 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaTe: Visually-Grounded Planning with Transformers in Procedural Tasks
Sep 10, 2021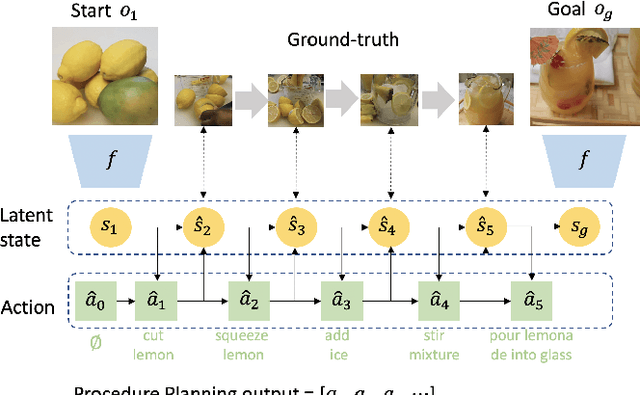
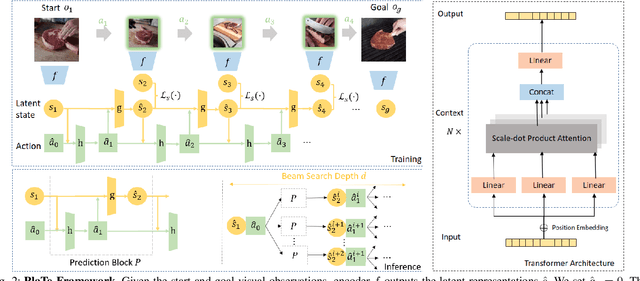
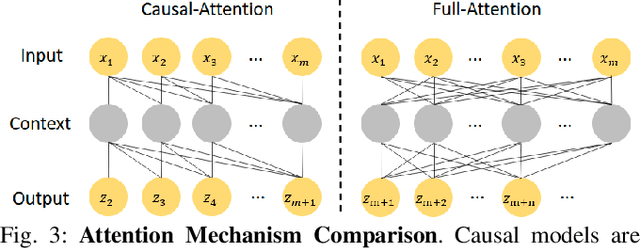

In this work, we study the problem of how to leverage instructional videos to facilitate the understanding of human decision-making processes, focusing on training a model with the ability to plan a goal-directed procedure from real-world videos. Learning structured and plannable state and action spaces directly from unstructured videos is the key technical challenge of our task. There are two problems: first, the appearance gap between the training and validation datasets could be large for unstructured videos; second, these gaps lead to decision errors that compound over the steps. We address these limitations with Planning Transformer (PlaTe), which has the advantage of circumventing the compounding prediction errors that occur with single-step models during long model-based rollouts. Our method simultaneously learns the latent state and action information of assigned tasks and the representations of the decision-making process from human demonstrations. Experiments conducted on real-world instructional videos and an interactive environment show that our method can achieve a better performance in reaching the indicated goal than previous algorithms. We also validated the possibility of applying procedural tasks on a UR-5 platform.
Interpreting Generative Adversarial Networks for Interactive Image Generation
Aug 10, 2021
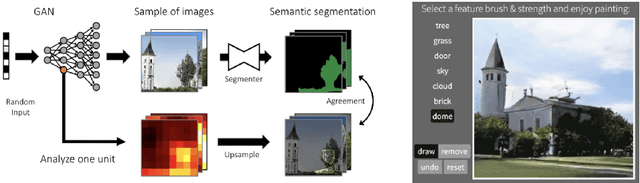
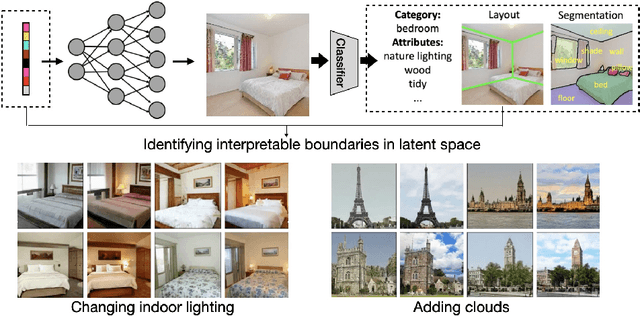

Great progress has been made by the advances in Generative Adversarial Networks (GANs) for image generation. However, there lacks enough understanding on how a realistic image can be generated by the deep representations of GANs from a random vector. This chapter will give a summary of recent works on interpreting deep generative models. We will see how the human-understandable concepts that emerge in the learned representation can be identified and used for interactive image generation and editing.
