 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Training and Decoding For End-to-end Speech Recognition Using Lattice-free MMI
Dec 30, 2021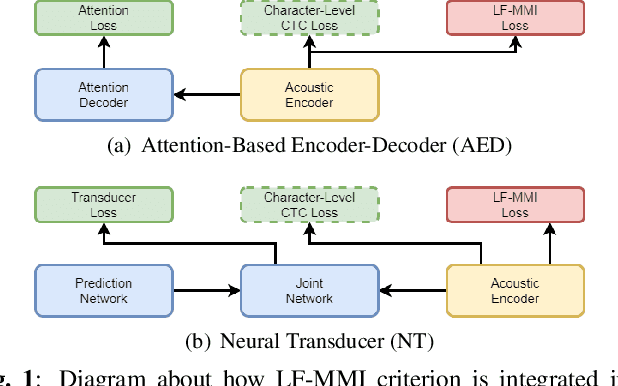
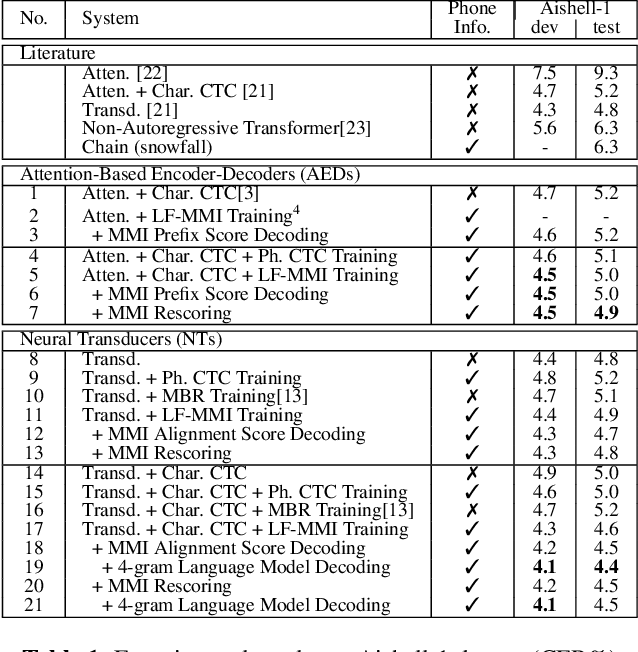
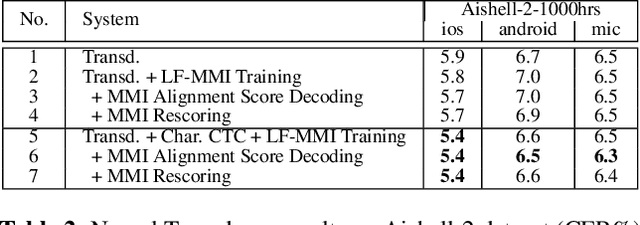
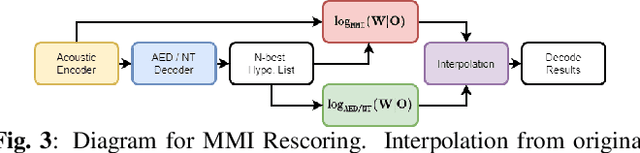
Recently, End-to-End (E2E) frameworks have achieved remarkable results on various Automatic Speech Recognition (ASR) tasks. However, Lattice-Free Maximum Mutual Information (LF-MMI), as one of the discriminative training criteria that show superior performance in hybrid ASR systems, is rarely adopted in E2E ASR frameworks. In this work, we propose a novel approach to integrate LF-MMI criterion into E2E ASR frameworks in both training and decoding stages. The proposed approach shows its effectiveness on two of the most widely used E2E frameworks including Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Experiments suggest that the introduction of the LF-MMI criterion consistently leads to significant performance improvements on various datasets and different E2E ASR frameworks. The best of our models achieves competitive CER of 4.1\% / 4.4\% on Aishell-1 dev/test set; we also achieve significant error reduction on Aishell-2 and Librispeech datasets over strong baselines.
