 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGamutMLP: A Lightweight MLP for Color Loss Recovery
Apr 23, 2023Cameras and image-editing software often process images in the wide-gamut ProPhoto color space, encompassing 90% of all visible colors. However, when images are encoded for sharing, this color-rich representation is transformed and clipped to fit within the small-gamut standard RGB (sRGB) color space, representing only 30% of visible colors. Recovering the lost color information is challenging due to the clipping procedure. Inspired by neural implicit representations for 2D images, we propose a method that optimizes a lightweight multi-layer-perceptron (MLP) model during the gamut reduction step to predict the clipped values. GamutMLP takes approximately 2 seconds to optimize and requires only 23 KB of storage. The small memory footprint allows our GamutMLP model to be saved as metadata in the sRGB image -- the model can be extracted when needed to restore wide-gamut color values. We demonstrate the effectiveness of our approach for color recovery and compare it with alternative strategies, including pre-trained DNN-based gamut expansion networks and other implicit neural representation methods. As part of this effort, we introduce a new color gamut dataset of 2200 wide-gamut/small-gamut images for training and testing. Our code and dataset can be found on the project website: https://gamut-mlp.github.io.
Improving Diffusion Models for Scene Text Editing with Dual Encoders
Apr 12, 2023



Scene text editing is a challenging task that involves modifying or inserting specified texts in an image while maintaining its natural and realistic appearance. Most previous approaches to this task rely on style-transfer models that crop out text regions and feed them into image transfer models, such as GANs. However, these methods are limited in their ability to change text style and are unable to insert texts into images. Recent advances in diffusion models have shown promise in overcoming these limitations with text-conditional image editing. However, our empirical analysis reveals that state-of-the-art diffusion models struggle with rendering correct text and controlling text style. To address these problems, we propose DIFFSTE to improve pre-trained diffusion models with a dual encoder design, which includes a character encoder for better text legibility and an instruction encoder for better style control. An instruction tuning framework is introduced to train our model to learn the mapping from the text instruction to the corresponding image with either the specified style or the style of the surrounding texts in the background. Such a training method further brings our method the zero-shot generalization ability to the following three scenarios: generating text with unseen font variation, e.g., italic and bold, mixing different fonts to construct a new font, and using more relaxed forms of natural language as the instructions to guide the generation task. We evaluate our approach on five datasets and demonstrate its superior performance in terms of text correctness, image naturalness, and style controllability. Our code is publicly available. https://github.com/UCSB-NLP-Chang/DiffSTE
ObjectStitch: Generative Object Compositing
Dec 05, 2022Object compositing based on 2D images is a challenging problem since it typically involves multiple processing stages such as color harmonization, geometry correction and shadow generation to generate realistic results. Furthermore, annotating training data pairs for compositing requires substantial manual effort from professionals, and is hardly scalable. Thus, with the recent advances in generative models, in this work, we propose a self-supervised framework for object compositing by leveraging the power of conditional diffusion models. Our framework can hollistically address the object compositing task in a unified model, transforming the viewpoint, geometry, color and shadow of the generated object while requiring no manual labeling. To preserve the input object's characteristics, we introduce a content adaptor that helps to maintain categorical semantics and object appearance. A data augmentation method is further adopted to improve the fidelity of the generator. Our method outperforms relevant baselines in both realism and faithfulness of the synthesized result images in a user study on various real-world images.
