 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semantic Segmentation Masks with Embeddings for Fine-Grained Form Classification
May 23, 2024



Efficient categorization of historical documents is crucial for fields such as genealogy, legal research, and historical scholarship, where manual classification is impractical for large collections due to its labor-intensive and error-prone nature. To address this, we propose a representational learning strategy that integrates semantic segmentation and deep learning models -- ResNets, CLIP, the Document Image Transformer (DiT), and masked auto-encoders (MAE) -- to generate embeddings that capture document features without predefined labels. To the best of our knowledge, we are the first to evaluate embeddings on fine-grained, unsupervised form classification. To improve these embeddings, we propose to first employ semantic segmentation as a preprocessing step. We contribute two novel datasets -- French 19th-century and U.S. 1950 Census records -- to demonstrate our approach. Our results show the effectiveness of these various embedding techniques in distinguishing similar document types and indicate that applying semantic segmentation can greatly improve clustering and classification results. The census datasets are available at \href{https://github.com/tahlor/census_forms}{https://github.com/tahlor/census\_forms}.
DELINE8K: A Synthetic Data Pipeline for the Semantic Segmentation of Historical Documents
Apr 30, 2024Document semantic segmentation is a promising avenue that can facilitate document analysis tasks, including optical character recognition (OCR), form classification, and document editing. Although several synthetic datasets have been developed to distinguish handwriting from printed text, they fall short in class variety and document diversity. We demonstrate the limitations of training on existing datasets when solving the National Archives Form Semantic Segmentation dataset (NAFSS), a dataset which we introduce. To address these limitations, we propose the most comprehensive document semantic segmentation synthesis pipeline to date, incorporating preprinted text, handwriting, and document backgrounds from over 10 sources to create the Document Element Layer INtegration Ensemble 8K, or DELINE8K dataset. Our customized dataset exhibits superior performance on the NAFSS benchmark, demonstrating it as a promising tool in further research. The DELINE8K dataset is available at https://github.com/Tahlor/deline8k.
Ego2HandsPose: A Dataset for Egocentric Two-hand 3D Global Pose Estimation
Jun 10, 2022
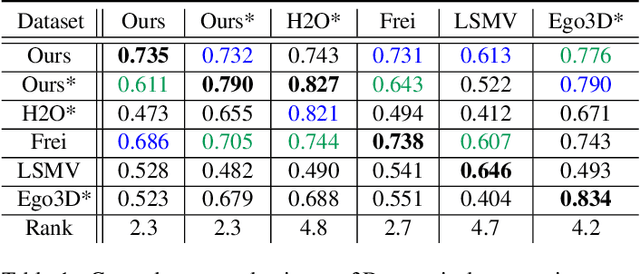
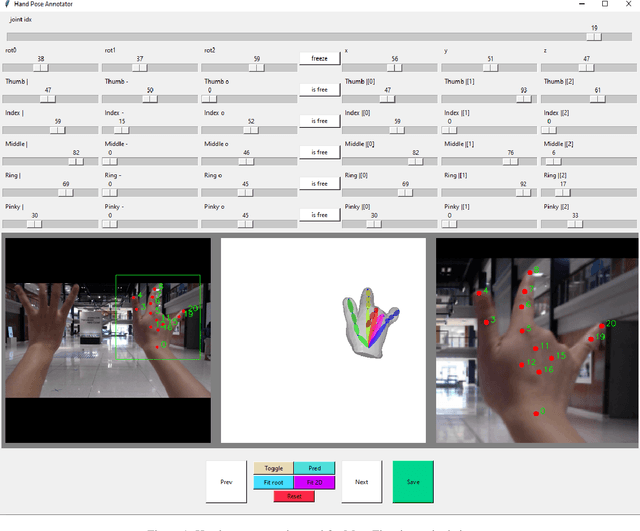
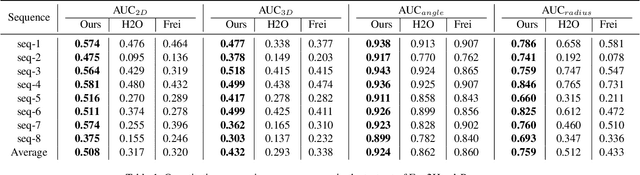
Color-based two-hand 3D pose estimation in the global coordinate system is essential in many applications. However, there are very few datasets dedicated to this task and no existing dataset supports estimation in a non-laboratory environment. This is largely attributed to the sophisticated data collection process required for 3D hand pose annotations, which also leads to difficulty in obtaining instances with the level of visual diversity needed for estimation in the wild. Progressing towards this goal, a large-scale dataset Ego2Hands was recently proposed to address the task of two-hand segmentation and detection in the wild. The proposed composition-based data generation technique can create two-hand instances with quality, quantity and diversity that generalize well to unseen domains. In this work, we present Ego2HandsPose, an extension of Ego2Hands that contains 3D hand pose annotation and is the first dataset that enables color-based two-hand 3D tracking in unseen domains. To this end, we develop a set of parametric fitting algorithms to enable 1) 3D hand pose annotation using a single image, 2) automatic conversion from 2D to 3D hand poses and 3) accurate two-hand tracking with temporal consistency. We provide incremental quantitative analysis on the multi-stage pipeline and show that training on our dataset achieves state-of-the-art results that significantly outperforms other datasets for the task of egocentric two-hand global 3D pose estimation.
