 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle Training with Semi-Supervised Domain Adaptation: Bridging Accuracy and Efficiency for Real-Time Mobile Scene Detection
Apr 12, 2025Nowadays, smartphones are ubiquitous, and almost everyone owns one. At the same time, the rapid development of AI has spurred extensive research on applying deep learning techniques to image classification. However, due to the limited resources available on mobile devices, significant challenges remain in balancing accuracy with computational efficiency. In this paper, we propose a novel training framework called Cycle Training, which adopts a three-stage training process that alternates between exploration and stabilization phases to optimize model performance. Additionally, we incorporate Semi-Supervised Domain Adaptation (SSDA) to leverage the power of large models and unlabeled data, thereby effectively expanding the training dataset. Comprehensive experiments on the CamSSD dataset for mobile scene detection demonstrate that our framework not only significantly improves classification accuracy but also ensures real-time inference efficiency. Specifically, our method achieves a 94.00% in Top-1 accuracy and a 99.17% in Top-3 accuracy and runs inference in just 1.61ms using CPU, demonstrating its suitability for real-world mobile deployment.
A Lightweight Moment Retrieval System with Global Re-Ranking and Robust Adaptive Bidirectional Temporal Search
Apr 12, 2025



The exponential growth of digital video content has posed critical challenges in moment-level video retrieval, where existing methodologies struggle to efficiently localize specific segments within an expansive video corpus. Current retrieval systems are constrained by computational inefficiencies, temporal context limitations, and the intrinsic complexity of navigating video content. In this paper, we address these limitations through a novel Interactive Video Corpus Moment Retrieval framework that integrates a SuperGlobal Reranking mechanism and Adaptive Bidirectional Temporal Search (ABTS), strategically optimizing query similarity, temporal stability, and computational resources. By preprocessing a large corpus of videos using a keyframe extraction model and deduplication technique through image hashing, our approach provides a scalable solution that significantly reduces storage requirements while maintaining high localization precision across diverse video repositories.
Towards Efficient and Robust Moment Retrieval System: A Unified Framework for Multi-Granularity Models and Temporal Reranking
Apr 11, 2025Long-form video understanding presents significant challenges for interactive retrieval systems, as conventional methods struggle to process extensive video content efficiently. Existing approaches often rely on single models, inefficient storage, unstable temporal search, and context-agnostic reranking, limiting their effectiveness. This paper presents a novel framework to enhance interactive video retrieval through four key innovations: (1) an ensemble search strategy that integrates coarse-grained (CLIP) and fine-grained (BEIT3) models to improve retrieval accuracy, (2) a storage optimization technique that reduces redundancy by selecting representative keyframes via TransNetV2 and deduplication, (3) a temporal search mechanism that localizes video segments using dual queries for start and end points, and (4) a temporal reranking approach that leverages neighboring frame context to stabilize rankings. Evaluated on known-item search and question-answering tasks, our framework demonstrates substantial improvements in retrieval precision, efficiency, and user interpretability, offering a robust solution for real-world interactive video retrieval applications.
OPSurv: Orthogonal Polynomials Quadrature Algorithm for Survival Analysis
Feb 02, 2024This paper introduces the Orthogonal Polynomials Quadrature Algorithm for Survival Analysis (OPSurv), a new method providing time-continuous functional outputs for both single and competing risks scenarios in survival analysis. OPSurv utilizes the initial zero condition of the Cumulative Incidence function and a unique decomposition of probability densities using orthogonal polynomials, allowing it to learn functional approximation coefficients for each risk event and construct Cumulative Incidence Function estimates via Gauss--Legendre quadrature. This approach effectively counters overfitting, particularly in competing risks scenarios, enhancing model expressiveness and control. The paper further details empirical validations and theoretical justifications of OPSurv, highlighting its robust performance as an advancement in survival analysis with competing risks.
GamutMLP: A Lightweight MLP for Color Loss Recovery
Apr 23, 2023Cameras and image-editing software often process images in the wide-gamut ProPhoto color space, encompassing 90% of all visible colors. However, when images are encoded for sharing, this color-rich representation is transformed and clipped to fit within the small-gamut standard RGB (sRGB) color space, representing only 30% of visible colors. Recovering the lost color information is challenging due to the clipping procedure. Inspired by neural implicit representations for 2D images, we propose a method that optimizes a lightweight multi-layer-perceptron (MLP) model during the gamut reduction step to predict the clipped values. GamutMLP takes approximately 2 seconds to optimize and requires only 23 KB of storage. The small memory footprint allows our GamutMLP model to be saved as metadata in the sRGB image -- the model can be extracted when needed to restore wide-gamut color values. We demonstrate the effectiveness of our approach for color recovery and compare it with alternative strategies, including pre-trained DNN-based gamut expansion networks and other implicit neural representation methods. As part of this effort, we introduce a new color gamut dataset of 2200 wide-gamut/small-gamut images for training and testing. Our code and dataset can be found on the project website: https://gamut-mlp.github.io.