One-Trimap Video Matting
Jul 27, 2022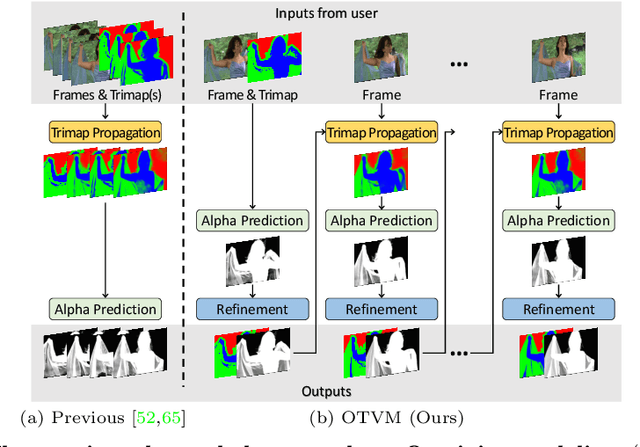
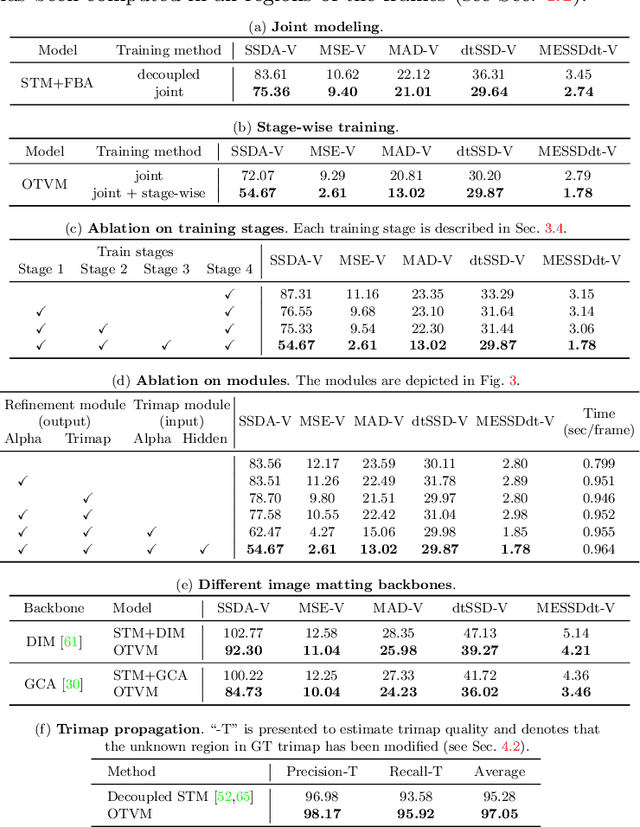
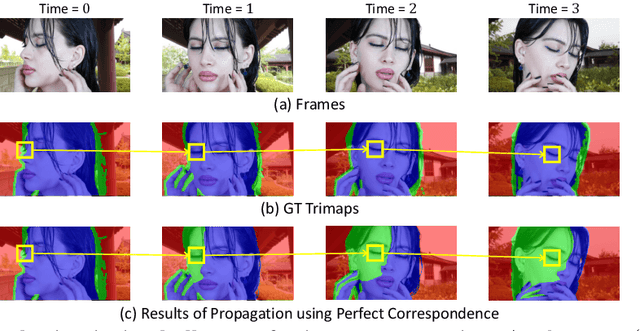
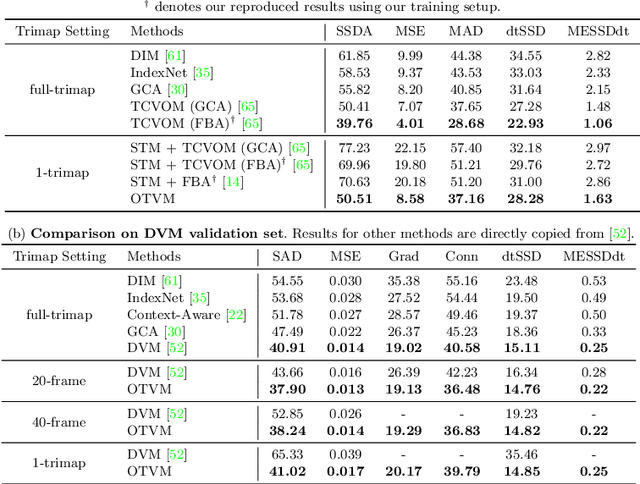
Recent studies made great progress in video matting by extending the success of trimap-based image matting to the video domain. In this paper, we push this task toward a more practical setting and propose One-Trimap Video Matting network (OTVM) that performs video matting robustly using only one user-annotated trimap. A key of OTVM is the joint modeling of trimap propagation and alpha prediction. Starting from baseline trimap propagation and alpha prediction networks, our OTVM combines the two networks with an alpha-trimap refinement module to facilitate information flow. We also present an end-to-end training strategy to take full advantage of the joint model. Our joint modeling greatly improves the temporal stability of trimap propagation compared to the previous decoupled methods. We evaluate our model on two latest video matting benchmarks, Deep Video Matting and VideoMatting108, and outperform state-of-the-art by significant margins (MSE improvements of 56.4% and 56.7%, respectively). The source code and model are available online: https://github.com/Hongje/OTVM.
