 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2.5D Visual Relationship Detection
Apr 26, 2021
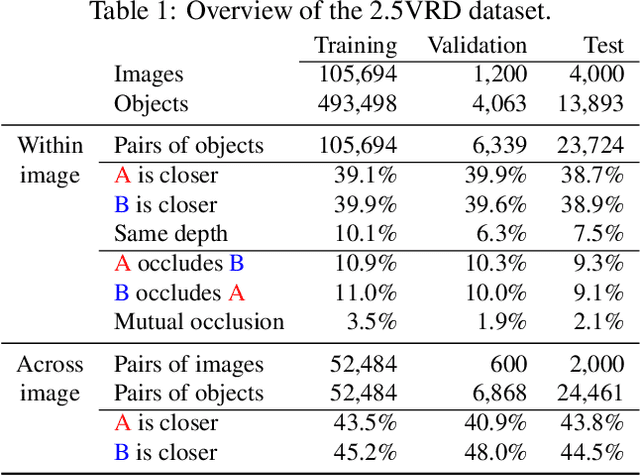
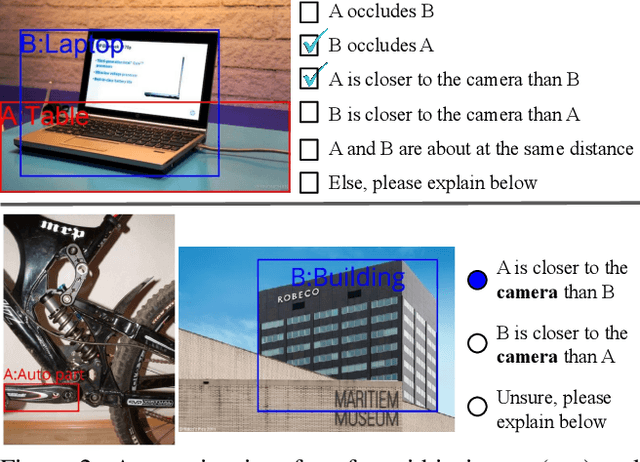

Visual 2.5D perception involves understanding the semantics and geometry of a scene through reasoning about object relationships with respect to the viewer in an environment. However, existing works in visual recognition primarily focus on the semantics. To bridge this gap, we study 2.5D visual relationship detection (2.5VRD), in which the goal is to jointly detect objects and predict their relative depth and occlusion relationships. Unlike general VRD, 2.5VRD is egocentric, using the camera's viewpoint as a common reference for all 2.5D relationships. Unlike depth estimation, 2.5VRD is object-centric and not only focuses on depth. To enable progress on this task, we create a new dataset consisting of 220k human-annotated 2.5D relationships among 512K objects from 11K images. We analyze this dataset and conduct extensive experiments including benchmarking multiple state-of-the-art VRD models on this task. Our results show that existing models largely rely on semantic cues and simple heuristics to solve 2.5VRD, motivating further research on models for 2.5D perception. The new dataset is available at https://github.com/google-research-datasets/2.5vrd.
