 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDC-UNet: Under-Display Camera Image Restoration via U-Shape Dynamic Network
Sep 11, 2022
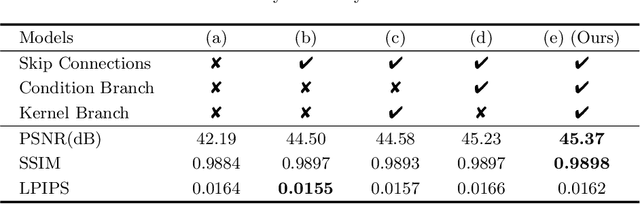
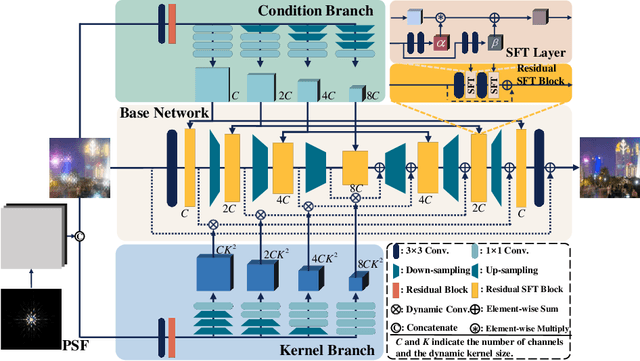

Under-Display Camera (UDC) has been widely exploited to help smartphones realize full screen display. However, as the screen could inevitably affect the light propagation process, the images captured by the UDC system usually contain flare, haze, blur, and noise. Particularly, flare and blur in UDC images could severely deteriorate the user experience in high dynamic range (HDR) scenes. In this paper, we propose a new deep model, namely UDC-UNet, to address the UDC image restoration problem with the known Point Spread Function (PSF) in HDR scenes. On the premise that Point Spread Function (PSF) of the UDC system is known, we treat UDC image restoration as a non-blind image restoration problem and propose a novel learning-based approach. Our network consists of three parts, including a U-shape base network to utilize multi-scale information, a condition branch to perform spatially variant modulation, and a kernel branch to provide the prior knowledge of the given PSF. According to the characteristics of HDR data, we additionally design a tone mapping loss to stabilize network optimization and achieve better visual quality. Experimental results show that the proposed UDC-UNet outperforms the state-of-the-art methods in quantitative and qualitative comparisons. Our approach won the second place in the UDC image restoration track of MIPI challenge. Codes will be publicly available.
PS-NeRV: Patch-wise Stylized Neural Representations for Videos
Aug 07, 2022



We study how to represent a video with implicit neural representations (INRs). Classical INRs methods generally utilize MLPs to map input coordinates to output pixels. While some recent works have tried to directly reconstruct the whole image with CNNs. However, we argue that both the above pixel-wise and image-wise strategies are not favorable to video data. Instead, we propose a patch-wise solution, PS-NeRV, which represents videos as a function of patches and the corresponding patch coordinate. It naturally inherits the advantages of image-wise methods, and achieves excellent reconstruction performance with fast decoding speed. The whole method includes conventional modules, like positional embedding, MLPs and CNNs, while also introduces AdaIN to enhance intermediate features. These simple yet essential changes could help the network easily fit high-frequency details. Extensive experiments have demonstrated its effectiveness in several video-related tasks, such as video compression and video inpainting.
