 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangle-then-Align: Non-Iterative Hybrid Multimodal Image Registration via Cross-Scale Feature Disentanglement
Mar 20, 2026Multimodal image registration is a fundamental task and a prerequisite for downstream cross-modal analysis. Despite recent progress in shared feature extraction and multi-scale architectures, two key limitations remain. First, some methods use disentanglement to learn shared features but mainly regularize the shared part, allowing modality-private cues to leak into the shared space. Second, most multi-scale frameworks support only a single transformation type, limiting their applicability when global misalignment and local deformation coexist. To address these issues, we formulate hybrid multimodal registration as jointly learning a stable shared feature space and a unified hybrid transformation. Based on this view, we propose HRNet, a Hybrid Registration Network that couples representation disentanglement with hybrid parameter prediction. A shared backbone with Modality-Specific Batch Normalization (MSBN) extracts multi-scale features, while a Cross-scale Disentanglement and Adaptive Projection (CDAP) module suppresses modality-private cues and projects shared features into a stable subspace for matching. Built on this shared space, a Hybrid Parameter Prediction Module (HPPM) performs non-iterative coarse-to-fine estimation of global rigid parameters and deformation fields, which are fused into a coherent deformation field. Extensive experiments on four multimodal datasets demonstrate state-of-the-art performance on rigid and non-rigid registration tasks. The code is available at the project website.
Balancing Speech Understanding and Generation Using Continual Pre-training for Codec-based Speech LLM
Feb 24, 2025Recent efforts have extended textual LLMs to the speech domain. Yet, a key challenge remains, which is balancing speech understanding and generation while avoiding catastrophic forgetting when integrating acoustically rich codec-based representations into models originally trained on text. In this work, we propose a novel approach that leverages continual pre-training (CPT) on a pre-trained textual LLM to create a codec-based speech language model. This strategy mitigates the modality gap between text and speech, preserving the linguistic reasoning of the original model while enabling high-fidelity speech synthesis. We validate our approach with extensive experiments across multiple tasks, including automatic speech recognition, text-to-speech, speech-to-text translation, and speech-to-speech translation (S2ST), demonstrating that our model achieves superior TTS performance and, notably, the first end-to-end S2ST system based on neural codecs.
Advancing Multi-talker ASR Performance with Large Language Models
Aug 30, 2024



Recognizing overlapping speech from multiple speakers in conversational scenarios is one of the most challenging problem for automatic speech recognition (ASR). Serialized output training (SOT) is a classic method to address multi-talker ASR, with the idea of concatenating transcriptions from multiple speakers according to the emission times of their speech for training. However, SOT-style transcriptions, derived from concatenating multiple related utterances in a conversation, depend significantly on modeling long contexts. Therefore, compared to traditional methods that primarily emphasize encoder performance in attention-based encoder-decoder (AED) architectures, a novel approach utilizing large language models (LLMs) that leverages the capabilities of pre-trained decoders may be better suited for such complex and challenging scenarios. In this paper, we propose an LLM-based SOT approach for multi-talker ASR, leveraging pre-trained speech encoder and LLM, fine-tuning them on multi-talker dataset using appropriate strategies. Experimental results demonstrate that our approach surpasses traditional AED-based methods on the simulated dataset LibriMix and achieves state-of-the-art performance on the evaluation set of the real-world dataset AMI, outperforming the AED model trained with 1000 times more supervised data in previous works.
uSee: Unified Speech Enhancement and Editing with Conditional Diffusion Models
Oct 02, 2023Speech enhancement aims to improve the quality of speech signals in terms of quality and intelligibility, and speech editing refers to the process of editing the speech according to specific user needs. In this paper, we propose a Unified Speech Enhancement and Editing (uSee) model with conditional diffusion models to handle various tasks at the same time in a generative manner. Specifically, by providing multiple types of conditions including self-supervised learning embeddings and proper text prompts to the score-based diffusion model, we can enable controllable generation of the unified speech enhancement and editing model to perform corresponding actions on the source speech. Our experiments show that our proposed uSee model can achieve superior performance in both speech denoising and dereverberation compared to other related generative speech enhancement models, and can perform speech editing given desired environmental sound text description, signal-to-noise ratios (SNR), and room impulse responses (RIR). Demos of the generated speech are available at https://muqiaoy.github.io/usee.