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
Apr 22, 2021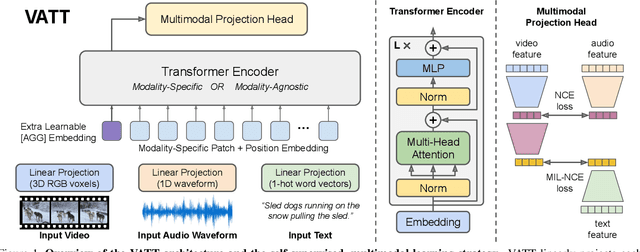
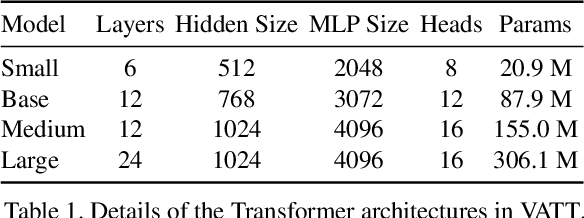
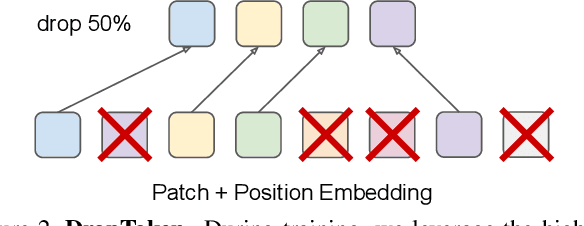
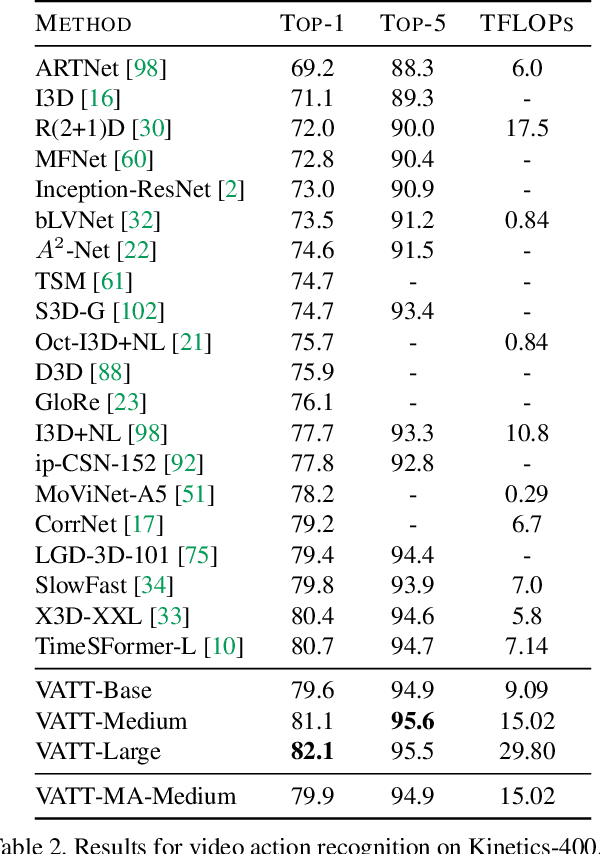
We present a framework for learning multimodal representations from unlabeled data using convolution-free Transformer architectures. Specifically, our Video-Audio-Text Transformer (VATT) takes raw signals as inputs and extracts multimodal representations that are rich enough to benefit a variety of downstream tasks. We train VATT end-to-end from scratch using multimodal contrastive losses and evaluate its performance by the downstream tasks of video action recognition, audio event classification, image classification, and text-to-video retrieval. Furthermore, we study a modality-agnostic single-backbone Transformer by sharing weights among the three modalities. We show that the convolution-free VATT outperforms state-of-the-art ConvNet-based architectures in the downstream tasks. Especially, VATT's vision Transformer achieves the top-1 accuracy of 82.1% on Kinetics-400, 83.6% on Kinetics-600,and 41.1% on Moments in Time, new records while avoiding supervised pre-training. Transferring to image classification leads to 78.7% top-1 accuracy on ImageNet compared to 64.7% by training the same Transformer from scratch, showing the generalizability of our model despite the domain gap between videos and images. VATT's audio Transformer also sets a new record on waveform-based audio event recognition by achieving the mAP of 39.4% on AudioSet without any supervised pre-training.
MoViNets: Mobile Video Networks for Efficient Video Recognition
Apr 18, 2021



We present Mobile Video Networks (MoViNets), a family of computation and memory efficient video networks that can operate on streaming video for online inference. 3D convolutional neural networks (CNNs) are accurate at video recognition but require large computation and memory budgets and do not support online inference, making them difficult to work on mobile devices. We propose a three-step approach to improve computational efficiency while substantially reducing the peak memory usage of 3D CNNs. First, we design a video network search space and employ neural architecture search to generate efficient and diverse 3D CNN architectures. Second, we introduce the Stream Buffer technique that decouples memory from video clip duration, allowing 3D CNNs to embed arbitrary-length streaming video sequences for both training and inference with a small constant memory footprint. Third, we propose a simple ensembling technique to improve accuracy further without sacrificing efficiency. These three progressive techniques allow MoViNets to achieve state-of-the-art accuracy and efficiency on the Kinetics, Moments in Time, and Charades video action recognition datasets. For instance, MoViNet-A5-Stream achieves the same accuracy as X3D-XL on Kinetics 600 while requiring 80% fewer FLOPs and 65% less memory. Code will be made available at https://github.com/tensorflow/models/tree/master/official/vision.