Boosting Robustness of Image Matting with Context Assembling and Strong Data Augmentation
Jan 18, 2022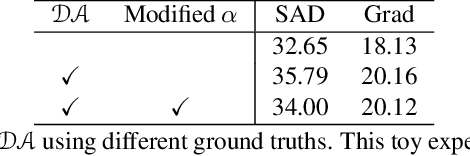

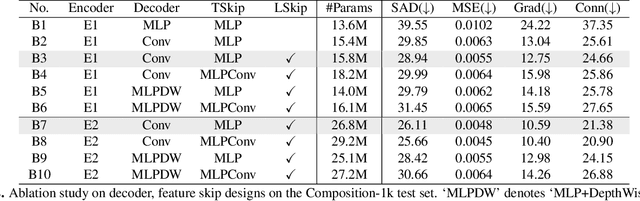
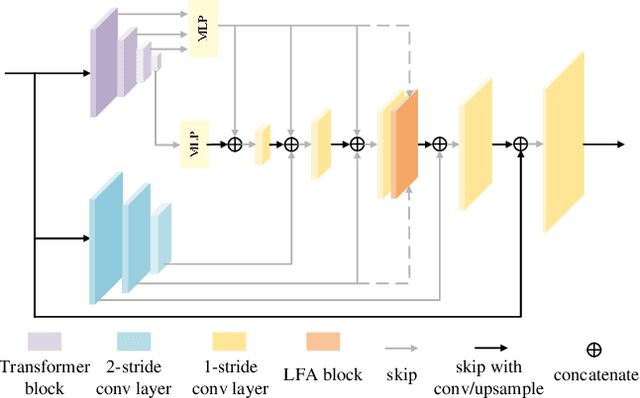
Deep image matting methods have achieved increasingly better results on benchmarks (e.g., Composition-1k/alphamatting.com). However, the robustness, including robustness to trimaps and generalization to images from different domains, is still under-explored. Although some works propose to either refine the trimaps or adapt the algorithms to real-world images via extra data augmentation, none of them has taken both into consideration, not to mention the significant performance deterioration on benchmarks while using those data augmentation. To fill this gap, we propose an image matting method which achieves higher robustness (RMat) via multilevel context assembling and strong data augmentation targeting matting. Specifically, we first build a strong matting framework by modeling ample global information with transformer blocks in the encoder, and focusing on details in combination with convolution layers as well as a low-level feature assembling attention block in the decoder. Then, based on this strong baseline, we analyze current data augmentation and explore simple but effective strong data augmentation to boost the baseline model and contribute a more generalizable matting method. Compared with previous methods, the proposed method not only achieves state-of-the-art results on the Composition-1k benchmark (11% improvement on SAD and 27% improvement on Grad) with smaller model size, but also shows more robust generalization results on other benchmarks, on real-world images, and also on varying coarse-to-fine trimaps with our extensive experiments.