Safe Exploration by Solving Early Terminated MDP
Jul 09, 2021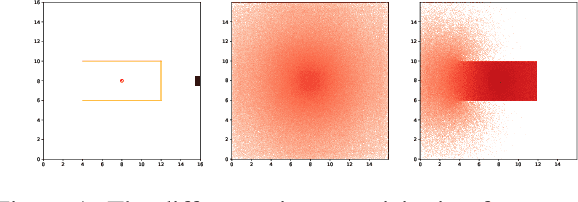


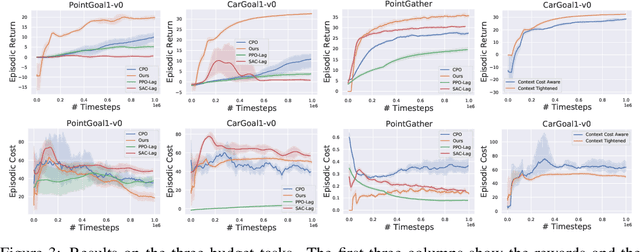
Safe exploration is crucial for the real-world application of reinforcement learning (RL). Previous works consider the safe exploration problem as Constrained Markov Decision Process (CMDP), where the policies are being optimized under constraints. However, when encountering any potential dangers, human tends to stop immediately and rarely learns to behave safely in danger. Motivated by human learning, we introduce a new approach to address safe RL problems under the framework of Early Terminated MDP (ET-MDP). We first define the ET-MDP as an unconstrained MDP with the same optimal value function as its corresponding CMDP. An off-policy algorithm based on context models is then proposed to solve the ET-MDP, which thereby solves the corresponding CMDP with better asymptotic performance and improved learning efficiency. Experiments on various CMDP tasks show a substantial improvement over previous methods that directly solve CMDP.
Data-Efficient Instance Generation from Instance Discrimination
Jun 08, 2021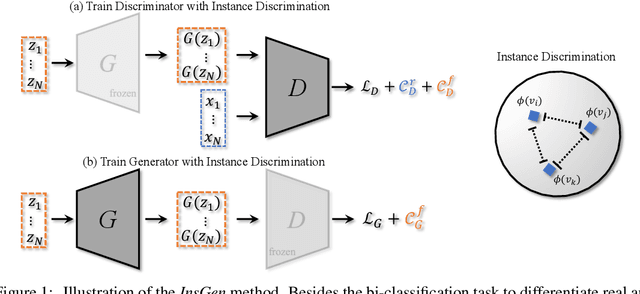
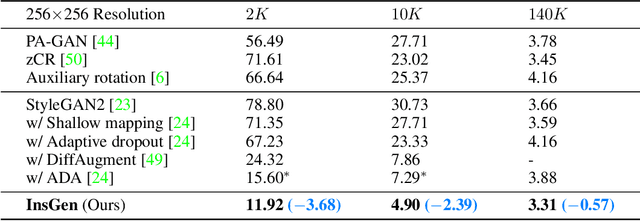
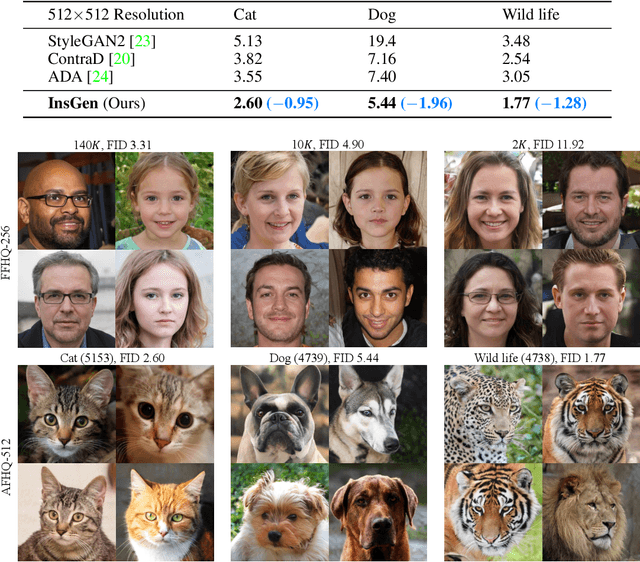
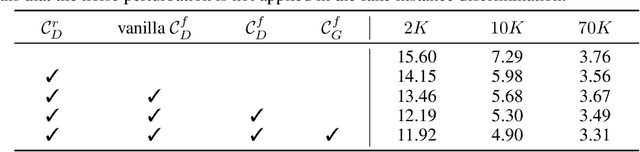
Generative Adversarial Networks (GANs) have significantly advanced image synthesis, however, the synthesis quality drops significantly given a limited amount of training data. To improve the data efficiency of GAN training, prior work typically employs data augmentation to mitigate the overfitting of the discriminator yet still learn the discriminator with a bi-classification (i.e., real vs. fake) task. In this work, we propose a data-efficient Instance Generation (InsGen) method based on instance discrimination. Concretely, besides differentiating the