Policy Optimization with Linear Temporal Logic Constraints
Jun 20, 2022
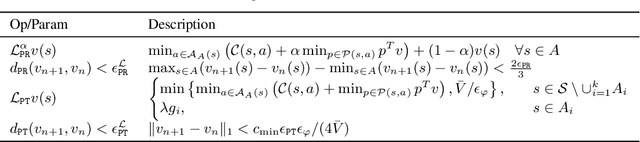

We study the problem of policy optimization (PO) with linear temporal logic (LTL) constraints. The language of LTL allows flexible description of tasks that may be unnatural to encode as a scalar cost function. We consider LTL-constrained PO as a systematic framework, decoupling task specification from policy selection, and an alternative to the standard of cost shaping. With access to a generative model, we develop a model-based approach that enjoys a sample complexity analysis for guaranteeing both task satisfaction and cost optimality (through a reduction to a reachability problem). Empirically, our algorithm can achieve strong performance even in low sample regimes.
Empirical Study of Off-Policy Policy Evaluation for Reinforcement Learning
Nov 15, 2019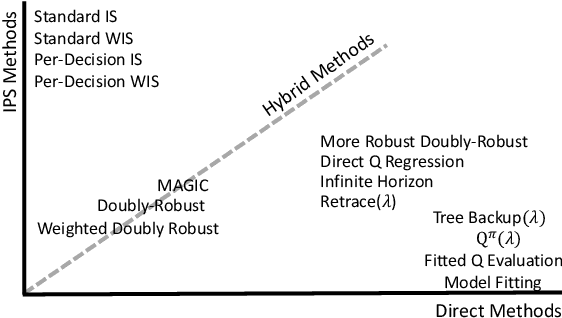


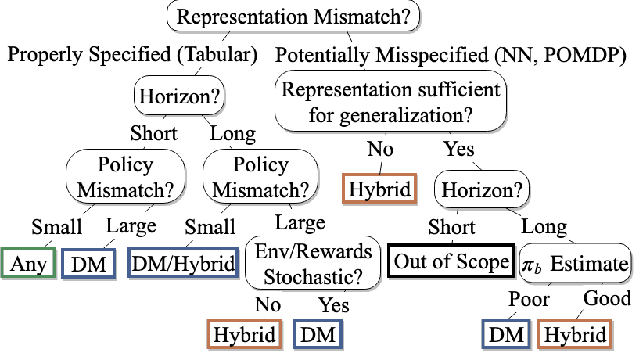
Off-policy policy evaluation (OPE) is the problem of estimating the online performance of a policy using only pre-collected historical data generated by another policy. Given the increasing interest in deploying learning-based methods for safety-critical applications, many recent OPE methods have recently been proposed. Due to disparate experimental conditions from recent literature, the relative performance of current OPE methods is not well understood. In this work, we present the first comprehensive empirical analysis of a broad suite of OPE methods. Based on thousands of experiments and detailed empirical analyses, we offer a summarized set of guidelines for effectively using OPE in practice, and suggest directions for future research.
Imitation-Projected Policy Gradient for Programmatic Reinforcement Learning
Jul 11, 2019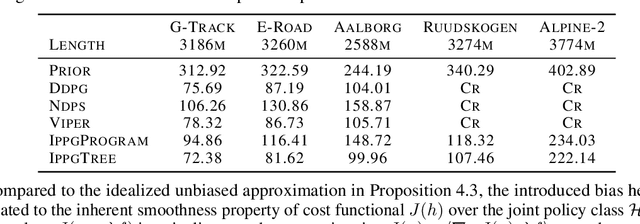

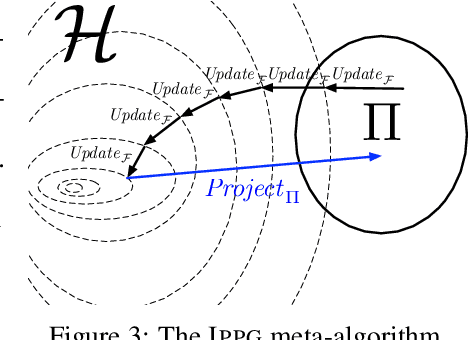
We present Imitation-Projected Policy Gradient (IPPG), an algorithmic framework for learning policies that are parsimoniously represented in a structured programming language. Such programmatic policies can be more interpretable, generalizable, and amenable to formal verification than neural policies; however, designing rigorous learning approaches for programmatic policies remains a challenge. IPPG, our response to this challenge, is based on three insights. First, we view our learning task as optimization in policy space, modulo the constraint that the desired policy has a programmatic representation, and solve this optimization problem using a "lift-and-project" perspective that takes a gradient step into the unconstrained policy space and then projects back onto the constrained space. Second, we view the unconstrained policy space as mixing neural and programmatic representations, which enables employing state-of-the-art deep policy gradient approaches. Third, we cast the projection step as program synthesis via imitation learning, and exploit contemporary combinatorial methods for this task. We present theoretical convergence results for IPPG, as well as an empirical evaluation in three continuous control domains. The experiments show that IPPG can significantly outperform state-of-the-art approaches for learning programmatic policies.