Unifying Robustness and Fidelity: A Comprehensive Study of Pretrained Generative Methods for Speech Enhancement in Adverse Conditions
Sep 16, 2023



Enhancing speech signal quality in adverse acoustic environments is a persistent challenge in speech processing. Existing deep learning based enhancement methods often struggle to effectively remove background noise and reverberation in real-world scenarios, hampering listening experiences. To address these challenges, we propose a novel approach that uses pre-trained generative methods to resynthesize clean, anechoic speech from degraded inputs. This study leverages pre-trained vocoder or codec models to synthesize high-quality speech while enhancing robustness in challenging scenarios. Generative methods effectively handle information loss in speech signals, resulting in regenerated speech that has improved fidelity and reduced artifacts. By harnessing the capabilities of pre-trained models, we achieve faithful reproduction of the original speech in adverse conditions. Experimental evaluations on both simulated datasets and realistic samples demonstrate the effectiveness and robustness of our proposed methods. Especially by leveraging codec, we achieve superior subjective scores for both simulated and realistic recordings. The generated speech exhibits enhanced audio quality, reduced background noise, and reverberation. Our findings highlight the potential of pre-trained generative techniques in speech processing, particularly in scenarios where traditional methods falter. Demos are available at https://whmrtm.github.io/SoundResynthesis.
Make-A-Voice: Unified Voice Synthesis With Discrete Representation
May 30, 2023



Various applications of voice synthesis have been developed independently despite the fact that they generate "voice" as output in common. In addition, the majority of voice synthesis models currently rely on annotated audio data, but it is crucial to scale them to self-supervised datasets in order to effectively capture the wide range of acoustic variations present in human voice, including speaker identity, emotion, and prosody. In this work, we propose Make-A-Voice, a unified framework for synthesizing and manipulating voice signals from discrete representations. Make-A-Voice leverages a "coarse-to-fine" approach to model the human voice, which involves three stages: 1) semantic stage: model high-level transformation between linguistic content and self-supervised semantic tokens, 2) acoustic stage: introduce varying control signals as acoustic conditions for semantic-to-acoustic modeling, and 3) generation stage: synthesize high-fidelity waveforms from acoustic tokens. Make-A-Voice offers notable benefits as a unified voice synthesis framework: 1) Data scalability: the major backbone (i.e., acoustic and generation stage) does not require any annotations, and thus the training data could be scaled up. 2) Controllability and conditioning flexibility: we investigate different conditioning mechanisms and effectively handle three voice synthesis applications, including text-to-speech (TTS), voice conversion (VC), and singing voice synthesis (SVS) by re-synthesizing the discrete voice representations with prompt guidance. Experimental results demonstrate that Make-A-Voice exhibits superior audio quality and style similarity compared with competitive baseline models. Audio samples are available at https://Make-A-Voice.github.io
C3-DINO: Joint Contrastive and Non-contrastive Self-Supervised Learning for Speaker Verification
