 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-context Reference-based MT Quality Estimation
Sep 17, 2025In this paper, we present our submission to the Tenth Conference on Machine Translation (WMT25) Shared Task on Automated Translation Quality Evaluation. Our systems are built upon the COMET framework and trained to predict segment-level Error Span Annotation (ESA) scores using augmented long-context data. To construct long-context training data, we concatenate in-domain, human-annotated sentences and compute a weighted average of their scores. We integrate multiple human judgment datasets (MQM, SQM, and DA) by normalising their scales and train multilingual regression models to predict quality scores from the source, hypothesis, and reference translations. Experimental results show that incorporating long-context information improves correlations with human judgments compared to models trained only on short segments.
Synthetic vs. Gold: The Role of LLM-Generated Labels and Data in Cyberbullying Detection
Feb 21, 2025



This study investigates the role of LLM-generated synthetic data in cyberbullying detection. We conduct a series of experiments where we replace some or all of the authentic data with synthetic data, or augment the authentic data with synthetic data. We find that synthetic cyberbullying data can be the basis for training a classifier for harm detection that reaches performance close to that of a classifier trained with authentic data. Combining authentic with synthetic data shows improvements over the baseline of training on authentic data alone for the test data for all three LLMs tried. These results highlight the viability of synthetic data as a scalable, ethically viable alternative in cyberbullying detection while emphasizing the critical impact of LLM selection on performance outcomes.
A Systematic Review of Data-to-Text NLG
Feb 27, 2024



This systematic review undertakes a comprehensive analysis of current research on data-to-text generation, identifying gaps, challenges, and future directions within the field. Relevant literature in this field on datasets, evaluation metrics, application areas, multilingualism, language models, and hallucination mitigation methods is reviewed. Various methods for producing high-quality text are explored, addressing the challenge of hallucinations in data-to-text generation. These methods include re-ranking, traditional and neural pipeline architecture, planning architectures, data cleaning, controlled generation, and modification of models and training techniques. Their effectiveness and limitations are assessed, highlighting the need for universally applicable strategies to mitigate hallucinations. The review also examines the usage, popularity, and impact of datasets, alongside evaluation metrics, with an emphasis on both automatic and human assessment. Additionally, the evolution of data-to-text models, particularly the widespread adoption of transformer models, is discussed. Despite advancements in text quality, the review emphasizes the importance of research in low-resourced languages and the engineering of datasets in these languages to promote inclusivity. Finally, several application domains of data-to-text are highlighted, emphasizing their relevance in such domains. Overall, this review serves as a guiding framework for fostering innovation and advancing data-to-text generation.
DeepQC: A Deep Learning System for Automatic Quality Control of In-situ Soil Moisture Sensor Time Series Data
Nov 12, 2023



Amidst changing climate, real-time soil moisture monitoring is vital for the development of in-season decision support tools to help farmers manage weather related risks. Precision Sustainable Agriculture (PSA) recently established a real-time soil moisture monitoring network across the central, Midwest, and eastern U.S., but field-scale sensor observations often come with data gaps and anomalies. To maintain the data quality needed for development of decision tools, a quality control system is necessary. The International Soil Moisture Network (ISMN) introduced the Flagit module for anomaly detection in soil moisture observations. However, under certain conditions, Flagit's quality control approaches may underperform in identifying anomalies. Recently deep learning methods have been successfully applied to detect anomalies in time series data in various disciplines. However, their use in agriculture has not been yet investigated. This study focuses on developing a Bi-directional Long Short-Term Memory (LSTM) model, referred to as DeepQC, to identify anomalies in soil moisture data. Manual flagged PSA observations were used for training, validation, and testing the model, following an 80:10:10 split. The study then compared the DeepQC and Flagit based estimates to assess their relative performance. Flagit corrected flagged 95.5% of the corrected observations and 50.3% of the anomaly observations, indicating its limitations in identifying anomalies. On the other hand, the DeepQC correctly flagged 99.7% of the correct observations and 95.6% of the anomalies in significantly less time, demonstrating its superiority over Flagit approach. Importantly, DeepQC's performance remained consistent regardless of the number of anomalies. Given the promising results obtained with the DeepQC, future studies will focus on implementing this model on national and global soil moisture networks.