Generalizing Interactive Backpropagating Refinement for Dense Prediction
Dec 22, 2021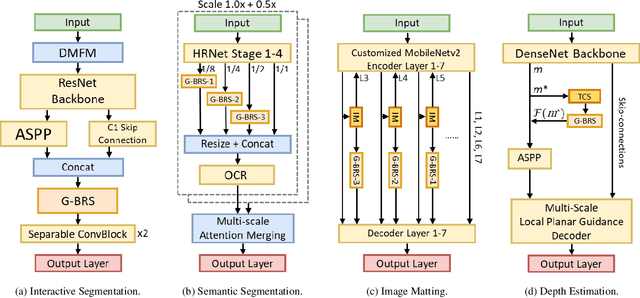


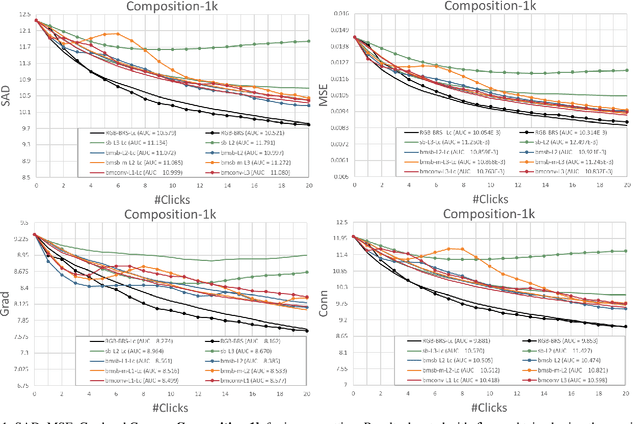
As deep neural networks become the state-of-the-art approach in the field of computer vision for dense prediction tasks, many methods have been developed for automatic estimation of the target outputs given the visual inputs. Although the estimation accuracy of the proposed automatic methods continues to improve, interactive refinement is oftentimes necessary for further correction. Recently, feature backpropagating refinement scheme (f-BRS) has been proposed for the task of interactive segmentation, which enables efficient optimization of a small set of auxiliary variables inserted into the pretrained network to produce object segmentation that better aligns with user inputs. However, the proposed auxiliary variables only contain channel-wise scale and bias, limiting the optimization to global refinement only. In this work, in order to generalize backpropagating refinement for a wide range of dense prediction tasks, we introduce a set of G-BRS (Generalized Backpropagating Refinement Scheme) layers that enable both global and localized refinement for the following tasks: interactive segmentation, semantic segmentation, image matting and