Detect what you want: Target Sound Detection
Dec 19, 2021
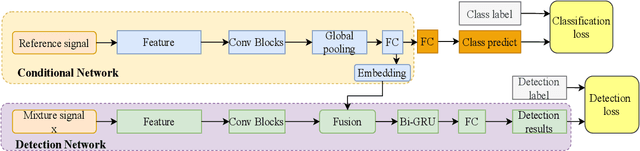
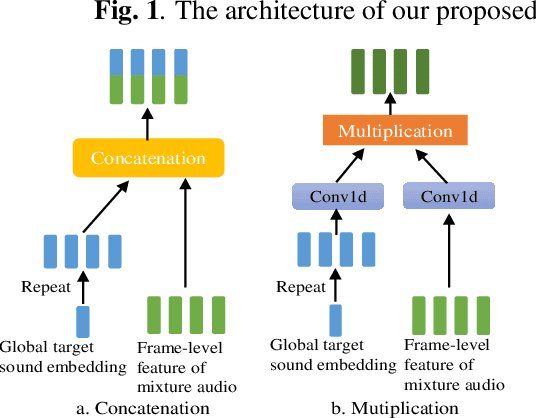
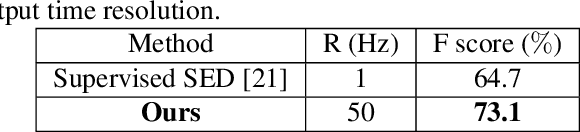
Human beings can perceive a target sound that we are interested in from a multi-source environment by the selective auditory attention, however, such functionality was hardly ever explored in machine hearing.This paper address the target sound detection (TSD), which aims to detect the target sound signal from a mixture audio when a target sound's reference audio is given.We present a novel target sound detection network (TSDNet) which consists of two main parts: A conditional and a detection network. The former aims at generating a sound-discriminative conditional embedding vector representing the global information of the target sound. The latter takes both the mixture audio and the conditional embedding vector as inputs, and produces the detection result. These two networks can be jointly optimized with a multi-task learning approach to further improve the performance. In addition, we study both supervised and weakly supervised strategies to train TSDNet.To evaluate our methods, we build a target sound detection dataset (TSD Dataset) based on URBAN-SED and URBAN-SOUND8K datasets. Experimental results indicate our system can get better performance than universal sound event detection.
Joint Modeling of Code-Switched and Monolingual ASR via Conditional Factorization
Nov 29, 2021
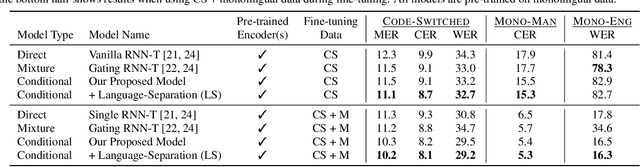
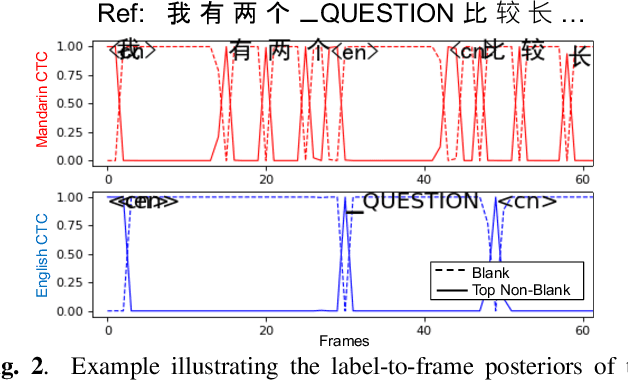
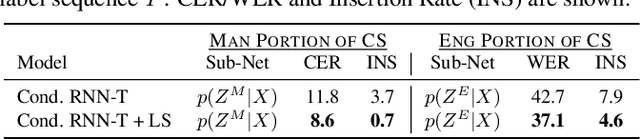
Conversational bilingual speech encompasses three types of utterances: two purely monolingual types and one intra-sententially code-switched type. In this work, we propose a general framework to jointly model the likelihoods of the monolingual and code-switch sub-tasks that comprise bilingual speech recognition. By defining the monolingual sub-tasks with label-to-frame synchronization, our joint modeling framework can be conditionally factorized such that the final bilingual output, which may or may not be code-switched, is obtained given only monolingual information. We show that this conditionally factorized joint framework can be modeled by an end-to-end differentiable neural network. We demonstrate the efficacy of our proposed model on bilingual Mandarin-English speech recognition across both monolingual and code-switched corpora.