End-to-end Document Recognition and Understanding with Dessurt
Mar 30, 2022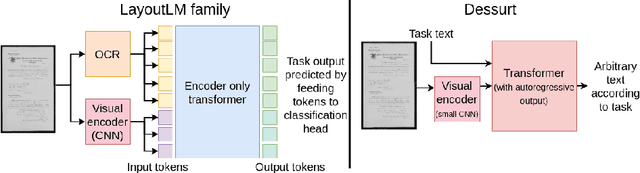


We introduce Dessurt, a relatively simple document understanding transformer capable of being fine-tuned on a greater variety of document tasks than prior methods. It receives a document image and task string as input and generates arbitrary text autoregressively as output. Because Dessurt is an end-to-end architecture that performs text recognition in addition to the document understanding, it does not require an external recognition model as prior methods do, making it easier to fine-tune to new visual domains. We show that this model is effective at 9 different dataset-task combinations.
Optimal Inverted Landing in a Small Aerial Robot with Varied Approach Velocities and Landing Gear Designs
Nov 05, 2021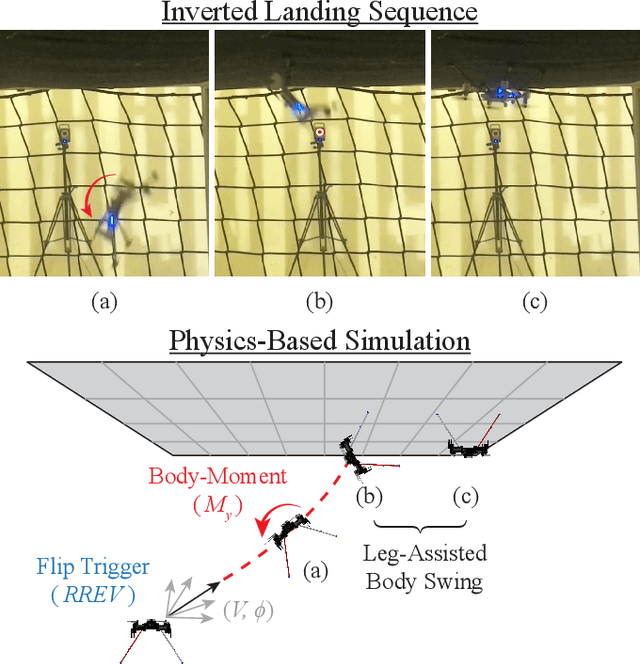
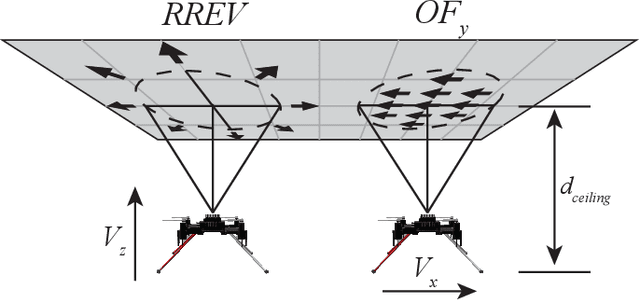
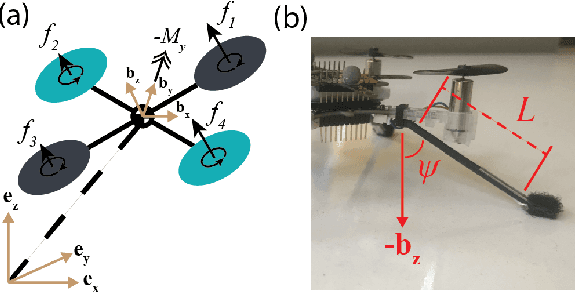
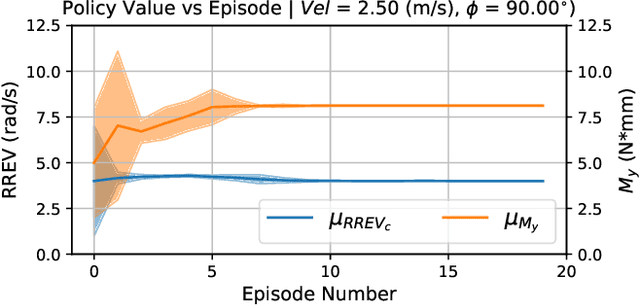
Inverted landing is a challenging feat to perform in aerial robots, especially without external positioning. However, it is routinely performed by biological fliers such as bees, flies, and bats. Our previous observations of landing behaviors in flies suggest an open-loop causal relationship between their putative visual cues and the kinematics of the aerial maneuvers executed. For example, the degree of rotational maneuver (therefore the body inversion prior to touchdown) and the amount of leg-assisted body swing both depend on the flies' initial body states while approaching the ceiling. In this work, by using a physics-based simulation with experimental validation, we systematically investigated how optimized inverted landing maneuvers depend on the initial approach velocities with varied magnitude and direction. This was done by analyzing the putative visual cues (that can be derived from onboard measurements) during optimal maneuvering trajectories. We identified a three-dimensional policy region, from which a mapping to a global inverted landing policy can be developed without the use of external positioning data. In addition, we also investigated the effects of an array of landing gear designs on the optimized landing performance and identified their advantages and disadvantages. The above results have been partially validated using limited experimental testing and will continue to inform and guide our future experiments, for example by applying the calculated global policy.