Class-Balanced Distillation for Long-Tailed Visual Recognition
Apr 12, 2021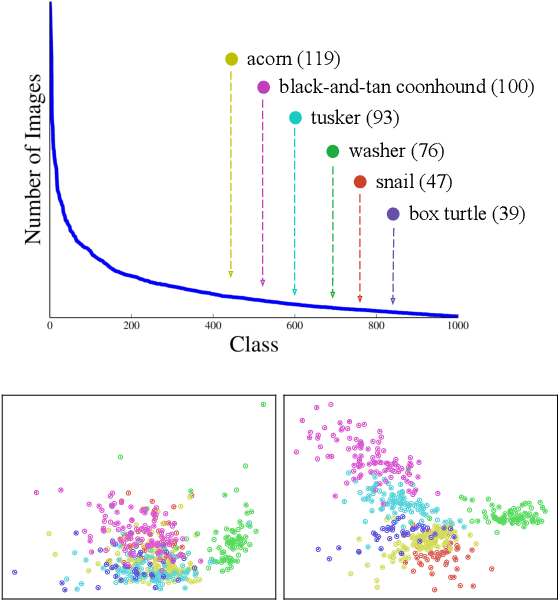

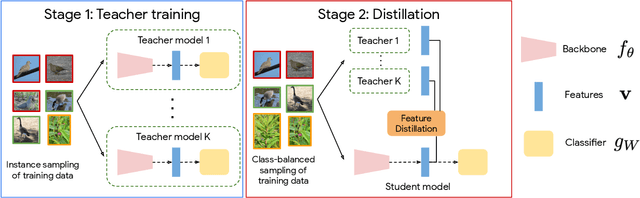
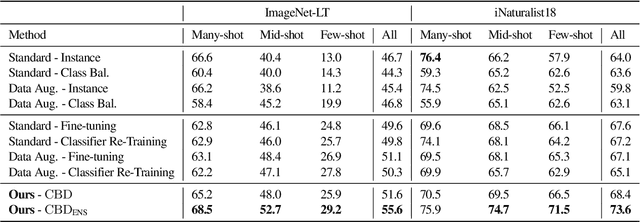
Real-world imagery is often characterized by a significant imbalance of the number of images per class, leading to long-tailed distributions. An effective and simple approach to long-tailed visual recognition is to learn feature representations and a classifier separately, with instance and class-balanced sampling, respectively. In this work, we introduce a new framework, by making the key observation that a feature representation learned with instance sampling is far from optimal in a long-tailed setting. Our main contribution is a new training method, referred to as Class-Balanced Distillation (CBD), that leverages knowledge distillation to enhance feature representations. CBD allows the feature representation to evolve in the second training stage, guided by the teacher learned in the first stage. The second stage uses class-balanced sampling, in order to focus on under-represented classes. This framework can naturally accommodate the usage of multiple teachers, unlocking the information from an ensemble of models to enhance recognition capabilities. Our experiments show that the proposed technique consistently outperforms the state of the art on long-tailed recognition benchmarks such as ImageNet-LT, iNaturalist17 and iNaturalist18. The experiments also show that our method does not sacrifice the accuracy of head classes to improve the performance of tail classes, unlike most existing work.