Aug 15, 2022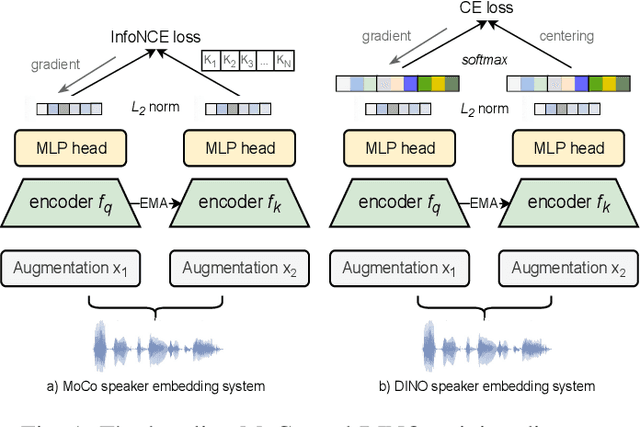
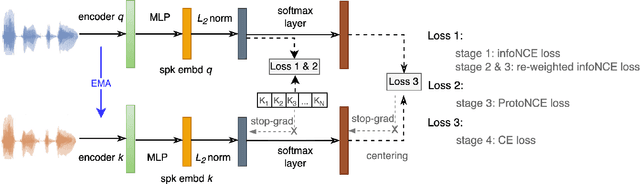
Self-supervised learning (SSL) has drawn an increased attention in the field of speech processing. Recent studies have demonstrated that contrastive learning is able to learn discriminative speaker embeddings in a self-supervised manner. However, base contrastive self-supervised learning (CSSL) assumes that the pairs generated from a view of anchor instance and any view of other instances are all negative, which introduces many false negative pairs in constructing the loss function. The problem is referred as $class$-$collision$, which remains as one major issue that impedes the CSSL based speaker verification (SV) systems from achieving better performances. In the meanwhile, studies reveal that negative sample free SSL frameworks perform well in learning speaker or image representations. In this study, we investigate SSL techniques that lead to an improved SV performance. We first analyse the impact of false negative pairs in the CSSL systems. Then, a multi-stage Class-Collision Correction (C3) method is proposed, which leads to the state-of-the-art CSSL based speaker embedding system. On the basis of the pretrained CSSL model, we further propose to employ a negative sample free SSL objective (i.e., DINO) to fine-tune the speaker embedding network. The resulting speaker embedding system (C3-DINO) achieves 2.5% EER with a simple Cosine Distance Scoring method on Voxceleb1 test set, which outperforms the previous SOTA SSL system (4.86%) by a significant +45% relative improvement. With speaker clustering and pseudo labeling on Voxceleb2 training set, a LDA/CDS back-end applying on the C3-DINO speaker embeddings is able to further push the EER to 2.2%. Comprehensive experimental investigations of the Voxceleb benchmarks and our internal dataset demonstrate the effectiveness of our proposed methods, and the performance gap between the SSL SV and the supervised counterpart narrows further.
UTTS: Unsupervised TTS with Conditional Disentangled Sequential Variational Auto-encoder
Jun 07, 2022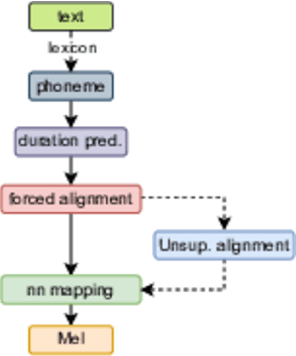

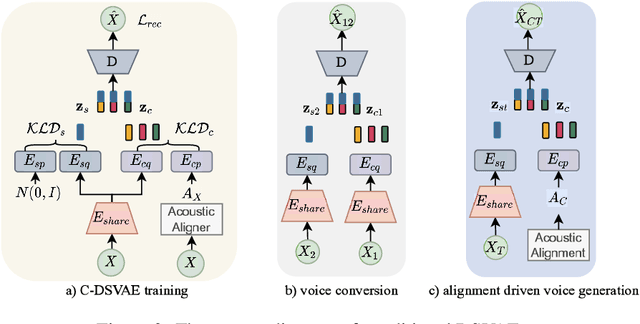
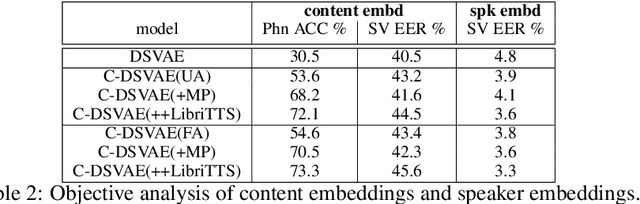
In this paper, we propose a novel unsupervised text-to-speech (UTTS) framework which does not require text-audio pairs for the TTS acoustic modeling (AM). UTTS is a multi-speaker speech synthesizer developed from the perspective of disentangled speech representation learning. The framework offers a flexible choice of a speaker's duration model, timbre feature (identity) and content for TTS inference. We leverage recent advancements in self-supervised speech representation learning as well as speech synthesis front-end techniques for the system development. Specifically, we utilize a lexicon to map input text to the phoneme sequence, which is expanded to the frame-level forced alignment (FA) with a speaker-dependent duration model. Then, we develop an alignment mapping module that converts the FA to the unsupervised alignment (UA). Finally, a Conditional Disentangled Sequential Variational Auto-encoder (C-DSVAE), serving as the self-supervised TTS AM, takes the predicted UA and a target speaker embedding to generate the mel spectrogram, which is ultimately converted to waveform with a neural vocoder. We show how our method enables speech synthesis without using a paired TTS corpus. Experiments demonstrate that UTTS can synthesize speech of high naturalness and intelligibility measured by human and objective evaluations.