real domain from the fake domain, the discriminator is required to distinguish every individual image, no matter it comes from the training set or from the generator. In this way, the discriminator can benefit from the infinite synthesized samples for training, alleviating the overfitting problem caused by insufficient training data. A noise perturbation strategy is further introduced to improve its discriminative power. Meanwhile, the learned instance discrimination capability from the discriminator is in turn exploited to encourage the generator for diverse generation. Extensive experiments demonstrate the effectiveness of our method on a variety of datasets and training settings. Noticeably, on the setting of 2K training images from the FFHQ dataset, we outperform the state-of-the-art approach with 23.5% FID improvement.
TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization
Mar 27, 2021
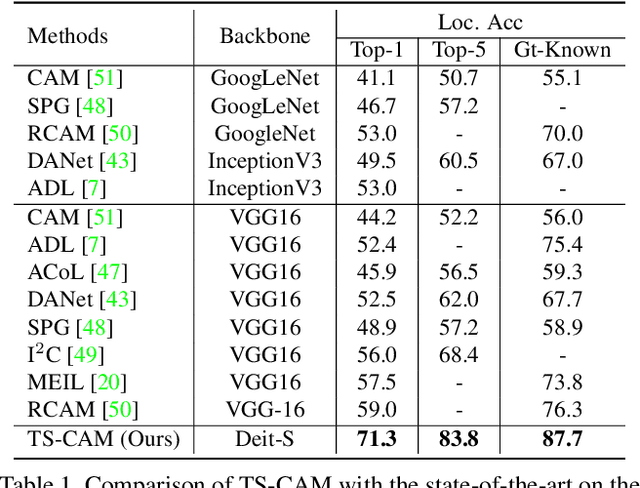
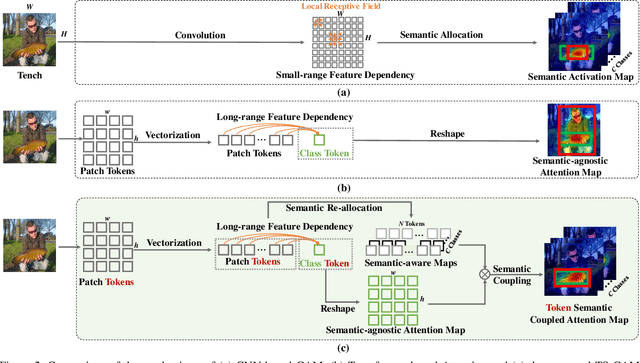
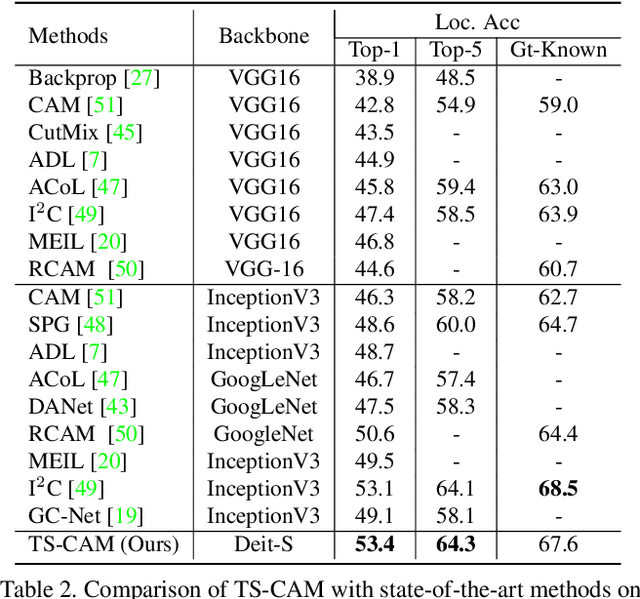
Weakly supervised object localization (WSOL) is a challenging problem when given image category labels but requires to learn object localization models. Optimizing a convolutional neural network (CNN) for classification tends to activate local discriminative regions while ignoring complete object extent, causing the partial activation issue. In this paper, we argue that partial activation is caused by the intrinsic characteristics of CNN, where the convolution operations produce local receptive fields and experience difficulty to capture long-range feature dependency among pixels. We introduce the token semantic coupled attention map (TS-CAM) to take full advantage of the self-attention mechanism in visual transformer for long-range dependency extraction. TS-CAM first splits an image into a sequence of patch tokens for spatial embedding, which