Simple Attention Module based Speaker Verification with Iterative noisy label detection
Oct 13, 2021
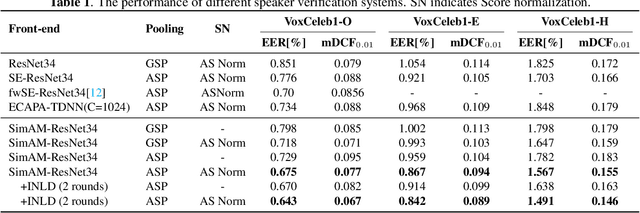
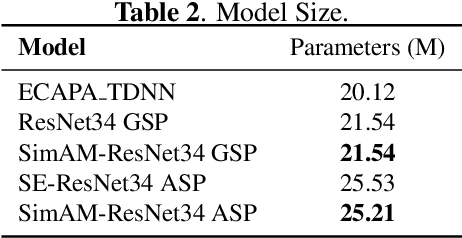
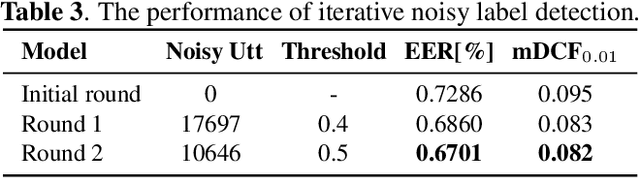
Recently, the attention mechanism such as squeeze-and-excitation module (SE) and convolutional block attention module (CBAM) has achieved great success in deep learning-based speaker verification system. This paper introduces an alternative effective yet simple one, i.e., simple attention module (SimAM), for speaker verification. The SimAM module is a plug-and-play module without extra modal parameters. In addition, we propose a noisy label detection method to iteratively filter out the data samples with a noisy label from the training data, considering that a large-scale dataset labeled with human annotation or other automated processes may contain noisy labels. Data with the noisy label may over parameterize a deep neural network (DNN) and result in a performance drop due to the memorization effect of the DNN. Experiments are conducted on VoxCeleb dataset. The speaker verification model with SimAM achieves the 0.675% equal error rate (EER) on VoxCeleb1 original test trials. Our proposed iterative noisy label detection method further reduces the EER to 0.643%.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021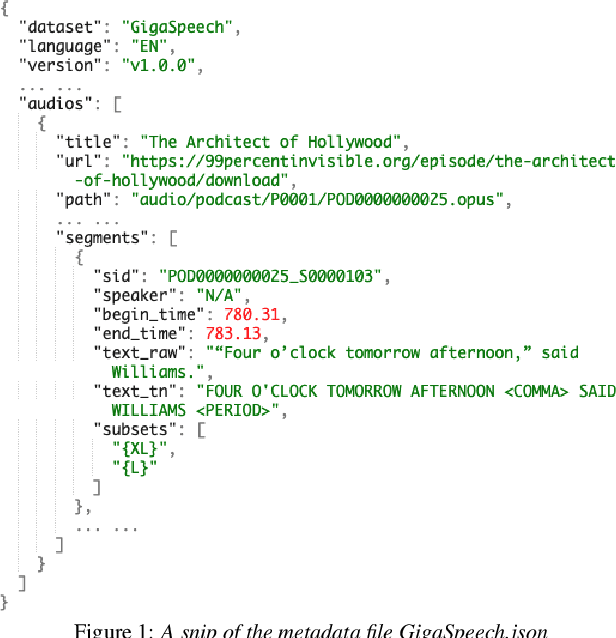
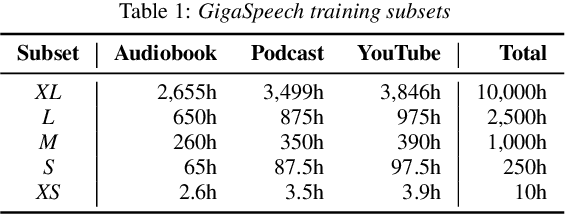
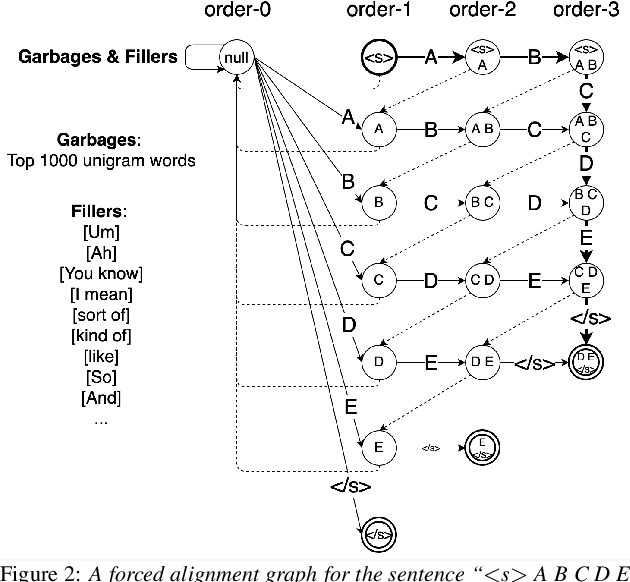
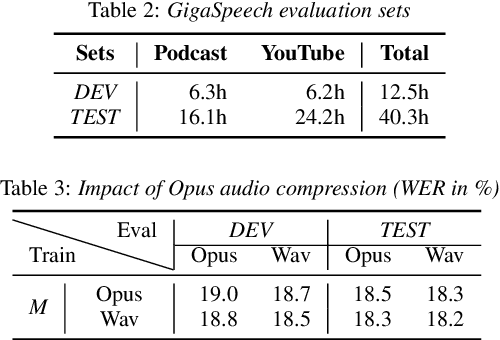
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
