 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpolated SelectionConv for Spherical Images and Surfaces
Oct 18, 2022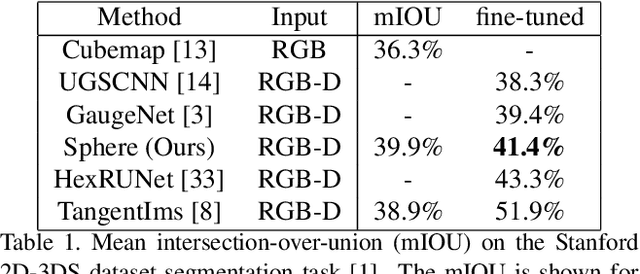


We present a new and general framework for convolutional neural network operations on spherical (or omnidirectional) images. Our approach represents the surface as a graph of connected points that doesn't rely on a particular sampling strategy. Additionally, by using an interpolated version of SelectionConv, we can operate on the sphere while using existing 2D CNNs and their weights. Since our method leverages existing graph implementations, it is also fast and can be fine-tuned efficiently. Our method is also general enough to be applied to any surface type, even those that are topologically non-simple. We demonstrate the effectiveness of our technique on the tasks of style transfer and segmentation for spheres as well as stylization for 3D meshes. We provide a thorough ablation study of the performance of various spherical sampling strategies.
SelectionConv: Convolutional Neural Networks for Non-rectilinear Image Data
Jul 18, 2022
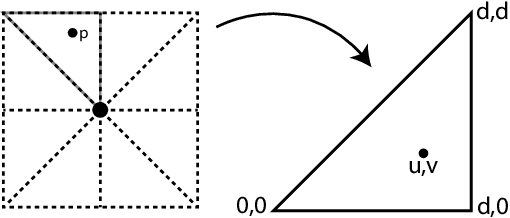
Convolutional Neural Networks have revolutionized vision applications. There are image domains and representations, however, that cannot be handled by standard CNNs (e.g., spherical images, superpixels). Such data are usually processed using networks and algorithms specialized for each type. In this work, we show that it may not always be necessary to use specialized neural networks to operate on such spaces. Instead, we introduce a new structured graph convolution operator that can copy 2D convolution weights, transferring the capabilities of already trained traditional CNNs to our new graph network. This network can then operate on any data that can be represented as a positional graph. By converting non-rectilinear data to a graph, we can apply these convolutions on these irregular image domains without requiring training on large domain-specific datasets. Results of transferring pre-trained image networks for segmentation, stylization, and depth prediction are demonstrated for a variety of such data forms.
End-to-end Document Recognition and Understanding with Dessurt
Mar 30, 2022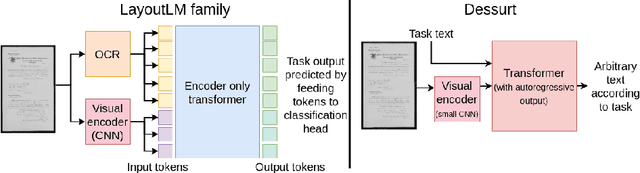


We introduce Dessurt, a relatively simple document understanding transformer capable of being fine-tuned on a greater variety of document tasks than prior methods. It receives a document image and task string as input and generates arbitrary text autoregressively as output. Because Dessurt is an end-to-end architecture that performs text recognition in addition to the document understanding, it does not require an external recognition model as prior methods do, making it easier to fine-tune to new visual domains. We show that this model is effective at 9 different dataset-task combinations.
Text and Style Conditioned GAN for Generation of Offline Handwriting Lines
Sep 01, 2020
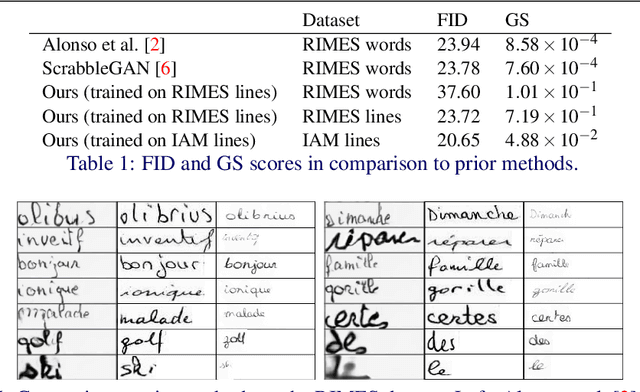
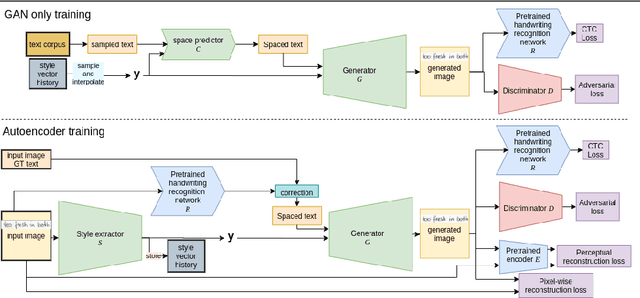
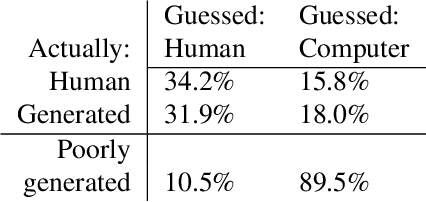
This paper presents a GAN for generating images of handwritten lines conditioned on arbitrary text and latent style vectors. Unlike prior work, which produce stroke points or single-word images, this model generates entire lines of offline handwriting. The model produces variable-sized images by using style vectors to determine character widths. A generator network is trained with GAN and autoencoder techniques to learn style, and uses a pre-trained handwriting recognition network to induce legibility. A study using human evaluators demonstrates that the model produces images that appear to be written by a human. After training, the encoder network can extract a style vector from an image, allowing images in a similar style to be generated, but with arbitrary text.
Style Transfer for Light Field Photography
Feb 25, 2020
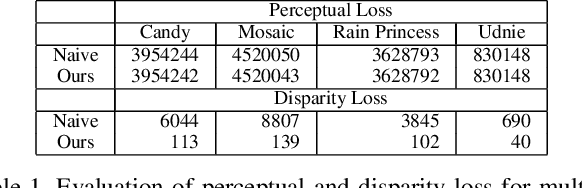