Generalizing Interactive Backpropagating Refinement for Dense Prediction
Dec 22, 2021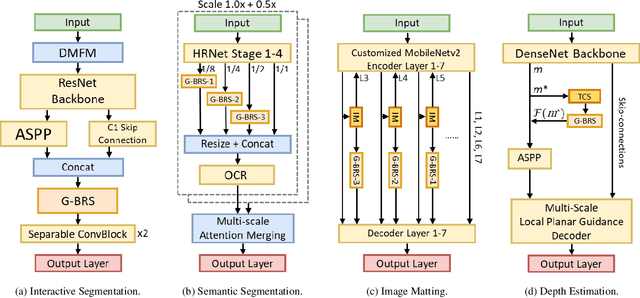


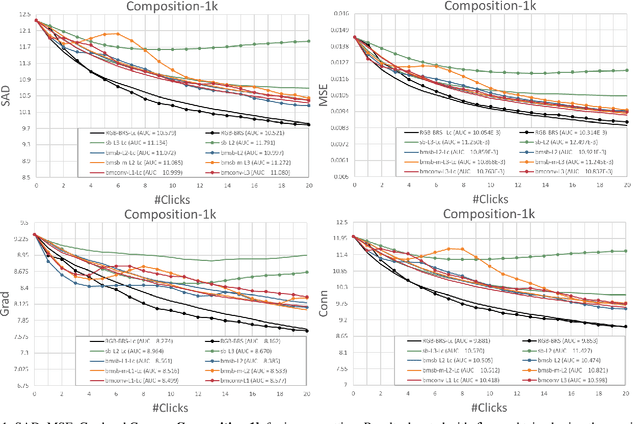
As deep neural networks become the state-of-the-art approach in the field of computer vision for dense prediction tasks, many methods have been developed for automatic estimation of the target outputs given the visual inputs. Although the estimation accuracy of the proposed automatic methods continues to improve, interactive refinement is oftentimes necessary for further correction. Recently, feature backpropagating refinement scheme (f-BRS) has been proposed for the task of interactive segmentation, which enables efficient optimization of a small set of auxiliary variables inserted into the pretrained network to produce object segmentation that better aligns with user inputs. However, the proposed auxiliary variables only contain channel-wise scale and bias, limiting the optimization to global refinement only. In this work, in order to generalize backpropagating refinement for a wide range of dense prediction tasks, we introduce a set of G-BRS (Generalized Backpropagating Refinement Scheme) layers that enable both global and localized refinement for the following tasks: interactive segmentation, semantic segmentation, image matting and monocular depth estimation. Experiments on SBD, Cityscapes, Mapillary Vista, Composition-1k and NYU-Depth-V2 show that our method can successfully generalize and significantly improve performance of existing pretrained state-of-the-art models with only a few clicks.