produce attention maps of long-range visual dependency to avoid partial activation. TS-CAM then re-allocates category-related semantics for patch tokens, enabling each of them to be aware of object categories. TS-CAM finally couples the patch tokens with the semantic-agnostic attention map to achieve semantic-aware localization. Experiments on the ILSVRC/CUB-200-2011 datasets show that TS-CAM outperforms its CNN-CAM counterparts by 7.1%/27.1% for WSOL, achieving state-of-the-art performance.
Multimodal Motion Prediction with Stacked Transformers
Mar 24, 2021
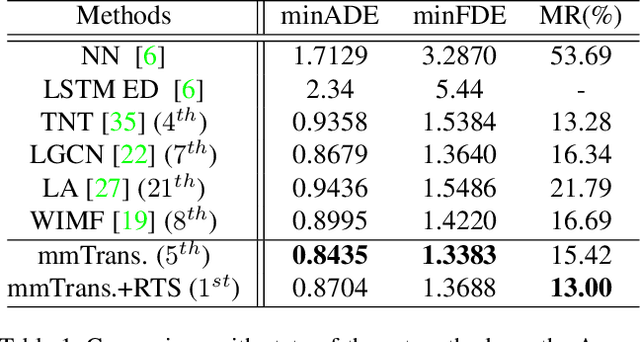
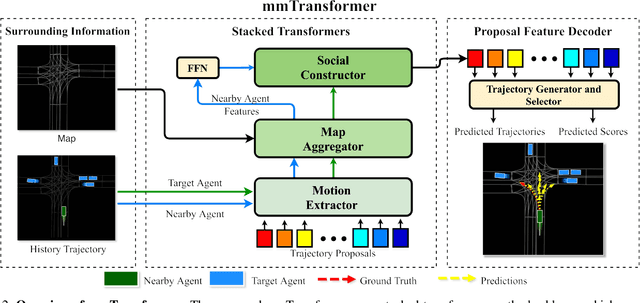
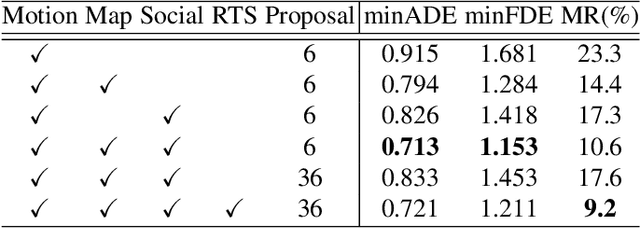
Predicting multiple plausible future trajectories of the nearby vehicles is crucial for the safety of autonomous driving. Recent motion prediction approaches attempt to achieve such multimodal motion prediction by implicitly regularizing the feature or explicitly generating multiple candidate proposals. However, it remains challenging since the latent features may concentrate on the most frequent mode of the data while the proposal-based methods depend largely on the prior knowledge to generate and select the proposals. In this work, we propose a novel transformer framework for multimodal motion prediction, termed as mmTransformer. A novel network architecture based on stacked transformers is designed to model the multimodality at feature level with a set of fixed independent proposals. A region-based training strategy is then developed to induce the multimodality of the generated proposals. Experiments on Argoverse dataset show that the proposed model achieves the state-of-the-art performance on motion prediction, substantially improving the diversity and the accuracy of the predicted trajectories. Demo video and code are available at https://decisionforce.github.io/mmTransformer.