LAE: Language-Aware Encoder for Monolingual and Multilingual ASR
Jun 05, 2022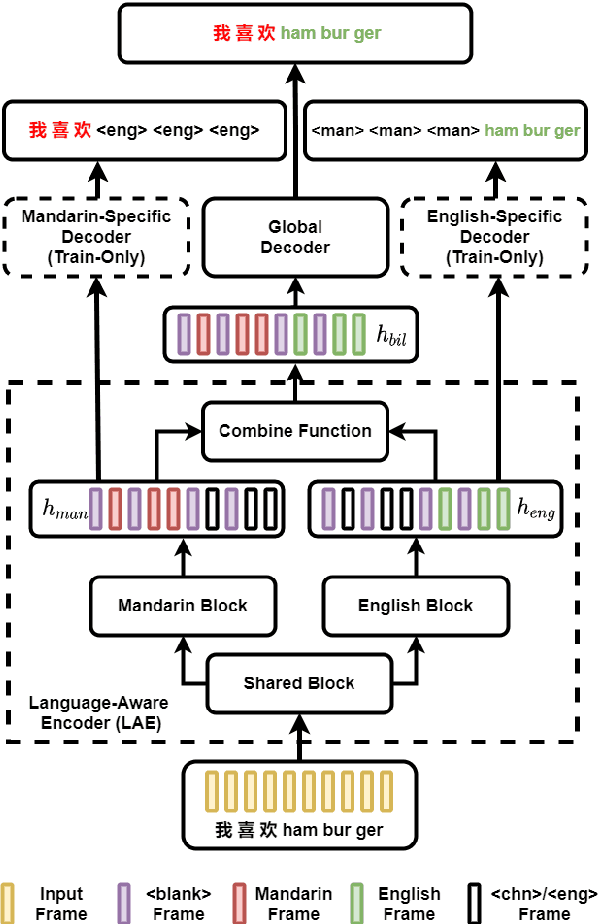
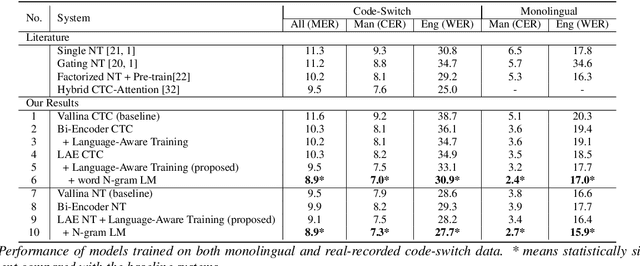
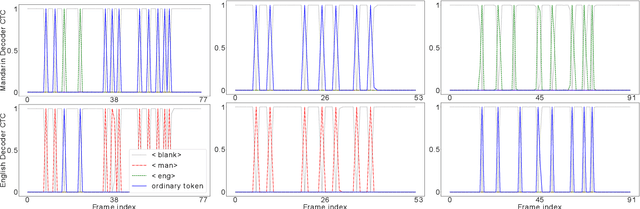
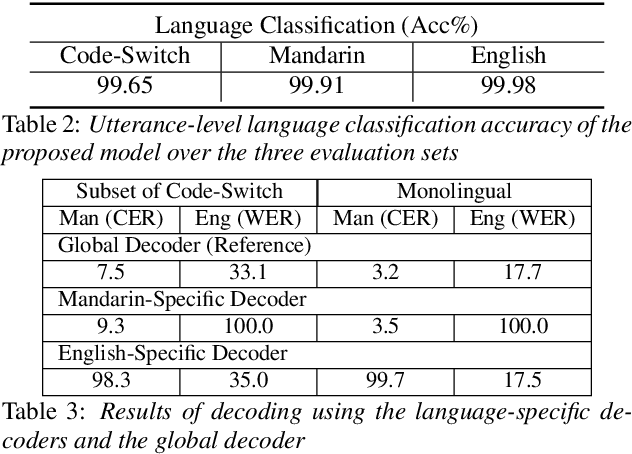
Despite the rapid progress in automatic speech recognition (ASR) research, recognizing multilingual speech using a unified ASR system remains highly challenging. Previous works on multilingual speech recognition mainly focus on two directions: recognizing multiple monolingual speech or recognizing code-switched speech that uses different languages interchangeably within a single utterance. However, a pragmatic multilingual recognizer is expected to be compatible with both directions. In this work, a novel language-aware encoder (LAE) architecture is proposed to handle both situations by disentangling language-specific information and generating frame-level language-aware representations during encoding. In the LAE, the primary encoding is implemented by the shared block while the language-specific blocks are used to extract specific representations for each language. To learn language-specific information discriminatively, a language-aware training method is proposed to optimize the language-specific blocks in LAE. Experiments conducted on Mandarin-English code-switched speech suggest that the proposed LAE is capable of discriminating different languages in