Rethinking Alignment in Video Super-Resolution Transformers
Jul 18, 2022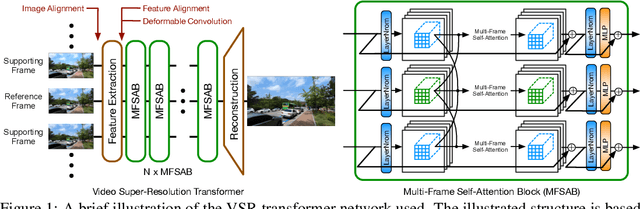
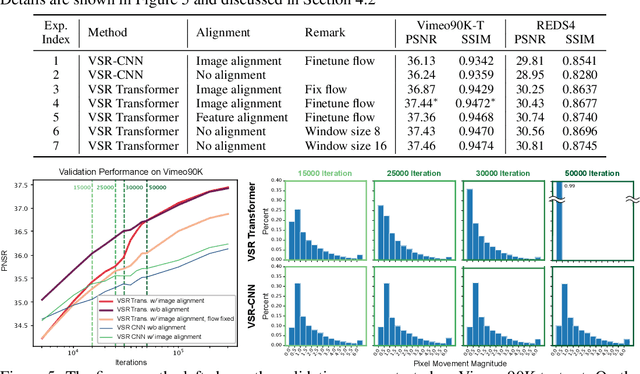

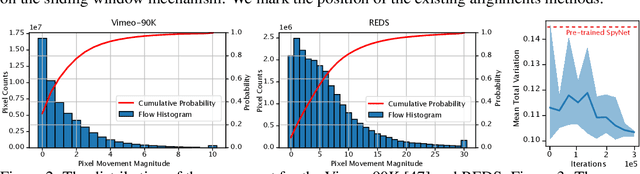
The alignment of adjacent frames is considered an essential operation in video super-resolution (VSR). Advanced VSR models, including the latest VSR Transformers, are generally equipped with well-designed alignment modules. However, the progress of the self-attention mechanism may violate this common sense. In this paper, we rethink the role of alignment in VSR Transformers and make several counter-intuitive observations. Our experiments show that: (i) VSR Transformers can directly utilize multi-frame information from unaligned videos, and (ii) existing alignment methods are sometimes harmful to VSR Transformers. These observations indicate that we can further improve the performance of VSR Transformers simply by removing the alignment module and adopting a larger attention window. Nevertheless, such designs will dramatically increase the computational burden, and cannot deal with large motions. Therefore, we propose a new and efficient alignment method called patch alignment, which aligns image patches instead of pixels. VSR Transformers equipped with patch alignment could demonstrate state-of-the-art performance on multiple benchmarks. Our work provides valuable insights on how multi-frame information is used in VSR and how to select alignment methods for different networks/datasets. Codes and models will be released at https://github.com/XPixelGroup/RethinkVSRAlignment.