TRACE: A Differentiable Approach to Line-level Stroke Recovery for Offline Handwritten Text
May 24, 2021
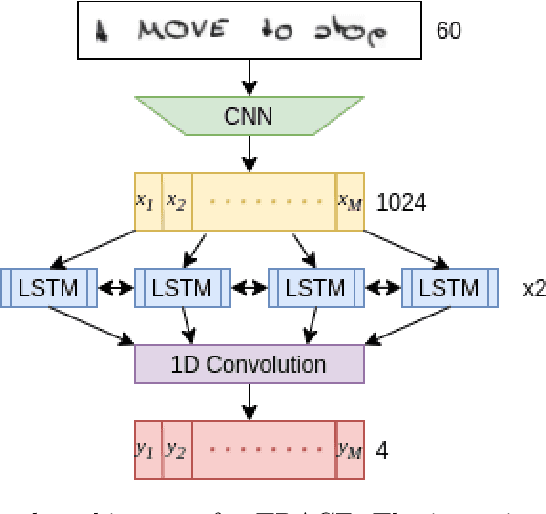
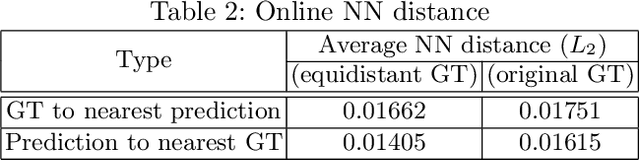
Stroke order and velocity are helpful features in the fields of signature verification, handwriting recognition, and handwriting synthesis. Recovering these features from offline handwritten text is a challenging and well-studied problem. We propose a new model called TRACE (Trajectory Recovery by an Adaptively-trained Convolutional Encoder). TRACE is a differentiable approach that uses a convolutional recurrent neural network (CRNN) to infer temporal stroke information from long lines of offline handwritten text with many characters and dynamic time warping (DTW) to align predictions and ground truth points. TRACE is perhaps the first system to be trained end-to-end on entire lines of text of arbitrary width and does not require the use of dynamic exemplars. Moreover, the system does not require images to undergo any pre-processing, nor do the predictions require any post-processing. Consequently, the recovered trajectory is differentiable and can be used as a loss function for other tasks, including synthesizing offline handwritten text. We demonstrate that temporal stroke information recovered by TRACE from offline data can be used for handwriting synthesis and establish the first benchmarks for a stroke trajectory recovery system trained on the IAM online handwriting dataset.
Ego2Hands: A Dataset for Egocentric Two-hand Segmentation and Detection
Nov 17, 2020
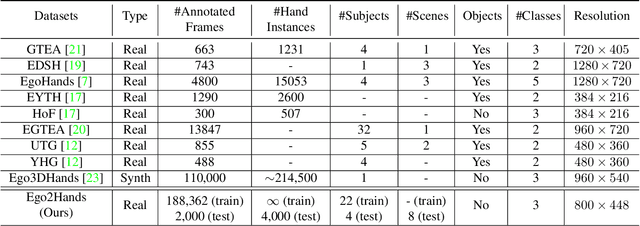
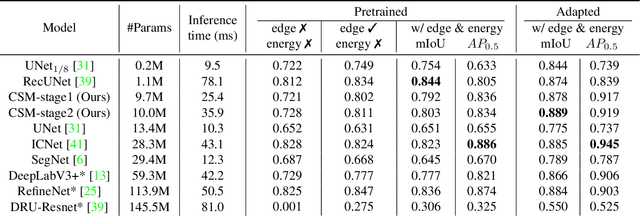
Hand segmentation and detection in truly unconstrained RGB-based settings is important for many applications. However, existing datasets are far from sufficient both in terms of size and variety due to the infeasibility of manual annotation of large amounts of segmentation and detection data. As a result, current methods are limited by many underlying assumptions such as constrained environment, consistent skin color and lighting. In this work, we present a large-scale RGB-based egocentric hand segmentation/detection dataset Ego2Hands that is automatically annotated and a color-invariant compositing-based data generation technique capable of creating unlimited training data with variety. For quantitative analysis, we manually annotated an evaluation set that significantly exceeds existing benchmarks in quantity, diversity and annotation accuracy. We show that our dataset and training technique can produce models that generalize to unseen environments without domain adaptation. We introduce Convolutional Segmentation Machine (CSM) as an architecture that better balances accuracy, size and speed and provide thorough analysis on the performance of state-of-the-art models on the Ego2Hands dataset.