Unsupervised Image Transformation Learning via Generative Adversarial Networks
Mar 13, 2021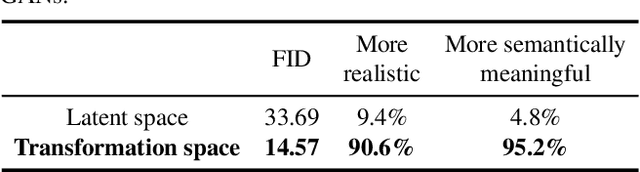
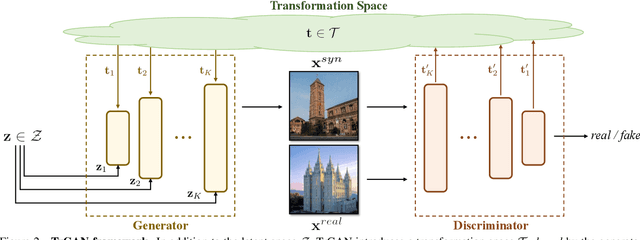
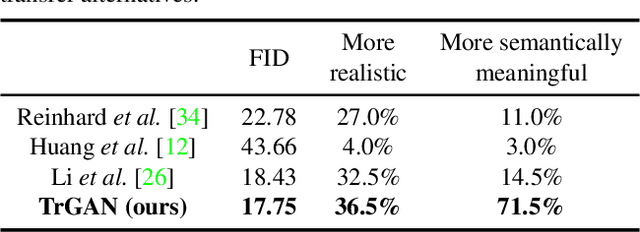

In this work, we study the image transformation problem by learning the underlying transformations from a collection of images using Generative Adversarial Networks (GANs). Specifically, we propose an unsupervised learning framework, termed as TrGAN, to project images onto a transformation space that is shared by the generator and the discriminator. Any two points in this projected space define a transformation that can guide the image generation process, leading to continuous semantic change. By projecting a pair of images onto the transformation space, we are able to adequately extract the semantic variation between them and further apply the extracted semantic to facilitating image editing, including not only transferring image styles (e.g., changing day to night) but also manipulating image contents (e.g., adding clouds in the sky). Code and models are available at https://genforce.github.io/trgan.