A Survey on Collaborative DNN Inference for Edge Intelligence
Jul 16, 2022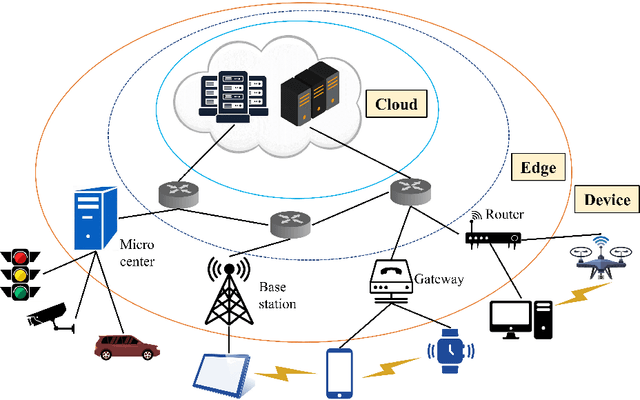
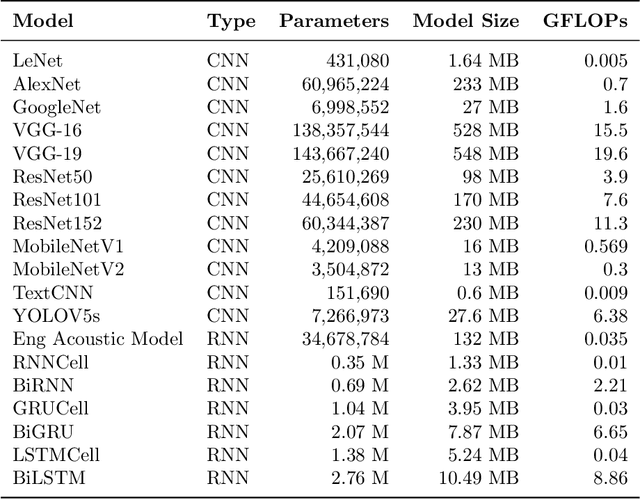
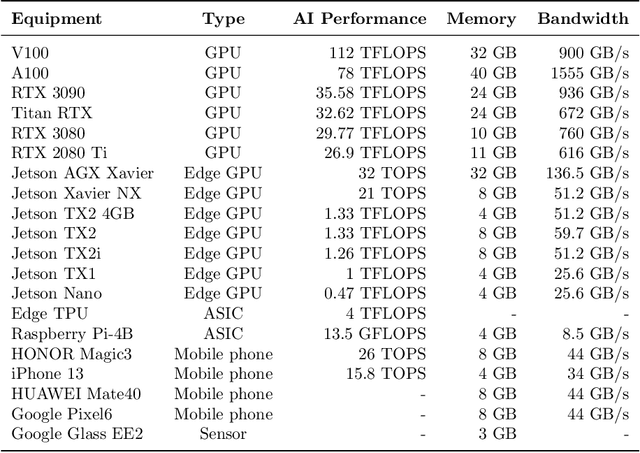
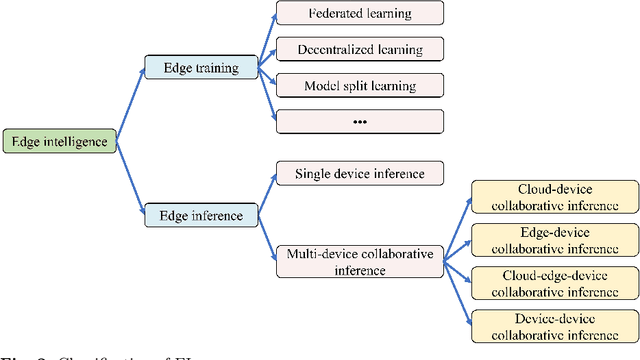
With the vigorous development of artificial intelligence (AI), the intelligent applications based on deep neural network (DNN) change people's lifestyles and the production efficiency. However, the huge amount of computation and data generated from the network edge becomes the major bottleneck, and traditional cloud-based computing mode has been unable to meet the requirements of real-time processing tasks. To solve the above problems, by embedding AI model training and inference capabilities into the network edge, edge intelligence (EI) becomes a cutting-edge direction in the field of AI. Furthermore, collaborative DNN inference among the cloud, edge, and end device provides a promising way to boost the EI. Nevertheless, at present, EI oriented collaborative DNN inference is still in its early stage, lacking a systematic classification and discussion of existing research efforts. Thus motivated, we have made a comprehensive investigation on the recent studies about EI oriented collaborative DNN inference. In this paper, we firstly review the background and motivation of EI. Then, we classify four typical collaborative DNN inference paradigms for EI, and analyze the characteristics and key technologies of them. Finally, we summarize the current challenges of collaborative DNN inference, discuss the future development trend and provide the future research direction.