Robust and Accurate Object Detection via Adversarial Learning
Mar 26, 2021
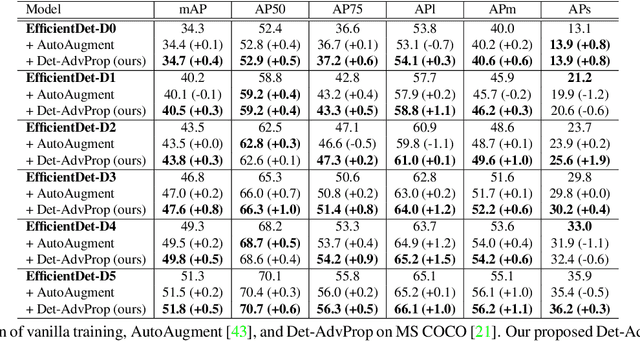
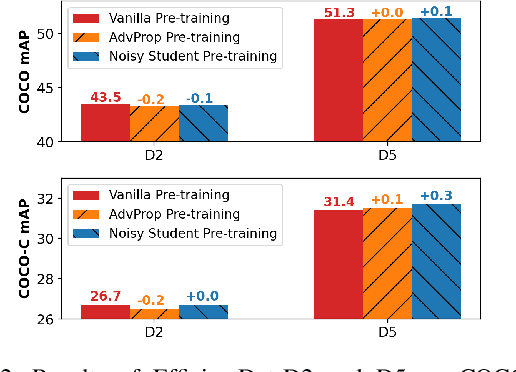
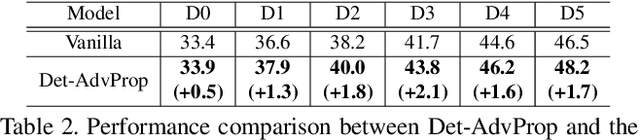
Data augmentation has become a de facto component for training high-performance deep image classifiers, but its potential is under-explored for object detection. Noting that most state-of-the-art object detectors benefit from fine-tuning a pre-trained classifier, we first study how the classifiers' gains from various data augmentations transfer to object detection. The results are discouraging; the gains diminish after fine-tuning in terms of either accuracy or robustness. This work instead augments the fine-tuning stage for object detectors by exploring adversarial examples, which can be viewed as a model-dependent data augmentation. Our method dynamically selects the stronger adversarial images sourced from a detector's classification and localization branches and evolves with the detector to ensure the augmentation policy stays current and relevant. This model-dependent augmentation generalizes to different object detectors better than AutoAugment, a model-agnostic augmentation policy searched based on one particular detector. Our approach boosts the performance of state-of-the-art EfficientDets by +1.1 mAP on the COCO object detection benchmark. It also improves the detectors' robustness against natural distortions by +3.8 mAP and against domain shift by +1.3 mAP. Models are available at https://github.com/google/automl/tree/master/efficientdet/Det-AdvProp.md
A Simple and Effective Use of Object-Centric Images for Long-Tailed Object Detection
Feb 17, 2021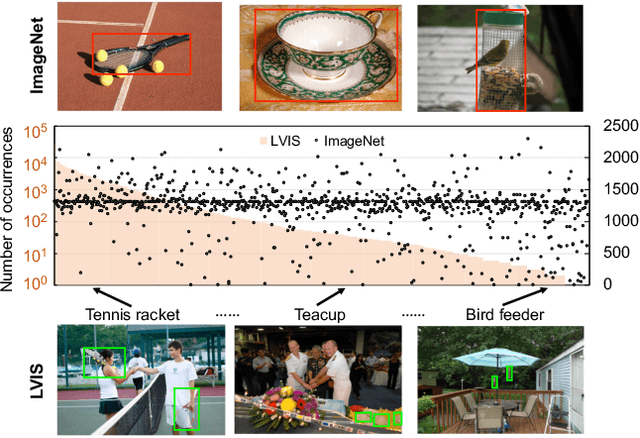
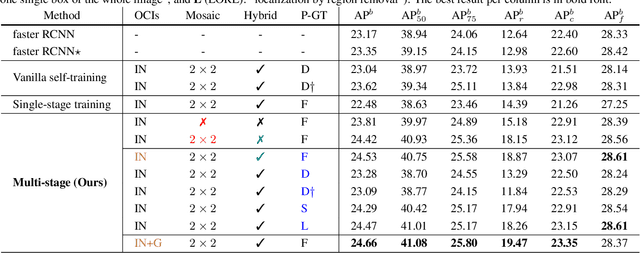

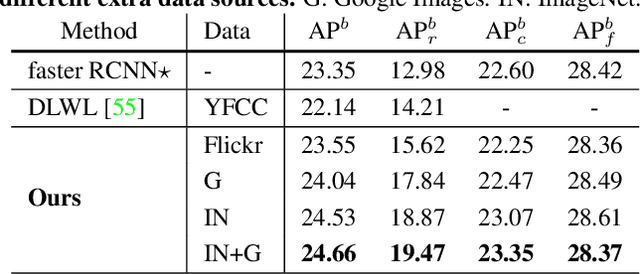
Object frequencies in daily scenes follow a long-tailed distribution. Many objects do not appear frequently enough in scene-centric images (e.g., sightseeing, street views) for us to train accurate object detectors. In contrast, these objects are captured at a higher frequency in object-centric images, which are intended to picture the objects of interest. Motivated by this phenomenon, we propose to take advantage of the object-centric images to improve object detection