Two-hand Global 3D Pose Estimation Using Monocular RGB
Jun 01, 2020
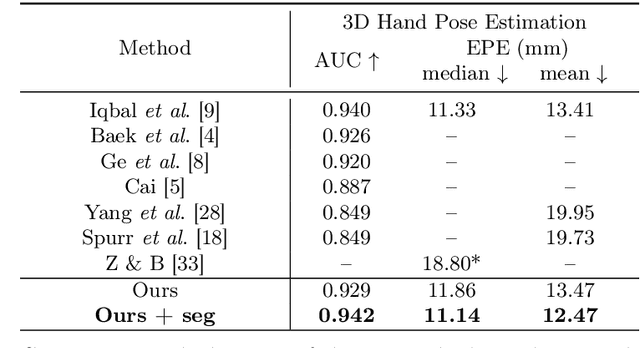

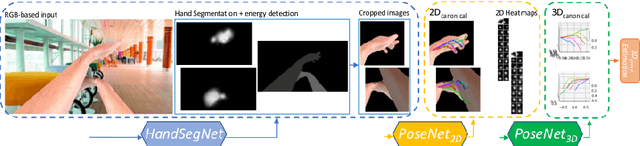
We tackle the challenging task of estimating global 3D joint locations for both hands via only monocular RGB input images. We propose a novel multi-stage convolutional neural network based pipeline that accurately segments and locates the hands despite occlusion between two hands and complex background noise and estimates the 2D and 3D canonical joint locations without any depth information. Global joint locations with respect to the camera origin are computed using the hand pose estimations and the actual length of the key bone with a novel projection algorithm. To train the CNNs for this new task, we introduce a large-scale synthetic 3D hand pose dataset. We demonstrate that our system outperforms previous works on 3D canonical hand pose estimation benchmark datasets with RGB-only information. Additionally, we present the first work that achieves accurate global 3D hand tracking on both hands using RGB-only inputs and provide extensive quantitative and qualitative evaluation.
Language Model Supervision for Handwriting Recognition Model Adaptation
Aug 04, 2018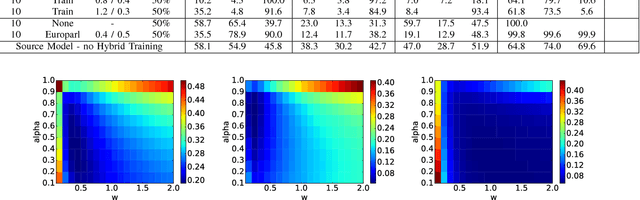
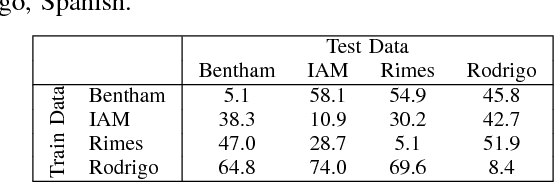
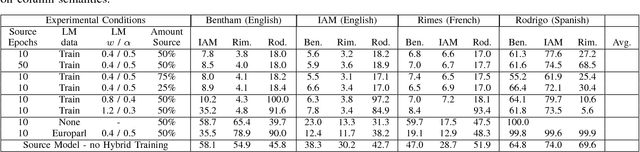
Training state-of-the-art offline handwriting recognition (HWR) models requires large labeled datasets, but unfortunately such datasets are not available in all languages and domains due to the high cost of manual labeling.We address this problem by showing how high resource languages can be leveraged to help train models for low resource languages.We propose a transfer learning methodology where we adapt HWR models trained on a source language to a target language that uses the same writing script.This methodology only requires labeled data in the source language, unlabeled data in the target language, and a language model of the target language. The language model is used in a bootstrapping fashion to refine predictions in the target language for use as ground truth in training the model.Using this approach we demonstrate improved transferability among French, English, and Spanish languages using both historical and modern handwriting datasets. In the best case, transferring with the proposed methodology results in character error rates nearly as good as full supervised training.