NTIRE 2022 Challenge on Perceptual Image Quality Assessment
Jun 23, 2022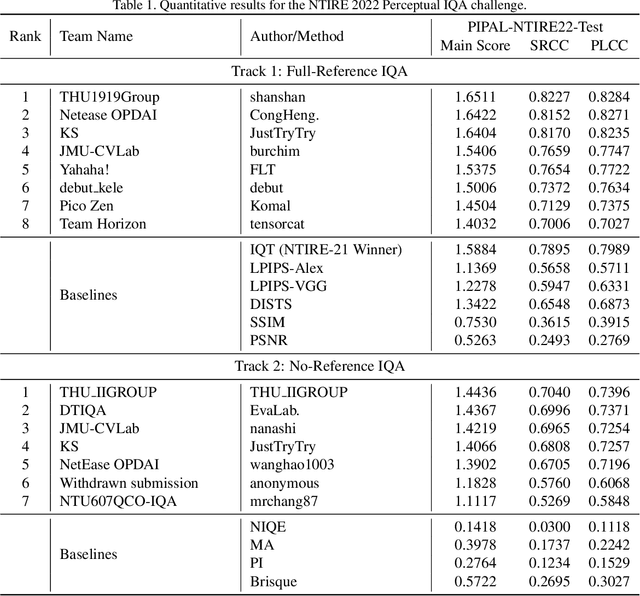
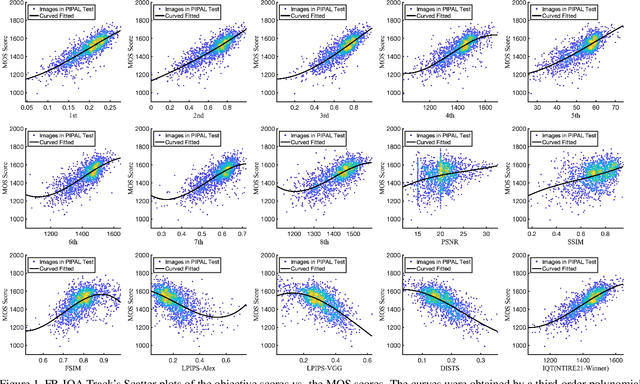
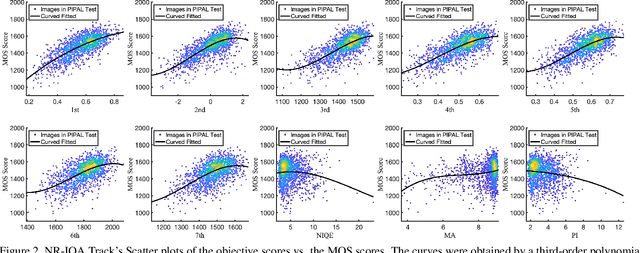
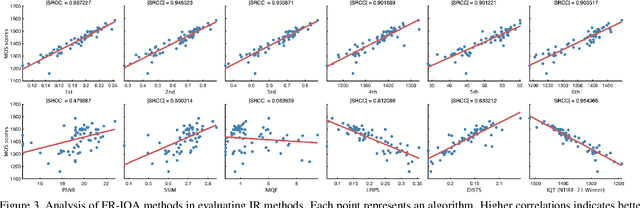
This paper reports on the NTIRE 2022 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2022. This challenge is held to address the emerging challenge of IQA by perceptual image processing algorithms. The output images of these algorithms have completely different characteristics from traditional distortions and are included in the PIPAL dataset used in this challenge. This challenge is divided into two tracks, a full-reference IQA track similar to the previous NTIRE IQA challenge and a new track that focuses on the no-reference IQA methods. The challenge has 192 and 179 registered participants for two tracks. In the final testing stage, 7 and 8 participating teams submitted their models and fact sheets. Almost all of them have achieved better results than existing IQA methods, and the winning method can demonstrate state-of-the-art performance.
Wireless Deep Video Semantic Transmission
May 26, 2022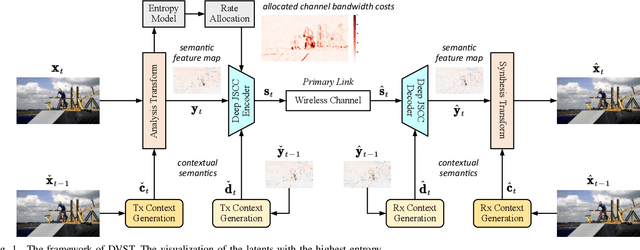
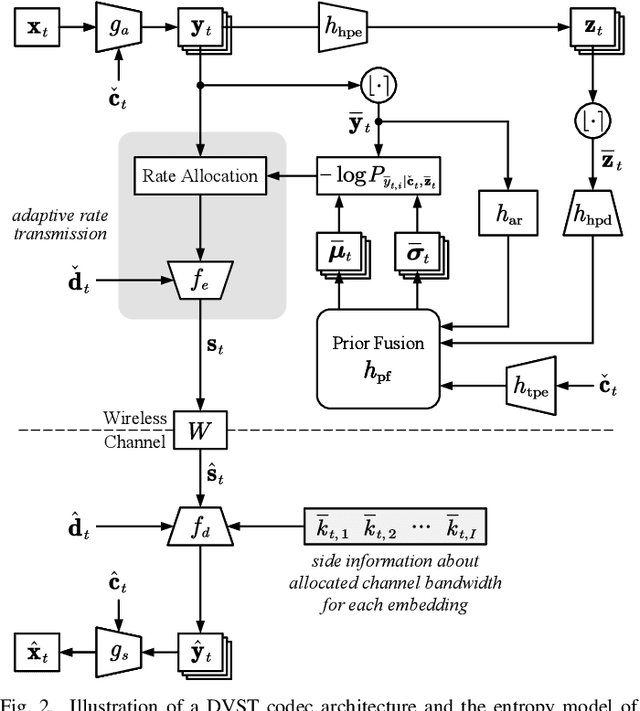
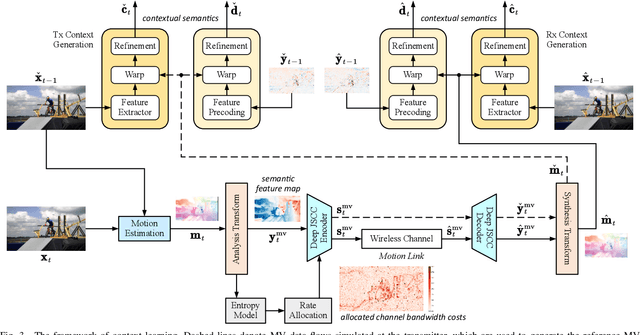
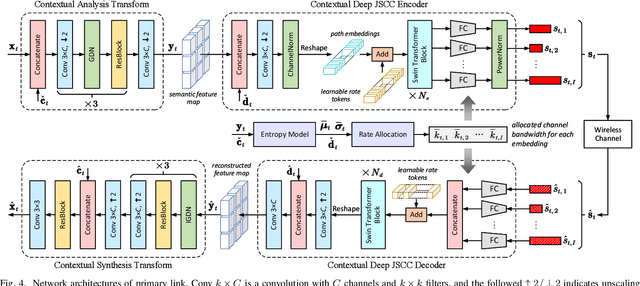