in scene-centric images. We present a simple yet surprisingly effective framework to do so. On the one hand, our approach turns an object-centric image into a useful training example for object detection in scene-centric images by mitigating the domain gap between the two image sources in both the input and label space. On the other hand, our approach employs a multi-stage procedure to train the object detector, such that the detector learns the diverse object appearances from object-centric images while being tied to the application domain of scene-centric images. On the LVIS dataset, our approach can improve the object detection (and instance segmentation) accuracy of rare objects by 50% (and 33%) relatively, without sacrificing the performance of other classes.
Large-Scale Meta-Learning with Continual Trajectory Shifting
Feb 14, 2021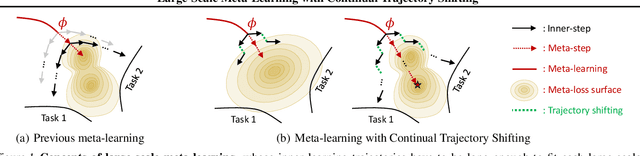
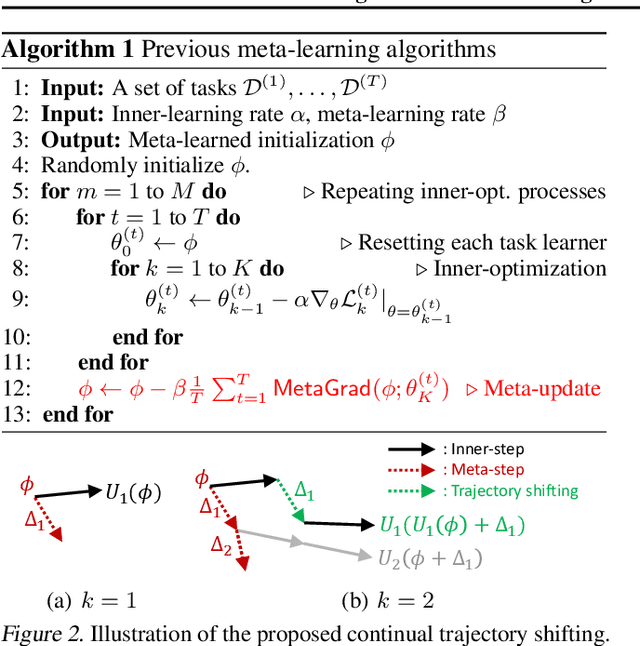
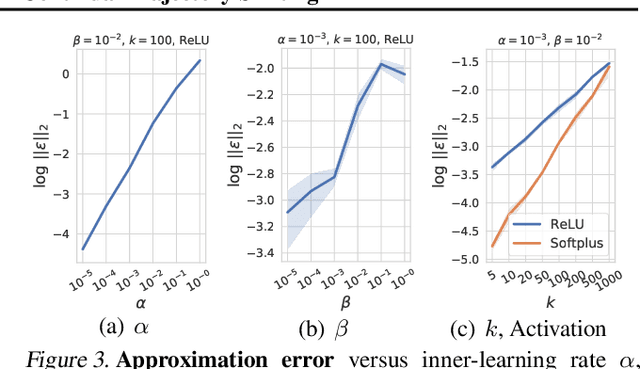

Meta-learning of shared initialization parameters has shown to be highly effective in solving few-shot learning tasks. However, extending the framework to many-shot scenarios, which may further enhance its practicality, has been relatively overlooked due to the technical difficulties of meta-learning over long chains of inner-gradient steps. In this paper, we first show that allowing the meta-learners to take a larger number of inner gradient steps better captures the structure of heterogeneous and large-scale task distributions, thus results in obtaining better initialization points. Further, in order to increase the frequency of meta-updates even with the excessively long inner-optimization trajectories, we propose to estimate the required shift of the task-specific parameters with respect to the change of the initialization parameters. By doing so, we can arbitrarily increase the frequency of meta-updates and thus greatly improve the meta-level convergence as well as the quality of the learned initializations. We validate our method on a heterogeneous set of large-scale tasks and show that the algorithm largely outperforms the previous first-order meta-learning methods in terms of both generalization performance and convergence, as well as multi-task learning and fine-tuning baselines.