Spoken Style Learning with Multi-modal Hierarchical Context Encoding for Conversational Text-to-Speech Synthesis
Jun 11, 2021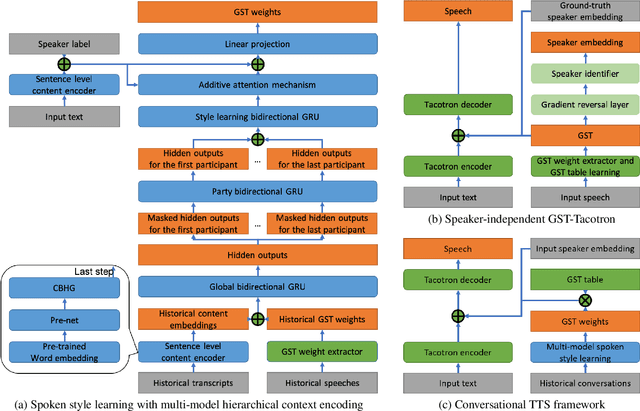

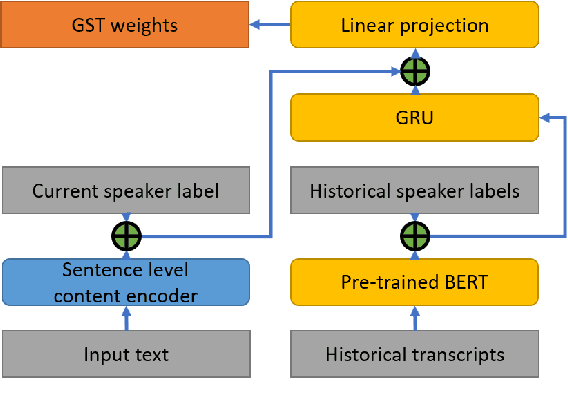

For conversational text-to-speech (TTS) systems, it is vital that the systems can adjust the spoken styles of synthesized speech according to different content and spoken styles in historical conversations. However, the study about learning spoken styles from historical conversations is still in its infancy. Only the transcripts of the historical conversations are considered, which neglects the spoken styles in historical speeches. Moreover, only the interactions of the global aspect between speakers are modeled, missing the party aspect self interactions inside each speaker. In this paper, to achieve better spoken style learning for conversational TTS, we propose a spoken style learning approach with multi-modal hierarchical context encoding. The textual information and spoken styles in the historical conversations are processed through multiple hierarchical recurrent neural networks to learn the spoken style related features in global and party aspects. The attention mechanism is further employed to summarize these features into a conversational context encoding. Experimental results demonstrate the effectiveness of our proposed approach, which outperform a baseline method using context encoding learnt only from the transcripts in global aspects, with MOS score on the naturalness of synthesized speech increasing from 3.138 to 3.408 and ABX preference rate exceeding the baseline method by 36.45%.