In this paper, we design a new class of high-efficiency deep joint source-channel coding methods to achieve end-to-end video transmission over wireless channels. The proposed methods exploit nonlinear transform and conditional coding architecture to adaptively extract semantic features across video frames, and transmit semantic feature domain representations over wireless channels via deep joint source-channel coding. Our framework is collected under the name deep video semantic transmission (DVST). In particular, benefiting from the strong temporal prior provided by the feature domain context, the learned nonlinear transform function becomes temporally adaptive, resulting in a richer and more accurate entropy model guiding the transmission of current frame. Accordingly, a novel rate adaptive transmission mechanism is developed to customize deep joint source-channel coding for video sources. It learns to allocate the limited channel bandwidth within and among video frames to maximize the overall transmission performance. The whole DVST design is formulated as an optimization problem whose goal is to minimize the end-to-end transmission rate-distortion performance under perceptual quality metrics or machine vision task performance metrics. Across standard video source test sequences and various communication scenarios, experiments show that our DVST can generally surpass traditional wireless video coded transmission schemes. The proposed DVST framework can well support future semantic communications due to its video content-aware and machine vision task integration abilities.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022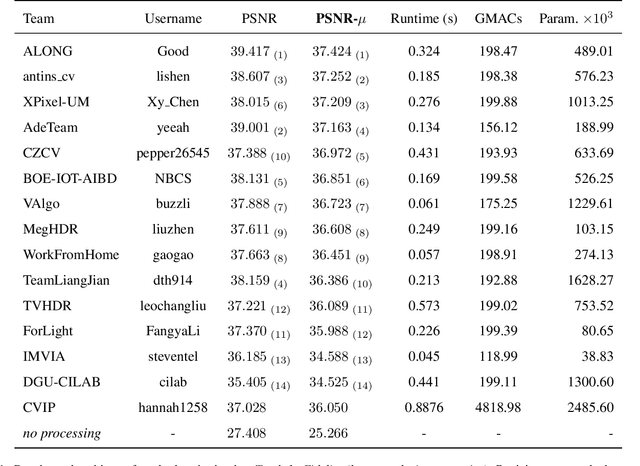