As light field images continue to increase in use and application, it becomes necessary to adapt existing image processing methods to this unique form of photography. In this paper we explore methods for applying neural style transfer to light field images. Feed-forward style transfer networks provide fast, high-quality results for monocular images, but no such networks exist for full light field images. Because of the size of these images, current light field data sets are small and are insufficient for training purely feed-forward style-transfer networks from scratch. Thus, it is necessary to adapt existing monocular style transfer networks in a way that allows for the stylization of each view of the light field while maintaining visual consistencies between views. Instead, the proposed method backpropagates the loss through the network, and the process is iterated to optimize (essentially overfit) the resulting stylization for a single light field image alone. The network architecture allows for the incorporation of pre-trained fast monocular stylization networks while avoiding the need for a large light field training set.
Deep Visual Template-Free Form Parsing
Sep 18, 2019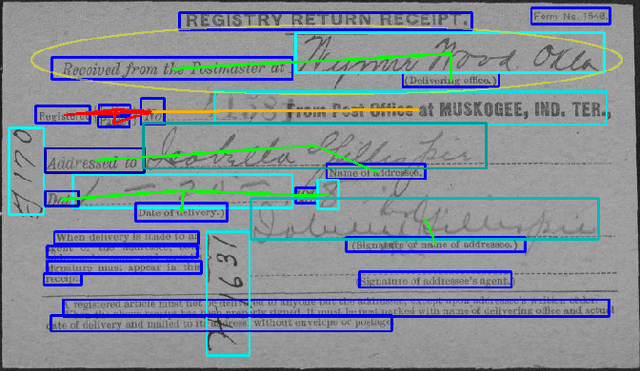


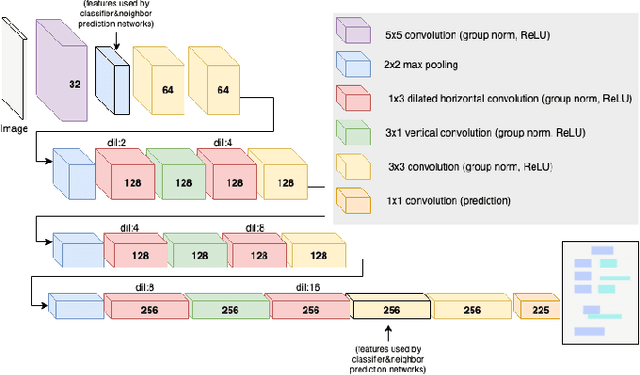
Automatic, template-free extraction of information from form images is challenging due to the variety of form layouts. This is even more challenging for historical forms due to noise and degradation. A crucial part of the extraction process is associating input text with pre-printed labels. We present a learned, template-free solution to detecting pre-printed text and input text/handwriting and predicting pair-wise relationships between them. While previous approaches to this problem have been focused on clean images and clear layouts, we show our approach is effective in the domain of noisy, degraded, and varied form images. We introduce a new dataset of historical form images (late 1800s, early 1900s) for training and validating our approach. Our method uses a convolutional network to detect pre-printed text and input text lines. We pool features from the detection network to classify possible relationships in a language-agnostic way. We show that our proposed pairing method outperforms heuristic rules and that visual features are critical to obtaining high accuracy.