Visual FUDGE: Form Understanding via Dynamic Graph Editing
May 17, 2021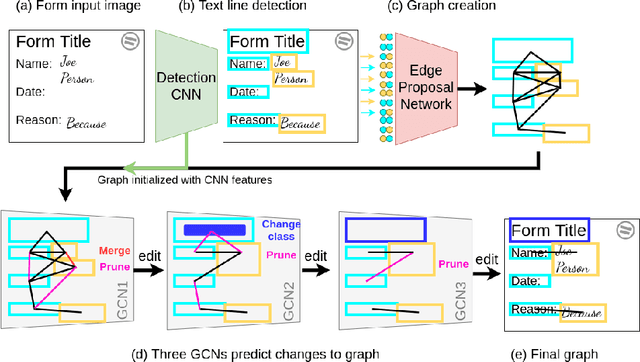
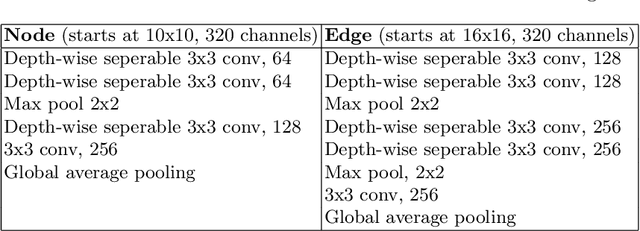
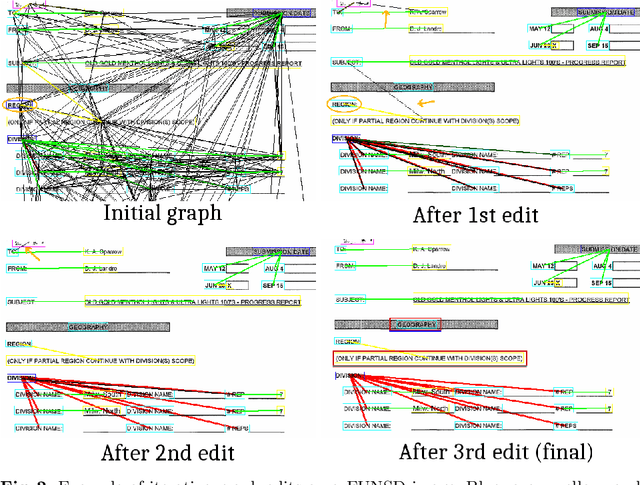
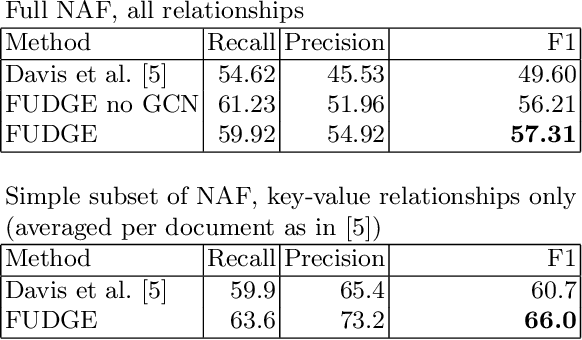
We address the problem of form understanding: finding text entities and the relationships/links between them in form images. The proposed FUDGE model formulates this problem on a graph of text elements (the vertices) and uses a Graph Convolutional Network to predict changes to the graph. The initial vertices are detected text lines and do not necessarily correspond to the final text entities, which can span multiple lines. Also, initial edges contain many false-positive relationships. FUDGE edits the graph structure by combining text segments (graph vertices) and pruning edges in an iterative fashion to obtain the final text entities and relationships. While recent work in this area has focused on leveraging large-scale pre-trained Language Models (LM), FUDGE achieves the same level of entity linking performance on the FUNSD dataset by learning only visual features from the (small) provided training set. FUDGE can be applied on forms where text recognition is difficult (e.g. degraded or historical forms) and on forms in resource-poor languages where pre-training such LMs is challenging. FUDGE is state-of-the-art on the historical NAF dataset.