monocular depth estimation. Experiments on SBD, Cityscapes, Mapillary Vista, Composition-1k and NYU-Depth-V2 show that our method can successfully generalize and significantly improve performance of existing pretrained state-of-the-art models with only a few clicks.
Generalized Few-Shot Semantic Segmentation: All You Need is Fine-Tuning
Dec 21, 2021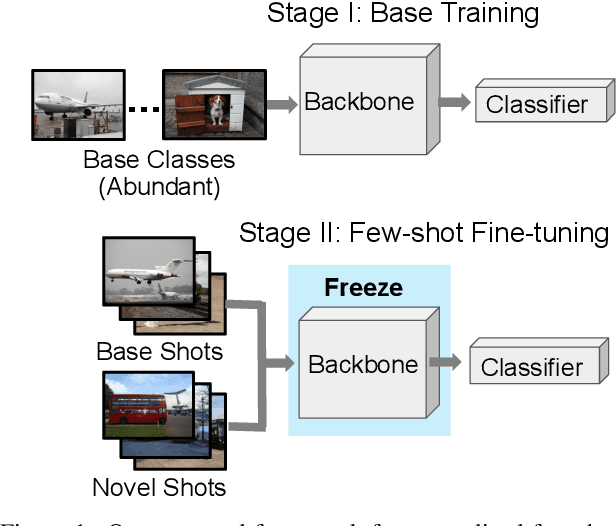
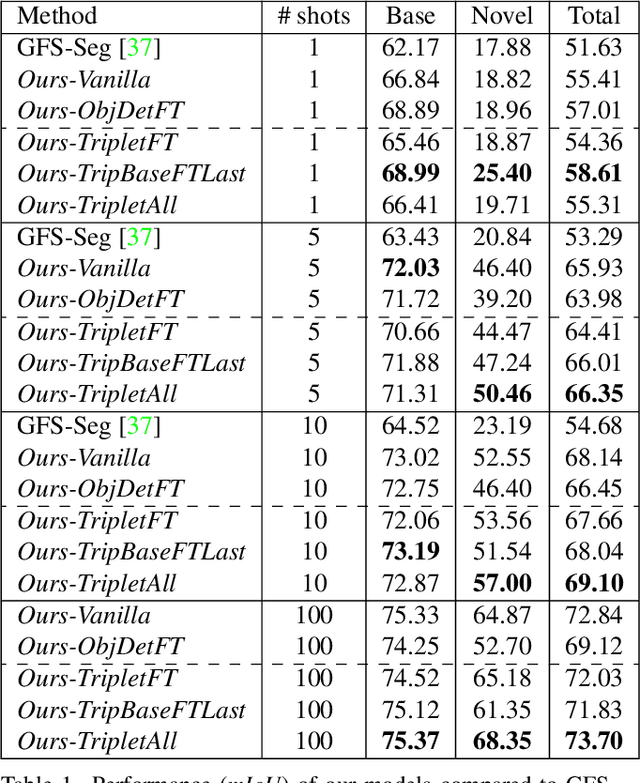
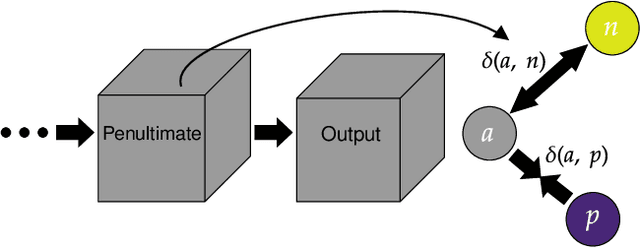
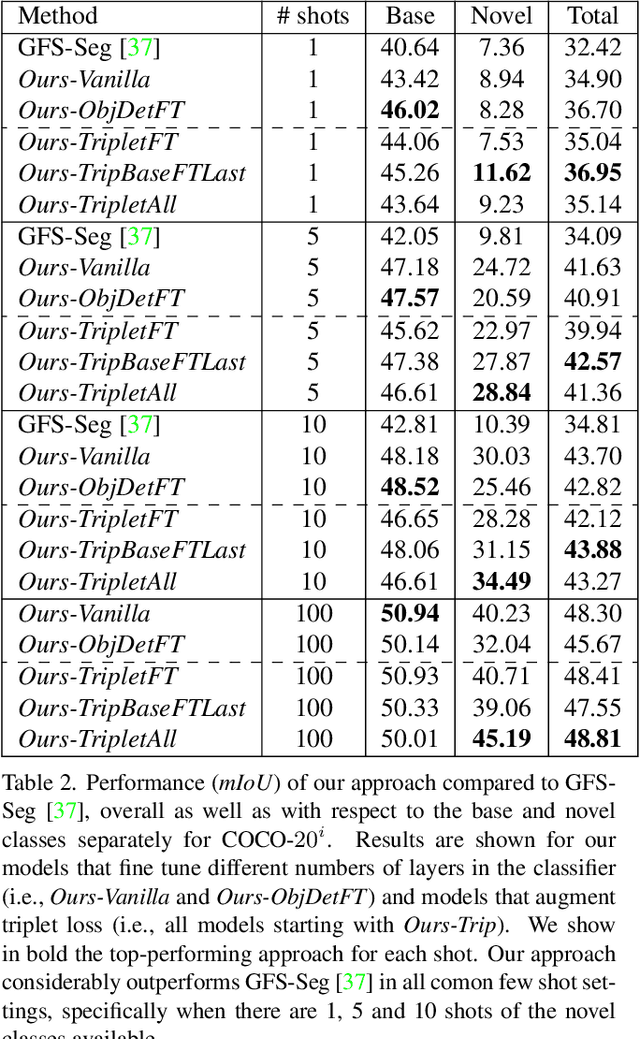
Generalized few-shot semantic segmentation was introduced to move beyond only evaluating few-shot segmentation models on novel classes to include testing their ability to remember base classes. While all approaches currently are based on meta-learning, they perform poorly and saturate in learning after observing only a few shots. We propose the first fine-tuning solution, and demonstrate that it addresses the saturation problem while achieving state-of-art results on two datasets, PASCAL-$5^i$ and COCO-$20^i$. We also show it outperforms existing methods whether fine-tuning multiple final layers or only the final layer. Finally, we present a triplet loss regularization that shows how to redistribute the balance of performance between novel and base categories so that there is a smaller gap between them.
Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach
Nov 27, 2020
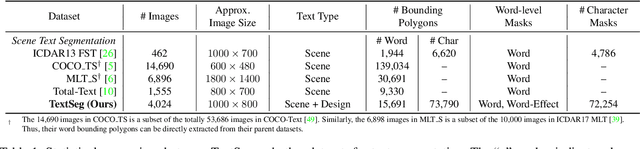
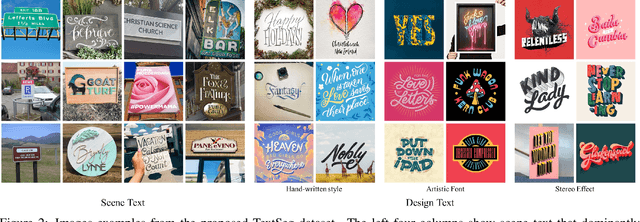
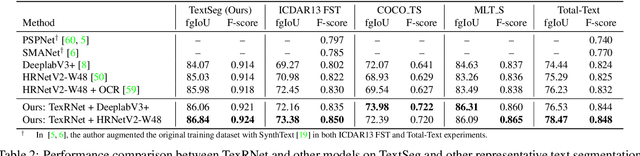
Text segmentation is a prerequisite in many real-world text-related tasks, e.g., text style transfer, and scene text removal. However, facing the lack of high-quality datasets and dedicated investigations, this critical prerequisite has been left as an assumption in many works, and has been largely overlooked by current research. To bridge this gap, we proposed TextSeg, a large-scale fine-annotated text dataset with six types of annotations: word- and character-wise bounding polygons, masks and transcriptions. We also introduce Text Refinement Network (TexRNet), a novel text segmentation approach that adapts to the unique properties of text, e.g. non-convex boundary, diverse texture, etc., which often impose burdens on traditional segmentation models. In our TexRNet, we propose text specific network designs to address such challenges, including key features pooling and attention-based similarity checking. We also introduce trimap and discriminator losses that show significant improvement on text segmentation. Extensive experiments are carried out on both our TextSeg dataset and other existing datasets. We demonstrate that TexRNet consistently improves text segmentation performance by nearly 2% compared to other state-of-the-art segmentation methods. Our dataset and code will be made available at https://github.com/SHI-Labs/Rethinking-Text-Segmentation.