Raw Waveform Encoder with Multi-Scale Globally Attentive Locally Recurrent Networks for End-to-End Speech Recognition
Jun 08, 2021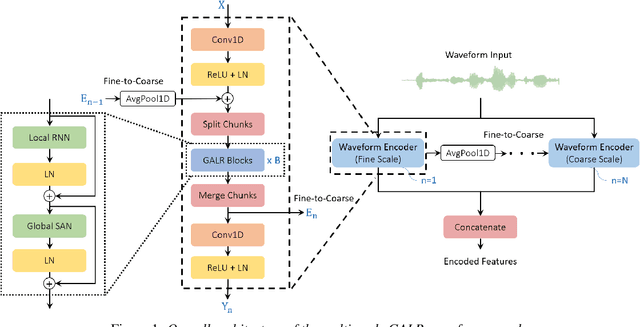
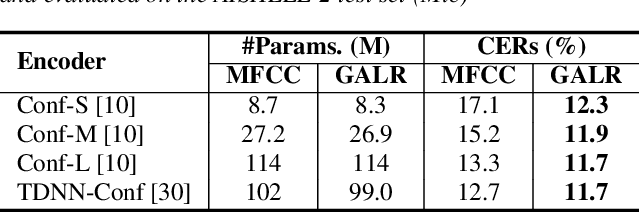
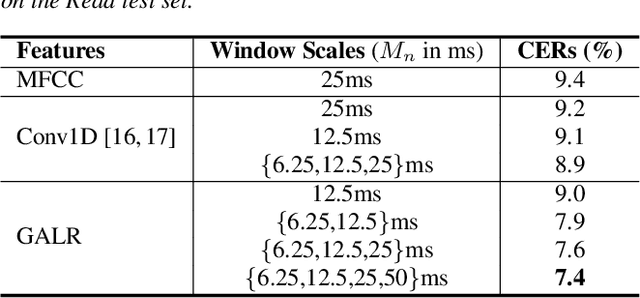
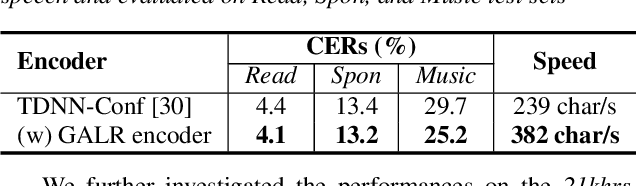
End-to-end speech recognition generally uses hand-engineered acoustic features as input and excludes the feature extraction module from its joint optimization. To extract learnable and adaptive features and mitigate information loss, we propose a new encoder that adopts globally attentive locally recurrent (GALR) networks and directly takes raw waveform as input. We observe improved ASR performance and robustness by applying GALR on different window lengths to aggregate fine-grain temporal information into multi-scale acoustic features. Experiments are conducted on a benchmark dataset AISHELL-2 and two large-scale Mandarin speech corpus of 5,000 hours and 21,000 hours. With faster speed and comparable model size, our proposed multi-scale GALR waveform encoder achieved consistent character error rate reductions (CERRs) from 7.9% to 28.1% relative over strong baselines, including Conformer and TDNN-Conformer. In particular, our approach demonstrated notable robustness than the traditional handcrafted features and outperformed the baseline MFCC-based TDNN-Conformer model by a 15.2% CERR on a music-mixed real-world speech test set.
TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
Mar 31, 2021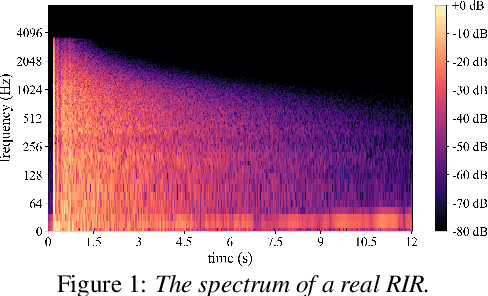
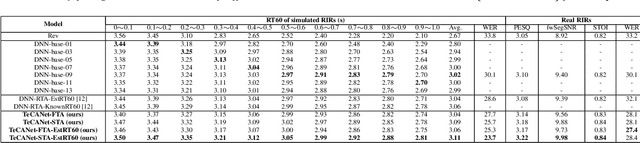
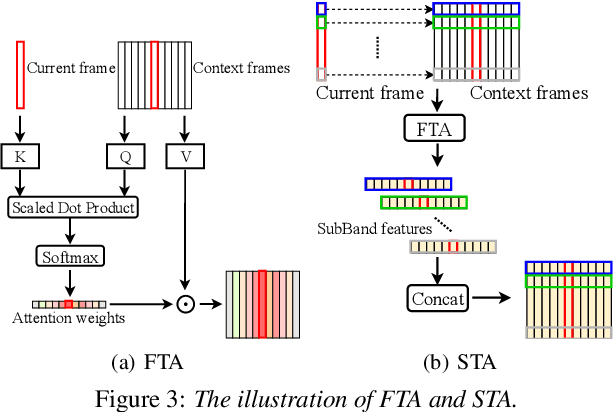
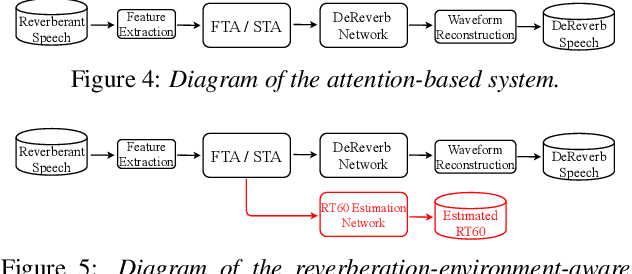
In this paper, we exploit the effective way to leverage contextual information to improve the speech dereverberation performance in real-world reverberant environments. We propose a temporal-contextual attention approach on the deep neural network (DNN) for environment-aware speech dereverberation, which can adaptively attend to the contextual information. More specifically, a FullBand based Temporal Attention approach (FTA) is proposed, which models the correlations between the fullband information of the context frames. In addition, considering the difference between the attenuation of high frequency bands and low frequency bands (high frequency bands attenuate faster than low frequency bands) in the room impulse response (RIR), we also propose a SubBand based Temporal Attention approach (STA). In order to guide the network to be more aware of the reverberant environments, we jointly optimize the dereverberation network and the reverberation time (RT60) estimator in a multi-task manner. Our experimental results indicate that the proposed method outperforms our previously proposed reverberation-time-aware DNN and the learned attention weights are fully physical consistent. We also report a preliminary yet promising dereverberation and recognition experiment on real test data.