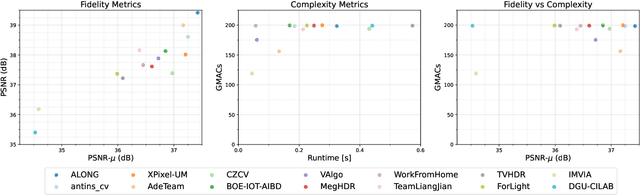
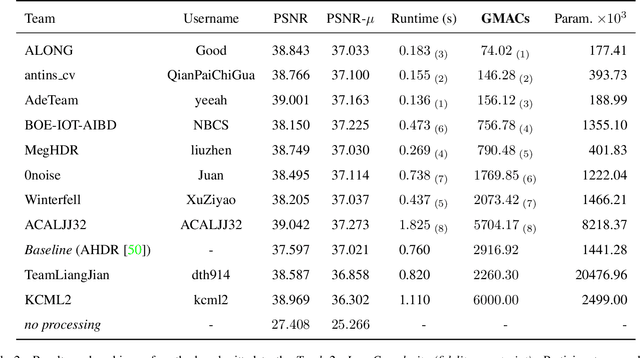
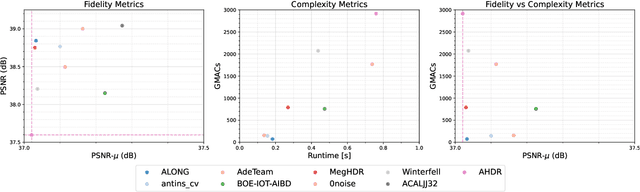
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Activating More Pixels in Image Super-Resolution Transformer
May 16, 2022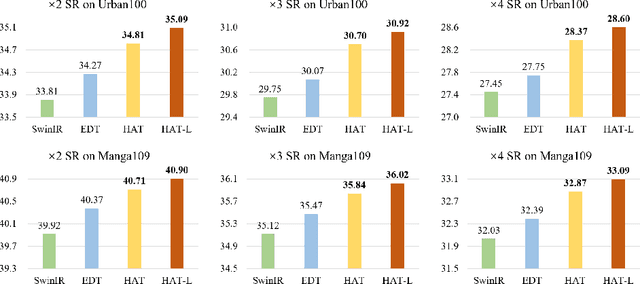

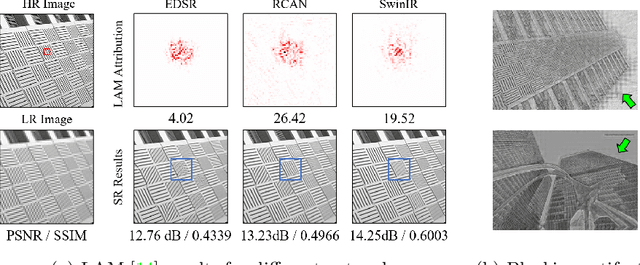

Transformer-based methods have shown impressive performance in low-level vision tasks, such as image super-resolution. However, we find that these networks can only utilize a limited spatial range of input information through attribution analysis. This implies that the potential of Transformer is still not fully exploited in existing networks. In order to activate more input pixels for reconstruction, we propose a novel Hybrid Attention Transformer (HAT). It combines channel attention and self-attention schemes, thus making use of their complementary advantages. Moreover, to better aggregate the cross-window information, we introduce an overlapping cross-attention module to enhance the interaction between neighboring window features. In the training stage, we additionally propose a same-task pre-training strategy to bring further improvement. Extensive experiments show the effectiveness of the proposed modules, and the overall method significantly outperforms the state-of-the-art methods by more than 1dB. Codes and models will be available at https://github.com/chxy95/HAT.
