 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXR$^3$: An Extended Reality Platform for Social-Physical Human-Robot Interaction
Jan 23, 2026Social-physical human-robot interaction (spHRI) is difficult to study: building and programming robots that integrate multiple interaction modalities is costly and slow, while VR-based prototypes often lack physical contact, breaking users' visuo-tactile expectations. We present XR$^3$, a co-located dual-VR-headset platform for HRI research in which an attendee and a hidden operator share the same physical space while experiencing different virtual embodiments. The attendee sees an expressive virtual robot that interacts face-to-face in a shared virtual environment. In real time, the robot's upper-body motion, head and gaze behavior, and facial expressions are mapped from the operator's tracked limbs and face signals. Because the operator is co-present and calibrated in the same coordinate frame, the operator can also touch the attendee, enabling perceived robot touch synchronized with the robot's visible hands. Finger and hand motion is mapped to the robot avatar using inverse kinematics to support precise contact. Beyond motion retargeting, XR$^3$ supports social retargeting of multiple nonverbal cues that can be experimentally varied while keeping physical interaction constant. We detail the system design and calibration, and demonstrate the platform in a touch-based Wizard-of-Oz study, lowering the barrier to prototyping and evaluating embodied, contact-based robot behaviors.
VR$^2$: A Co-Located Dual-Headset Platform for Touch-Enabled Human-Robot Interaction Research
Jan 21, 2026Social-physical human-robot interaction (HRI) is difficult to study: building and programming robots integrating multiple interaction modalities is costly and slow, while VR-based prototypes often lack physical contact capabilities, breaking the visuo-tactile expectations of the user. We present VR2VR, a co-located dual-VR-headset platform for HRI research in which a participant and a hidden operator share the same physical space while experiencing different virtual embodiments. The participant sees an expressive virtual robot that interacts face-to-face in a shared virtual environment. In real time, the robot's upper-body movements, head and gaze behaviors, and facial expressions are mapped from the operator's tracked limbs and face signals. Since the operator is physically co-present and calibrated into the same coordinate frame, the operator can also touch the participant, enabling the participant to perceive robot touch synchronized with the visual perception of the robot's hands on their hands: the operator's finger and hand motion is mapped to the robot avatar using inverse kinematics to support precise contact. Beyond faithful motion retargeting for limb control, our VR2VR system supports social retargeting of multiple nonverbal cues, which can be experimentally varied and investigated while keeping the physical interaction constant. We detail the system design, calibration workflow, and safety considerations, and demonstrate how the platform can be used for experimentation and data collection in a touch-based Wizard-of-Oz HRI study, thus illustrating how VR2VR lowers barriers for rapidly prototyping and rigorously evaluating embodied, contact-based robot behaviors.
Small but Mighty: Dynamic Wavelet Expert-Guided Fine-Tuning of Large-Scale Models for Optical Remote Sensing Object Segmentation
Jan 14, 2026Accurately localizing and segmenting relevant objects from optical remote sensing images (ORSIs) is critical for advancing remote sensing applications. Existing methods are typically built upon moderate-scale pre-trained models and employ diverse optimization strategies to achieve promising performance under full-parameter fine-tuning. In fact, deeper and larger-scale foundation models can provide stronger support for performance improvement. However, due to their massive number of parameters, directly adopting full-parameter fine-tuning leads to pronounced training difficulties, such as excessive GPU memory consumption and high computational costs, which result in extremely limited exploration of large-scale models in existing works. In this paper, we propose a novel dynamic wavelet expert-guided fine-tuning paradigm with fewer trainable parameters, dubbed WEFT, which efficiently adapts large-scale foundation models to ORSIs segmentation tasks by leveraging the guidance of wavelet experts. Specifically, we introduce a task-specific wavelet expert extractor to model wavelet experts from different perspectives and dynamically regulate their outputs, thereby generating trainable features enriched with task-specific information for subsequent fine-tuning. Furthermore, we construct an expert-guided conditional adapter that first enhances the fine-grained perception of frozen features for specific tasks by injecting trainable features, and then iteratively updates the information of both types of feature, allowing for efficient fine-tuning. Extensive experiments show that our WEFT not only outperforms 21 state-of-the-art (SOTA) methods on three ORSIs datasets, but also achieves optimal results in camouflage, natural, and medical scenarios. The source code is available at: https://github.com/CSYSI/WEFT.