Towards Robust Speaker Verification with Target Speaker Enhancement
Mar 16, 2021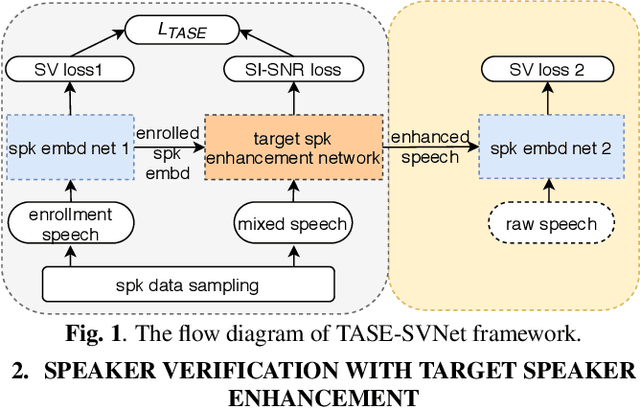
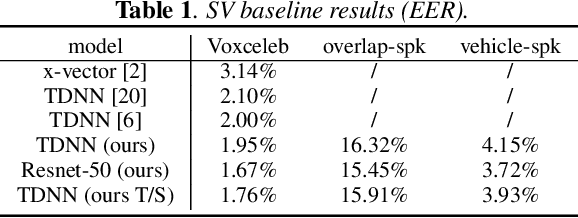
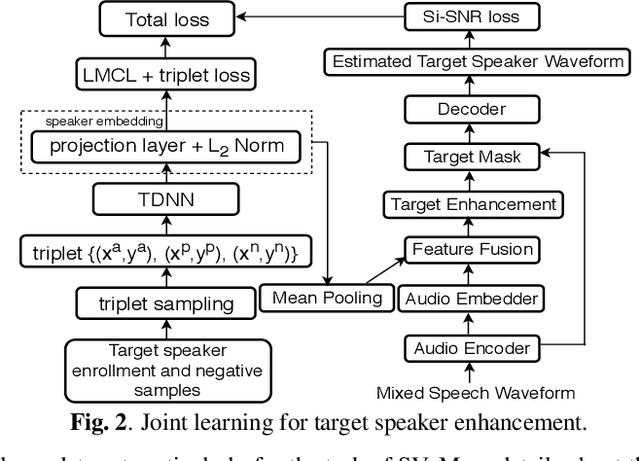
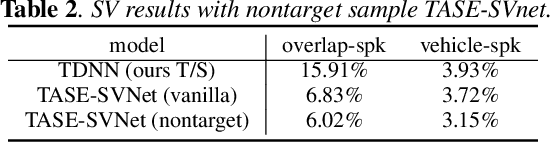
This paper proposes the target speaker enhancement based speaker verification network (TASE-SVNet), an all neural model that couples target speaker enhancement and speaker embedding extraction for robust speaker verification (SV). Specifically, an enrollment speaker conditioned speech enhancement module is employed as the front-end for extracting target speaker from its mixture with interfering speakers and environmental noises. Compared with the conventional target speaker enhancement models, nontarget speaker/interference suppression should draw additional attention for SV. Therefore, an effective nontarget speaker sampling strategy is explored. To improve speaker embedding extraction with a light-weighted model, a teacher-student (T/S) training is proposed to distill speaker discriminative information from large models to small models. Iterative inference is investigated to address the noisy speaker enrollment problem. We evaluate the proposed method on two SV tasks, i.e., one heavily overlapped speech and the other one with comprehensive noise types in vehicle environments. Experiments show significant and consistent improvements in Equal Error Rate (EER) over the state-of-the-art baselines.