frame-level and shows superior performance on both monolingual and multilingual ASR tasks. With either a real-recorded or simulated code-switched dataset, the proposed LAE achieves statistically significant improvements on both CTC and neural transducer systems. Code is released
NeuralEcho: A Self-Attentive Recurrent Neural Network For Unified Acoustic Echo Suppression And Speech Enhancement
May 20, 2022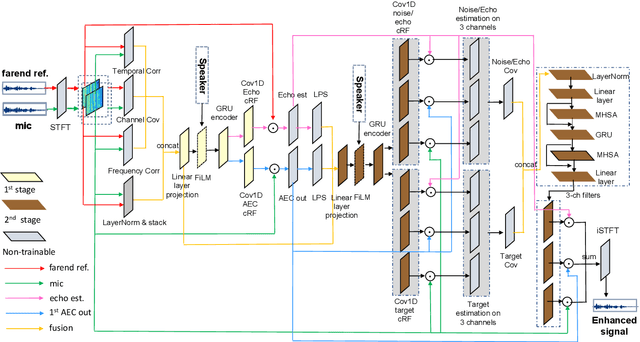
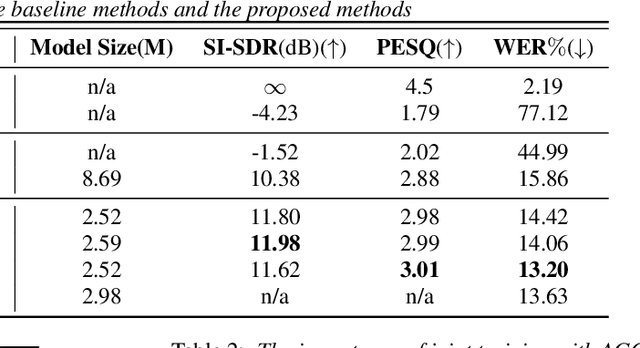
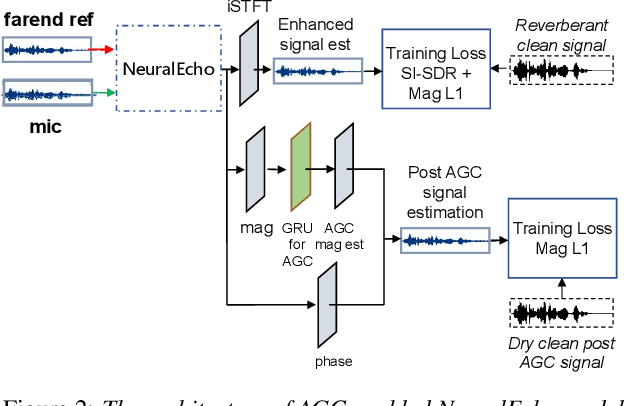

Acoustic echo cancellation (AEC) plays an important role in the full-duplex speech communication as well as the front-end speech enhancement for recognition in the conditions when the loudspeaker plays back. In this paper, we present an all-deep-learning framework that implicitly estimates the second order statistics of echo/noise and target speech, and jointly solves echo and noise suppression through an attention based recurrent neural network. The proposed model outperforms the state-of-the-art joint echo cancellation and speech enhancement method F-T-LSTM in terms of objective speech quality metrics, speech recognition accuracy and model complexity. We show that this model can work with speaker embedding for better target speech enhancement and furthermore develop a branch for automatic gain control (AGC) task to form an all-in-one front-end speech enhancement system.