Over a Decade of Social Opinion Mining
Dec 05, 2020
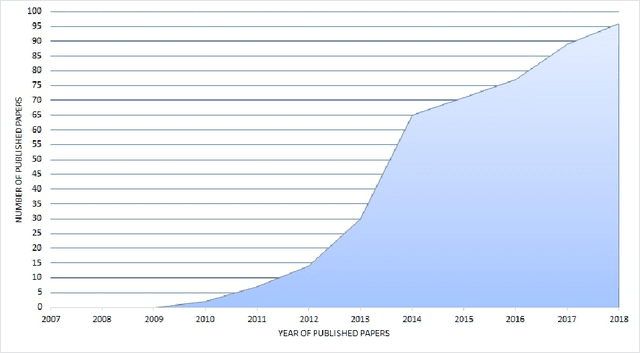
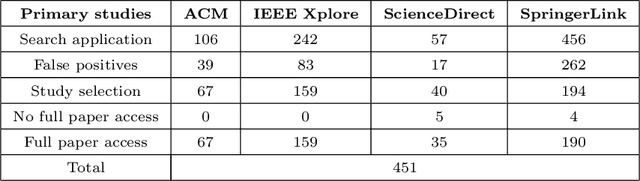
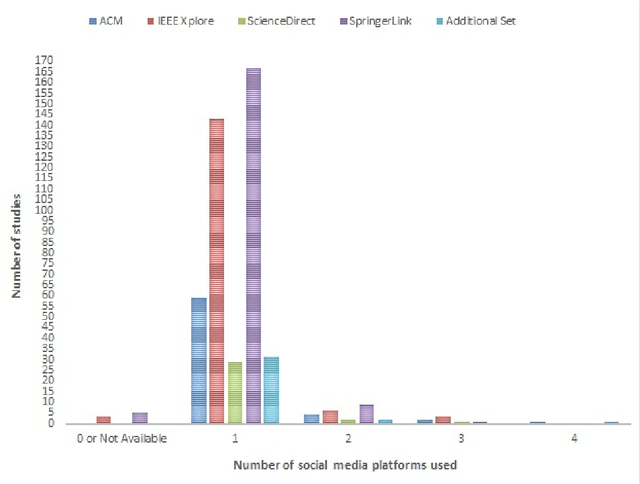
Social media popularity and importance is on the increase, due to people using it for various types of social interaction across multiple channels. This social interaction by online users includes submission of feedback, opinions and recommendations about various individuals, entities, topics, and events. This systematic review focuses on the evolving research area of Social Opinion Mining, tasked with the identification of multiple opinion dimensions, such as subjectivity, sentiment polarity, emotion, affect, sarcasm and irony, from user-generated content represented across multiple social media platforms and in various media formats, like text, image, video and audio. Therefore, through Social Opinion Mining, natural language can be understood in terms of the different opinion dimensions, as expressed by humans. This contributes towards the evolution of Artificial Intelligence, which in turn helps the advancement of several real-world use cases, such as customer service and decision making. A thorough systematic review was carried out on Social Opinion Mining research which totals 485 studies and spans a period of twelve years between 2007 and 2018. The in-depth analysis focuses on the social media platforms, techniques, social datasets, language, modality, tools and technologies, natural language processing tasks and other aspects derived from the published studies. Such multi-source information fusion plays a fundamental role in mining of people's social opinions from social media platforms. These can be utilised in many application areas, ranging from marketing, advertising and sales for product/service management, and in multiple domains and industries, such as politics, technology, finance, healthcare, sports and government. Future research directions are presented, whereas further research and development has the potential of leaving a wider academic and societal impact.