Batch Policy Learning under Constraints
Mar 20, 2019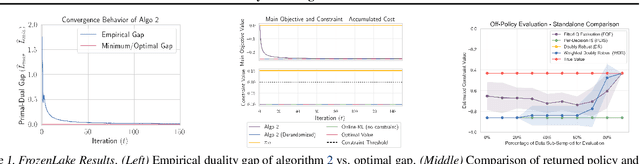
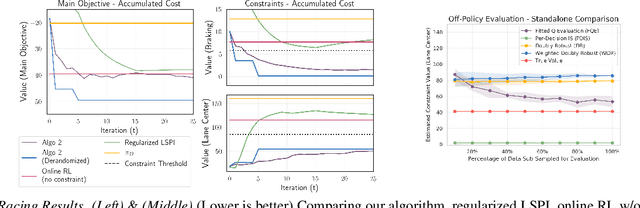
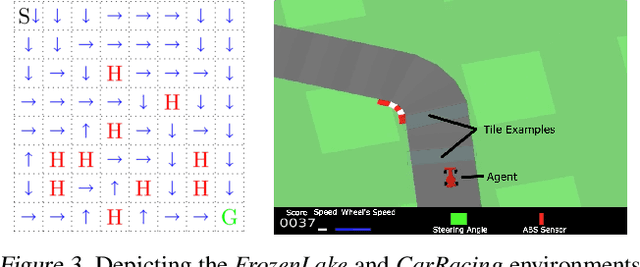
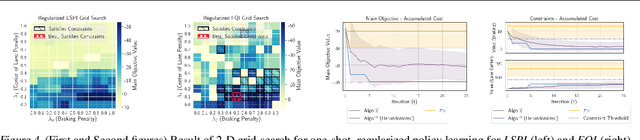
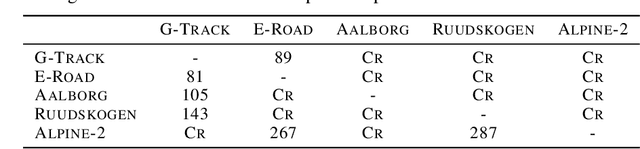
When learning policies for real-world domains, two important questions arise: (i) how to efficiently use pre-collected off-policy, non-optimal behavior data; and (ii) how to mediate among different competing objectives and constraints. We thus study the problem of batch policy learning under multiple constraints, and offer a systematic solution. We first propose a flexible meta-algorithm that admits any batch reinforcement learning and online learning procedure as subroutines. We then present a specific algorithmic instantiation and provide performance guarantees for the main objective and all constraints. To certify constraint satisfaction, we propose a new and simple method for off-policy policy evaluation (OPE) and derive PAC-style bounds. Our algorithm achieves strong empirical results in different domains, including in a challenging problem of simulated car driving subject to multiple constraints such as lane keeping and smooth driving. We also show experimentally that our OPE method outperforms other popular OPE techniques on a standalone basis, especially in a high-dimensional setting.
A Control Lyapunov Perspective on Episodic Learning via Projection to State Stability
Mar 18, 2019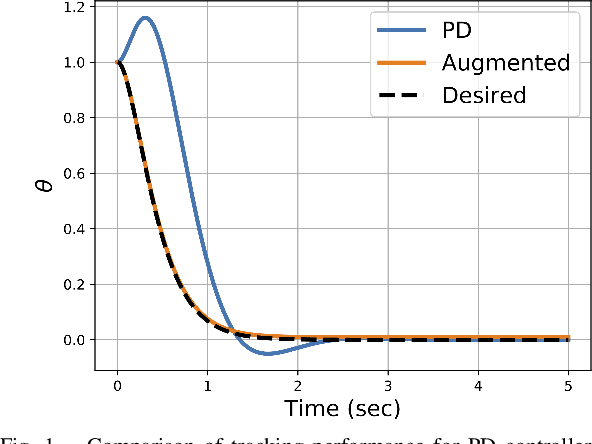
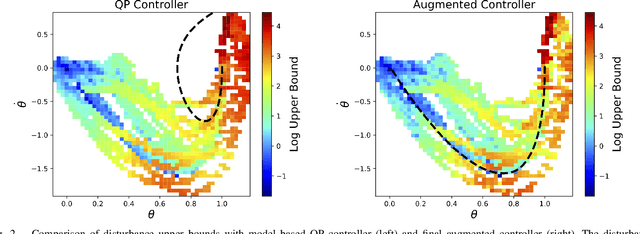
The goal of this paper is to understand the impact of learning on control synthesis from a Lyapunov function perspective. In particular, rather than consider uncertainties in the full system dynamics, we employ Control Lyapunov Functions (CLFs) as low-dimensional projections. To understand and characterize the uncertainty that these projected dynamics introduce in the system, we introduce a new notion: Projection to State Stability (PSS). PSS can be viewed as a variant of Input to State Stability defined on projected dynamics, and enables characterizing robustness of a CLF with respect to the data used to learn system uncertainties. We use PSS to bound uncertainty in affine control, and demonstrate that a practical episodic learning approach can use PSS to characterize uncertainty in the CLF for robust control synthesis.