Convolutional Neural Networks for Font Classification
Aug 11, 2017
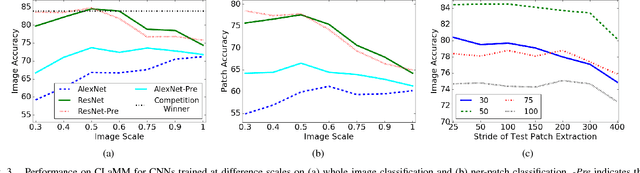
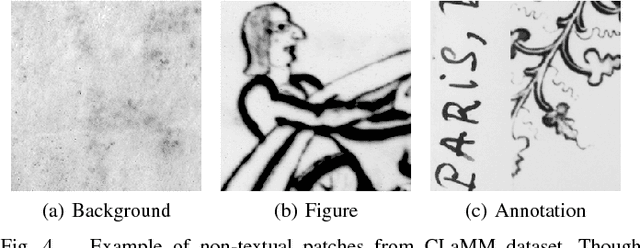
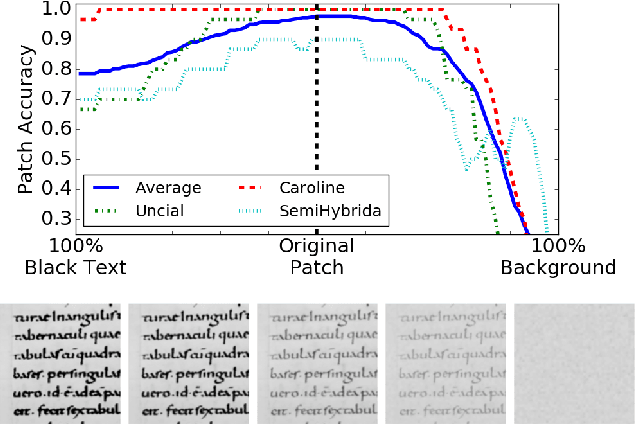
Classifying pages or text lines into font categories aids transcription because single font Optical Character Recognition (OCR) is generally more accurate than omni-font OCR. We present a simple framework based on Convolutional Neural Networks (CNNs), where a CNN is trained to classify small patches of text into predefined font classes. To classify page or line images, we average the CNN predictions over densely extracted patches. We show that this method achieves state-of-the-art performance on a challenging dataset of 40 Arabic computer fonts with 98.8\% line level accuracy. This same method also achieves the highest reported accuracy of 86.6% in predicting paleographic scribal script classes at the page level on medieval Latin manuscripts. Finally, we analyze what features are learned by the CNN on Latin manuscripts and find evidence that the CNN is learning both the defining morphological differences between scribal script classes as well as overfitting to class-correlated nuisance factors. We propose a novel form of data augmentation that improves robustness to text darkness, further increasing classification performance.
Document Image Binarization with Fully Convolutional Neural Networks
Aug 10, 2017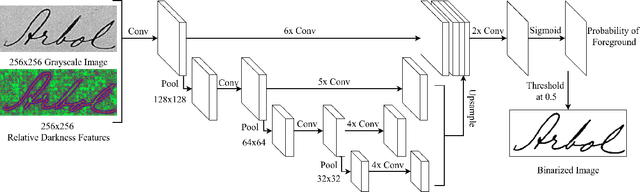

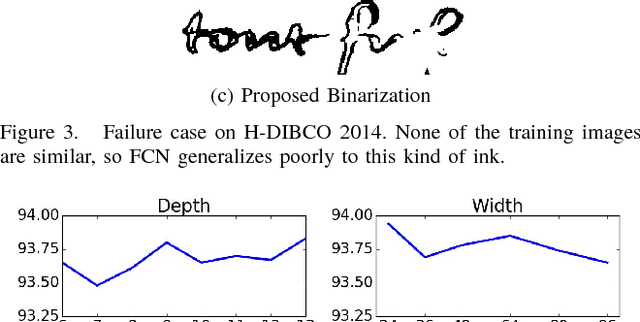
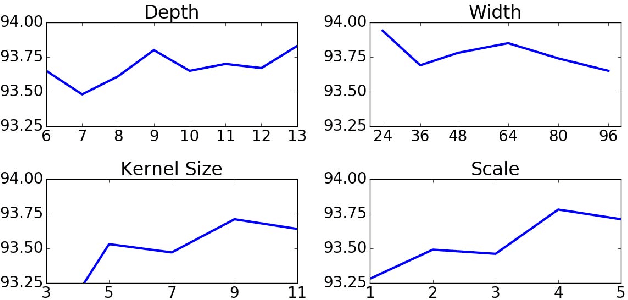
Binarization of degraded historical manuscript images is an important pre-processing step for many document processing tasks. We formulate binarization as a pixel classification learning task and apply a novel Fully Convolutional Network (FCN) architecture that operates at multiple image scales, including full resolution. The FCN is trained to optimize a continuous version of the Pseudo F-measure metric and an ensemble of FCNs outperform the competition winners on 4 of 7 DIBCO competitions. This same binarization technique can also be applied to different domains such as Palm Leaf Manuscripts with good performance. We analyze the performance of the proposed model w.r.t. the architectural hyperparameters, size and diversity of training data, and the input features chosen.