Text and Style Conditioned GAN for Generation of Offline Handwriting Lines
Sep 01, 2020
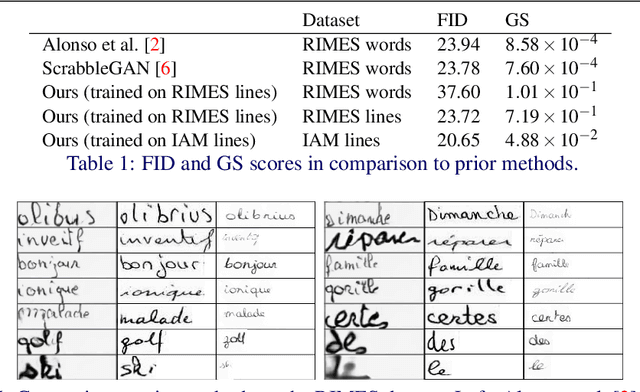
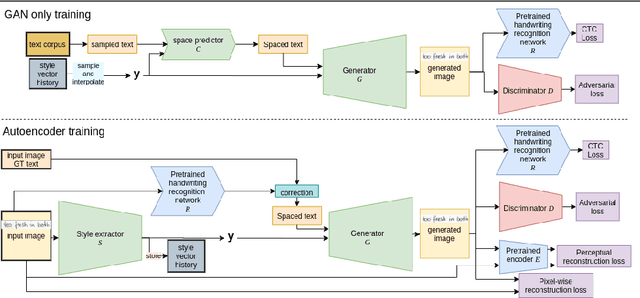
This paper presents a GAN for generating images of handwritten lines conditioned on arbitrary text and latent style vectors. Unlike prior work, which produce stroke points or single-word images, this model generates entire lines of offline handwriting. The model produces variable-sized images by using style vectors to determine character widths. A generator network is trained with GAN and autoencoder techniques to learn style, and uses a pre-trained handwriting recognition network to induce legibility. A study using human evaluators demonstrates that the model produces images that appear to be written by a human. After training, the encoder network can extract a style vector from an image, allowing images in a similar style to be generated, but with arbitrary text.
Deep Visual Template-Free Form Parsing
Sep 18, 2019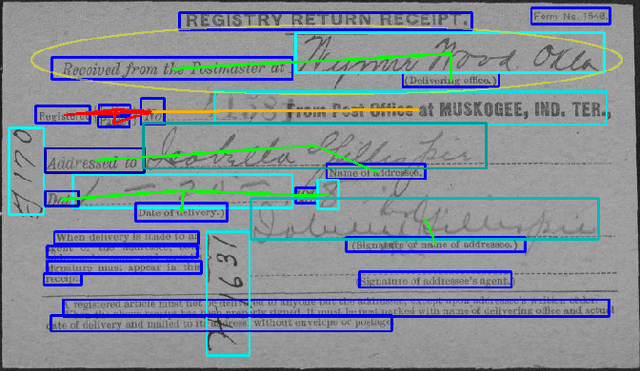


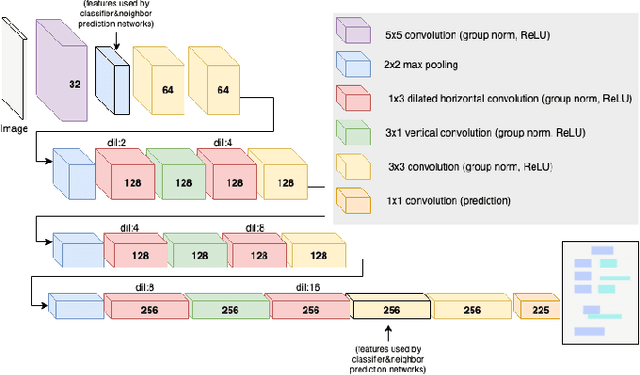
Automatic, template-free extraction of information from form images is challenging due to the variety of form layouts. This is even more challenging for historical forms due to noise and degradation. A crucial part of the extraction process is associating input text with pre-printed labels. We present a learned, template-free solution to detecting pre-printed text and input text/handwriting and predicting pair-wise relationships between them. While previous approaches to this problem have been focused on clean images and clear layouts, we show our approach is effective in the domain of noisy, degraded, and varied form images. We introduce a new dataset of historical form images (late 1800s, early 1900s) for training and validating our approach. Our method uses a convolutional network to detect pre-printed text and input text lines. We pool features from the detection network to classify possible relationships in a language-agnostic way. We show that our proposed pairing method outperforms heuristic rules and that visual features are critical to obtaining high accuracy.