.g., a generalized binary search learner), the proposed teaching algorithm exhibits strong approximation guarantees. Finally, we illustrate our bounds and demonstrate the effectiveness of our teaching framework via two numerical case studies.