Deep Learning based Multi-Source Localization with Source Splitting and its Effectiveness in Multi-Talker Speech Recognition
Feb 16, 2021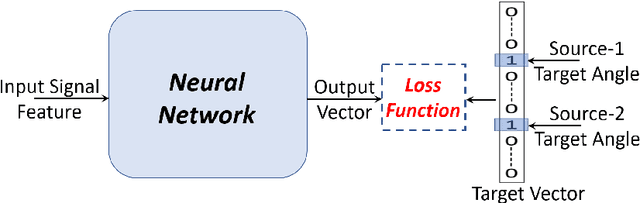
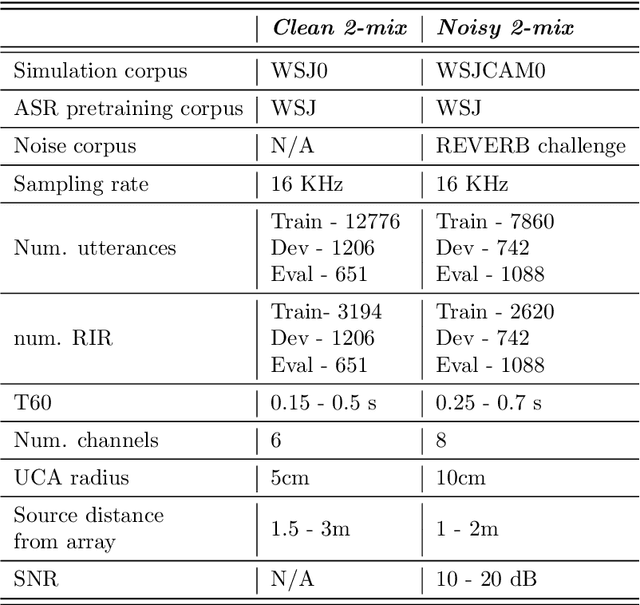
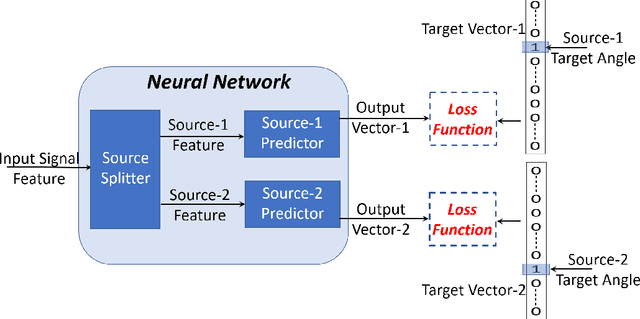
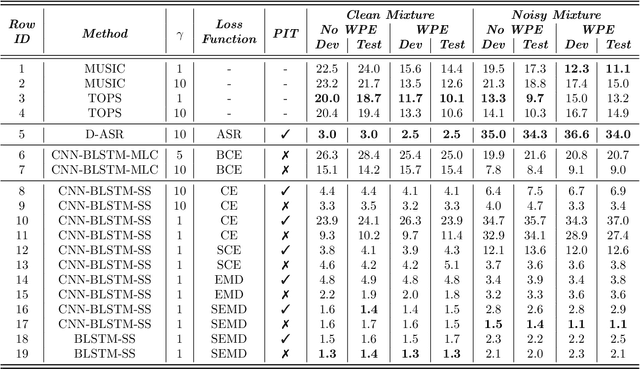
Multi-source localization is an important and challenging technique for multi-talker conversation analysis. This paper proposes a novel supervised learning method using deep neural networks to estimate the direction of arrival (DOA) of all the speakers simultaneously from the audio mixture. At the heart of the proposal is a source splitting mechanism that creates source-specific intermediate representations inside the network. This allows our model to give source-specific posteriors as the output unlike the traditional multi-label classification approach. Existing deep learning methods perform a frame level prediction, whereas our approach performs an utterance level prediction by incorporating temporal selection and averaging inside the network to avoid post-processing. We also experiment with various loss functions and show that a variant of earth mover distance (EMD) is very effective in classifying DOA at a very high resolution by modeling inter-class relationships. In addition to using the prediction error as a metric for evaluating our localization model, we also establish its potency as a frontend with automatic speech recognition (ASR) as the downstream task. We convert the estimated DOAs into a feature suitable for ASR and pass it as an additional input feature to a strong multi-channel and multi-talker speech recognition baseline. This added input feature drastically improves the ASR performance and gives a word error rate (WER) of 6.3% on the evaluation data of our simulated noisy two speaker mixtures, while the baseline which doesn't use explicit localization input has a WER of 11.5%. We also perform ASR evaluation on real recordings with the overlapped set of the MC-WSJ-AV corpus in addition to simulated mixtures.