PRPO: Aligning Process Reward with Outcome Reward in Policy Optimization
Jan 13, 2026Policy optimization for large language models often suffers from sparse reward signals in multi-step reasoning tasks. Critic-free methods like GRPO assign a single normalized outcome reward to all tokens, providing limited guidance for intermediate reasoning . While Process Reward Models (PRMs) offer dense feedback, they risk premature collapse when used alone, as early low-reward tokens can drive policies toward truncated outputs. We introduce Process Relative Policy Optimization (PRPO), which combines outcome reliability with process-level guidance in a critic-free framework. PRPO segments reasoning sequences based on semantic clues, normalizes PRM scores into token-level advantages, and aligns their distribution with outcome advantages through location-parameter shift. On MATH500, PRPO improves Qwen2.5-Math-1.5B accuracy from 61.2% to 64.4% over GRPO using only eight rollouts and no value network, demonstrating efficient fine-grained credit assignment within critic-free optimization. Code is available at: https://github.com/SchumiDing/srpocode
A Formal Proof of a Continued Fraction Conjecture for $π$ Originating from the Ramanujan Machine
Jan 13, 2026We provide a formal analytic proof for a class of non-canonical polynomial continued fractions representing π/4, originally conjectured by the Ramanujan Machine using algorithmic induction [4]. By establishing an explicit correspondence with the ratio of contiguous Gaussian hypergeometric functions 2F1(a, b; c; z), we show that these identities can be derived via a discrete sequence of equivalence transformations. We further prove that the conjectured integer coefficients constitute a symbolically minimal realization of the underlying analytic kernel. Stability analysis confirms that the resulting limit-periodic structures reside strictly within the Worpitzky convergence disk, ensuring absolute convergence. This work demonstrates that such algorithmically discovered identities are not isolated numerical artifacts, but are deeply rooted in the classical theory of hypergeometric transformations.
RRNet: Configurable Real-Time Video Enhancement with Arbitrary Local Lighting Variations
Jan 05, 2026With the growing demand for real-time video enhancement in live applications, existing methods often struggle to balance speed and effective exposure control, particularly under uneven lighting. We introduce RRNet (Rendering Relighting Network), a lightweight and configurable framework that achieves a state-of-the-art tradeoff between visual quality and efficiency. By estimating parameters for a minimal set of virtual light sources, RRNet enables localized relighting through a depth-aware rendering module without requiring pixel-aligned training data. This object-aware formulation preserves facial identity and supports real-time, high-resolution performance using a streamlined encoder and lightweight prediction head. To facilitate training, we propose a generative AI-based dataset creation pipeline that synthesizes diverse lighting conditions at low cost. With its interpretable lighting control and efficient architecture, RRNet is well suited for practical applications such as video conferencing, AR-based portrait enhancement, and mobile photography. Experiments show that RRNet consistently outperforms prior methods in low-light enhancement, localized illumination adjustment, and glare removal.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