Contrastive Learning for Label-Efficient Semantic Segmentation
Dec 23, 2020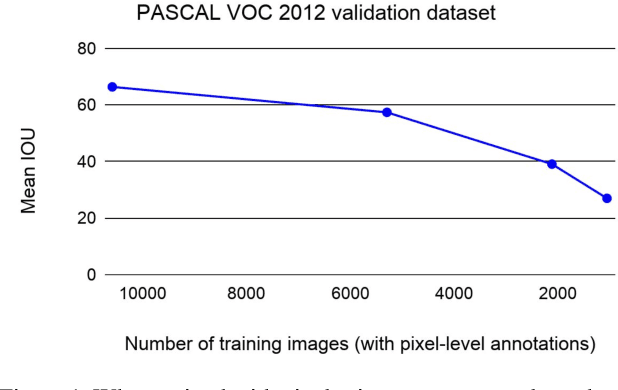



Collecting labeled data for the task of semantic segmentation is expensive and time-consuming, as it requires dense pixel-level annotations. While recent Convolutional Neural Network (CNN) based semantic segmentation approaches have achieved impressive results by using large amounts of labeled training data, their performance drops significantly as the amount of labeled data decreases. This happens because deep CNNs trained with the de facto cross-entropy loss can easily overfit to small amounts of labeled data. To address this issue, we propose a simple and effective contrastive learning-based training strategy in which we first pretrain the network using a pixel-wise class label-based contrastive loss, and then fine-tune it using the cross-entropy loss. This approach increases intra-class compactness and inter-class separability thereby resulting in a better pixel classifier. We demonstrate the effectiveness of the proposed training strategy in both fully-supervised and semi-supervised settings using the Cityscapes and PASCAL VOC 2012 segmentation datasets. Our results show that pretraining with label-based contrastive loss results in large performance gains (more than 20% absolute improvement in some settings) when the amount of labeled data is limited.
Ranking Neural Checkpoints
Nov 23, 2020
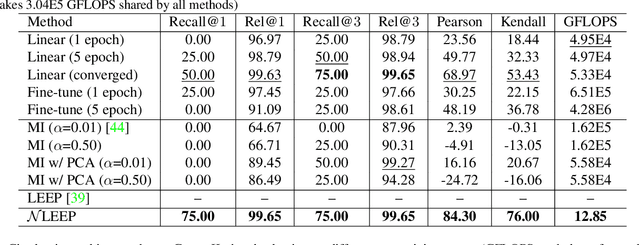
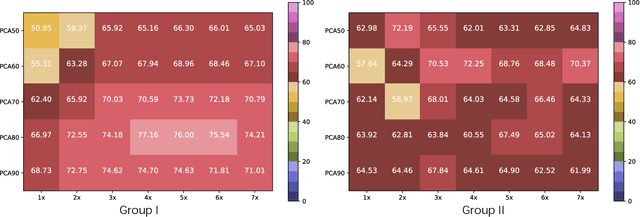
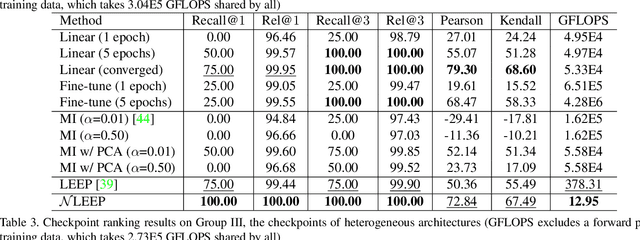
This paper is concerned with ranking many pre-trained deep neural networks (DNNs), called checkpoints, for the transfer learning to a downstream task. Thanks to the broad use of DNNs, we may easily collect hundreds of checkpoints from various sources. Which of them transfers the best to our downstream task of interest? Striving to answer this question thoroughly, we establish a neural checkpoint ranking benchmark (NeuCRaB) and study some intuitive ranking measures. These measures are generic, applying to the checkpoints of different output types without knowing how the checkpoints are pre-trained on which dataset. They also incur low computation cost, making them practically meaningful. Our results suggest that the linear separability of the features extracted by the checkpoints is a strong indicator of transferability. We also arrive at a new ranking measure, NLEEP, which gives rise to the best performance in the experiments.