Evaluating the Generalization Ability of Super-Resolution Networks
May 14, 2022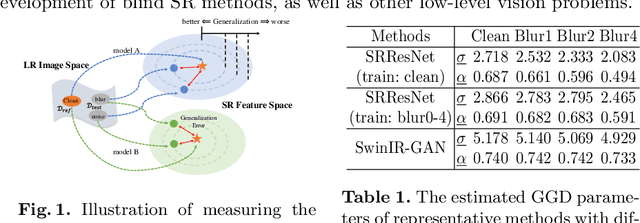


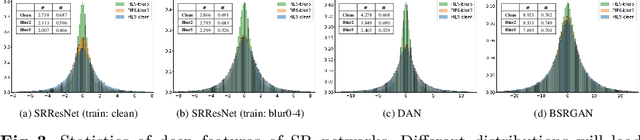
Performance and generalization ability are two important aspects to evaluate deep learning models. However, research on the generalization ability of Super-Resolution (SR) networks is currently absent. We make the first attempt to propose a Generalization Assessment Index for SR networks, namely SRGA. SRGA exploits the statistical characteristics of internal features of deep networks, not output images to measure the generalization ability. Specially, it is a non-parametric and non-learning metric. To better validate our method, we collect a patch-based image evaluation set (PIES) that includes both synthetic and real-world images, covering a wide range of degradations. With SRGA and PIES dataset, we benchmark existing SR models on the generalization ability. This work could lay the foundation for future research on model generalization in low-level vision.
VQFR: Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder
May 13, 2022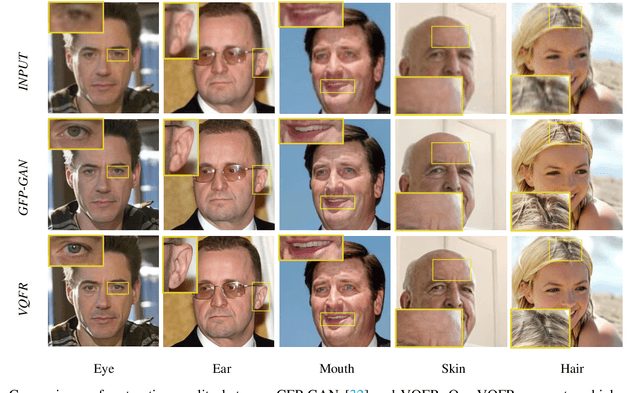

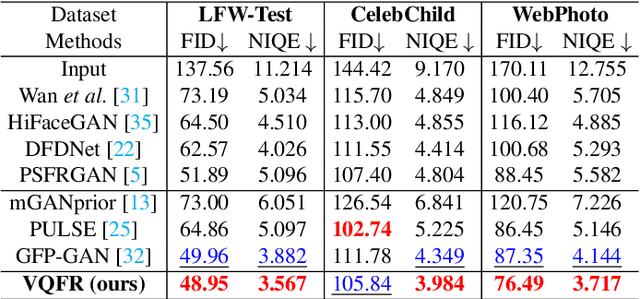
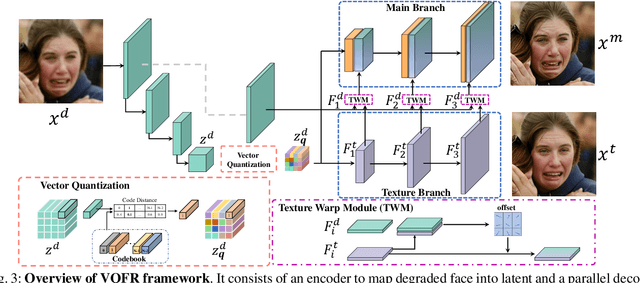
Although generative facial prior and geometric prior have recently demonstrated high-quality results for blind face restoration, producing fine-grained facial details faithful to inputs remains a challenging problem. Motivated by the classical dictionary-based methods and the recent vector quantization (VQ) technique, we propose a VQ-based face restoration method -- VQFR. VQFR takes advantage of high-quality low-level feature banks extracted from high-quality faces and can thus help recover realistic facial details. However, the simple application of the VQ codebook cannot achieve good results with faithful details and identity preservation. Therefore, we further introduce two special network designs. 1). We first investigate the compression patch size in the VQ codebook and find that the VQ codebook designed with a proper compression patch size is crucial to balance the quality and fidelity. 2). To further fuse low-level features from inputs while not "contaminating" the realistic details generated from the VQ codebook, we proposed a parallel decoder consisting of a texture decoder and a main decoder. Those two decoders then interact with a texture warping module with deformable convolution. Equipped with the VQ codebook as a facial detail dictionary and the parallel decoder design, the proposed VQFR can largely enhance the restored quality of facial details while keeping the fidelity to previous methods. Codes will be available at https://github.com/TencentARC/VQFR.