Rethinking Popularity Bias in Collaborative Filtering via Analytical Vector Decomposition
Dec 24, 2025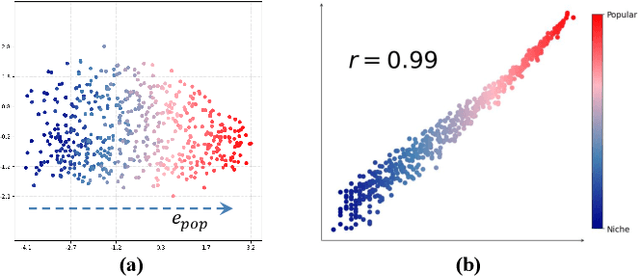
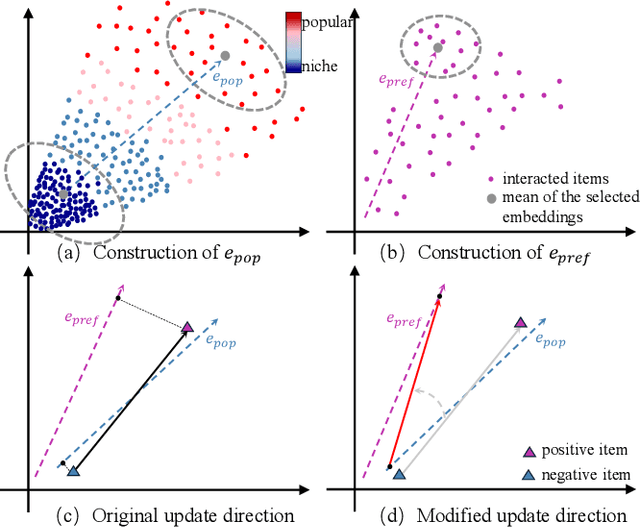
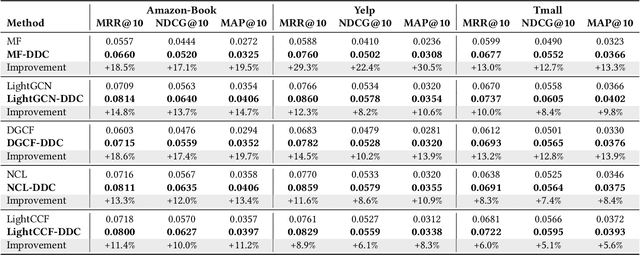
Popularity bias fundamentally undermines the personalization capabilities of collaborative filtering (CF) models, causing them to disproportionately recommend popular items while neglecting users' genuine preferences for niche content. While existing approaches treat this as an external confounding factor, we reveal that popularity bias is an intrinsic geometric artifact of Bayesian Pairwise Ranking (BPR) optimization in CF models. Through rigorous mathematical analysis, we prove that BPR systematically organizes item embeddings along a dominant "popularity direction" where embedding magnitudes directly correlate with interaction frequency. This geometric distortion forces user embeddings to simultaneously handle two conflicting tasks-expressing genuine preference and calibrating against global popularity-trapping them in suboptimal configurations that favor popular items regardless of individual tastes. We propose Directional Decomposition and Correction (DDC), a universally applicable framework that surgically corrects this embedding geometry through asymmetric directional updates. DDC guides positive interactions along personalized preference directions while steering negative interactions away from the global popularity direction, disentangling preference from popularity at the geometric source. Extensive experiments across multiple BPR-based architectures demonstrate that DDC significantly outperforms state-of-the-art debiasing methods, reducing training loss to less than 5% of heavily-tuned baselines while achieving superior recommendation quality and fairness. Code is available in https://github.com/LingFeng-Liu-AI/DDC.
A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
Dec 22, 2025



Reasoning over knowledge graphs (KGs) with first-order logic (FOL) queries is challenging due to the inherent incompleteness of real-world KGs and the compositional complexity of logical query structures. Most existing methods rely on embedding entities and relations into continuous geometric spaces and answer queries via differentiable set operations. While effective for simple query patterns, these approaches often struggle to generalize to complex queries involving multiple operators, deeper reasoning chains, or heterogeneous KG schemas. We propose ROG (Reasoning Over knowledge Graphs with large language models), an ensemble-style framework that combines query-aware KG neighborhood retrieval with large language model (LLM)-based chain-of-thought reasoning. ROG decomposes complex FOL queries into sequences of simpler sub-queries, retrieves compact, query-relevant subgraphs as contextual evidence, and performs step-by-step logical inference using an LLM, avoiding the need for task-specific embedding optimization. Experiments on standard KG reasoning benchmarks demonstrate that ROG consistently outperforms strong embedding-based baselines in terms of mean reciprocal rank (MRR), with particularly notable gains on high-complexity query types. These results suggest that integrating structured KG retrieval with LLM-driven logical reasoning offers a robust and effective alternative for complex KG reasoning tasks.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.