Spatiotemporal Contrastive Video Representation Learning
Aug 09, 2020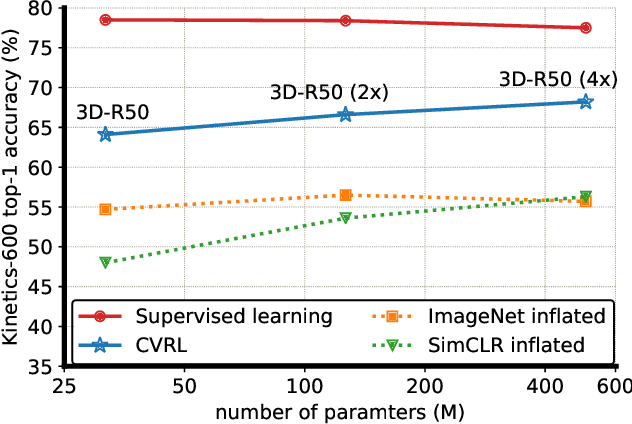

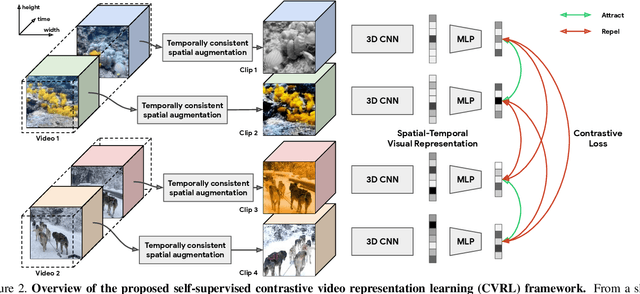
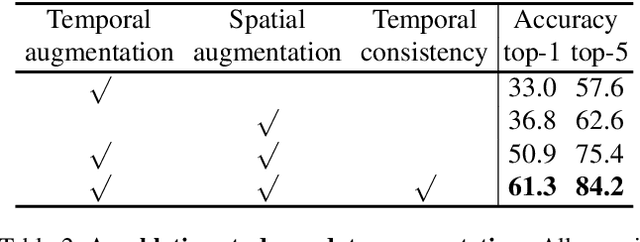
We present a self-supervised Contrastive Video Representation Learning (CVRL) method to learn spatiotemporal visual representations from unlabeled videos. Inspired by the recently proposed self-supervised contrastive learning framework, our representations are learned using a contrastive loss, where two clips from the same short video are pulled together in the embedding space, while clips from different videos are pushed away. We study what makes for good data augmentation for video self-supervised learning and find both spatial and temporal information are crucial. In particular, we propose a simple yet effective temporally consistent spatial augmentation method to impose strong spatial augmentations on each frame of a video clip while maintaining the temporal consistency across frames. For Kinetics-600 action recognition, a linear classifier trained on representations learned by CVRL achieves 64.1\% top-1 accuracy with a 3D-ResNet50 backbone, outperforming ImageNet supervised pre-training by 9.4\% and SimCLR unsupervised pre-training by 16.1\% using the same inflated 3D-ResNet50. The performance of CVRL can be further improved to 68.2\% with a larger 3D-ResNet50 (4$\times$) backbone, significantly closing the gap between unsupervised and supervised video representation learning.