Text and Style Conditioned GAN for Generation of Offline Handwriting Lines
Sep 01, 2020
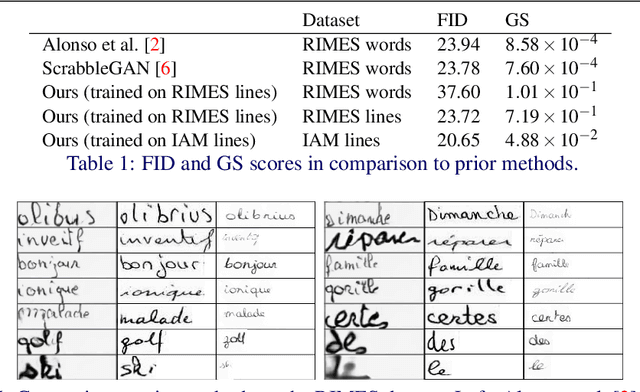
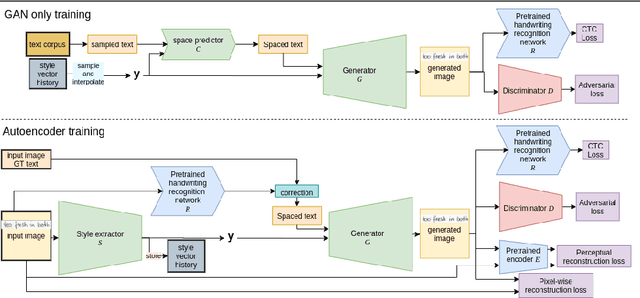
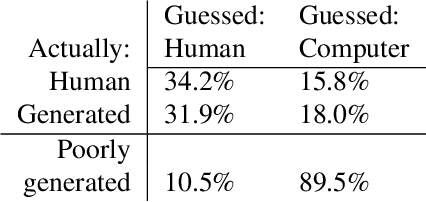
This paper presents a GAN for generating images of handwritten lines conditioned on arbitrary text and latent style vectors. Unlike prior work, which produce stroke points or single-word images, this model generates entire lines of offline handwriting. The model produces variable-sized images by using style vectors to determine character widths. A generator network is trained with GAN and autoencoder techniques to learn style, and uses a pre-trained handwriting recognition network to induce legibility. A study using human evaluators demonstrates that the model produces images that appear to be written by a human. After training, the encoder network can extract a style vector from an image, allowing images in a similar style to be generated, but with arbitrary text.
Objectness-Aware One-Shot Semantic Segmentation
Apr 06, 2020
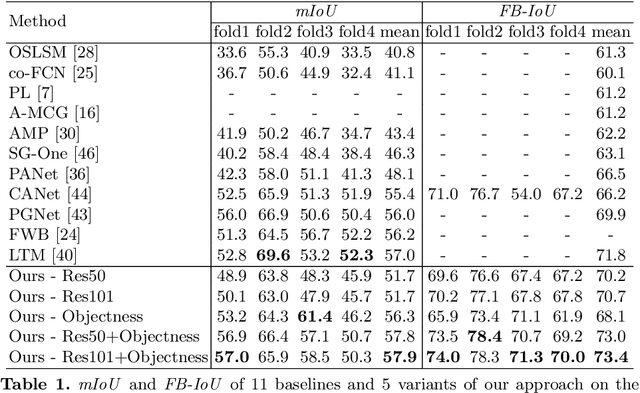
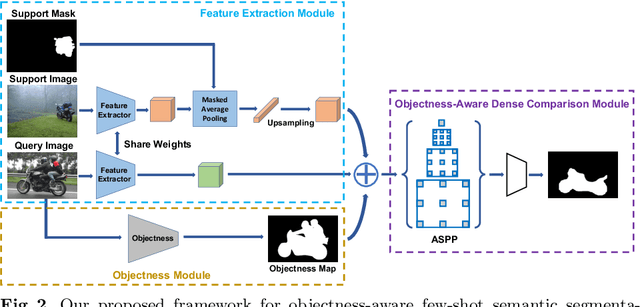

While deep convolutional neural networks have led to great progress in image semantic segmentation, they typically require collecting a large number of densely-annotated images for training. Moreover, once trained, the model can only make predictions in a pre-defined set of categories. Therefore, few-shot image semantic segmentation has been explored to learn to segment from only a few annotated examples. In this paper, we tackle the challenging one-shot semantic segmentation problem by taking advantage of objectness. In order to capture prior knowledge of object and background, we first train an objectness segmentation module which generalizes well to unseen categories. Then we use the objectness module to predict the objects present in the query image, and train an objectness-aware few-shot segmentation model that takes advantage of both the object information and limited annotations of the unseen category to perform segmentation in the query image. Our method achieves a mIoU score of 57.9% and 22.6% given only one annotated example of an unseen category in PASCAL-5i and COCO-20i, outperforming related baselines overall.