Deep Learning for Scene Classification: A Survey
Feb 20, 2021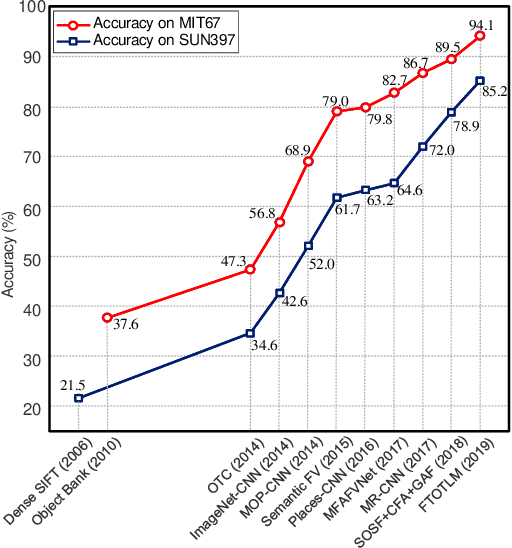
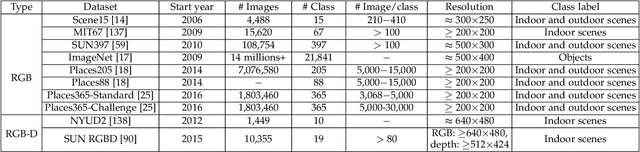

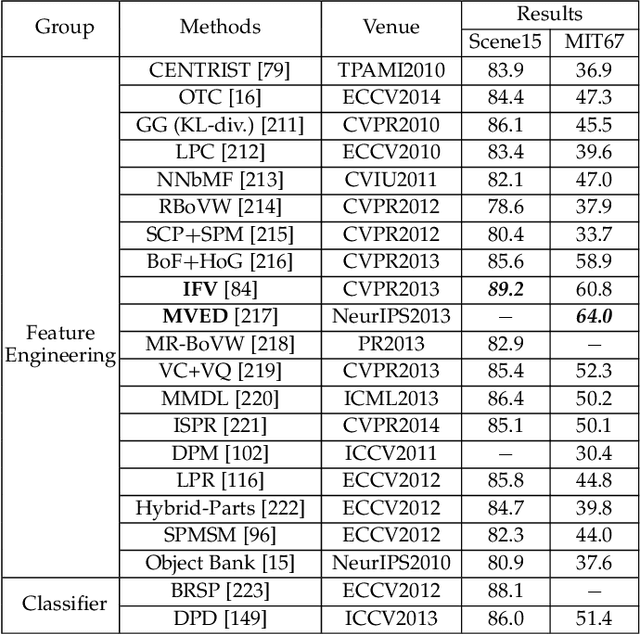
Scene classification, aiming at classifying a scene image to one of the predefined scene categories by comprehending the entire image, is a longstanding, fundamental and challenging problem in computer vision. The rise of large-scale datasets, which constitute the corresponding dense sampling of diverse real-world scenes, and the renaissance of deep learning techniques, which learn powerful feature representations directly from big raw data, have been bringing remarkable progress in the field of scene representation and classification. To help researchers master needed advances in this field, the goal of this paper is to provide a comprehensive survey of recent achievements in scene classification using deep learning. More than 200 major publications are included in this survey covering different aspects of scene classification, including challenges, benchmark datasets, taxonomy, and quantitative performance comparisons of the reviewed methods. In retrospect of what has been achieved so far, this paper is also concluded with a list of promising research opportunities.
Instance Localization for Self-supervised Detection Pretraining
Feb 16, 2021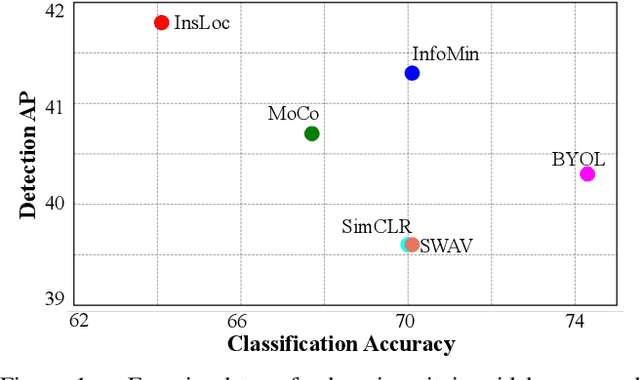
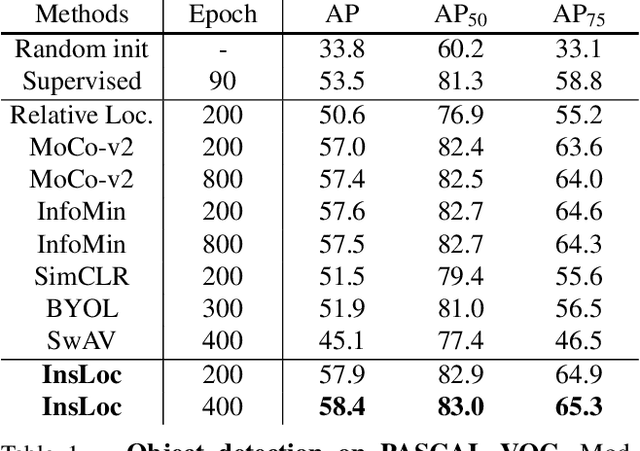
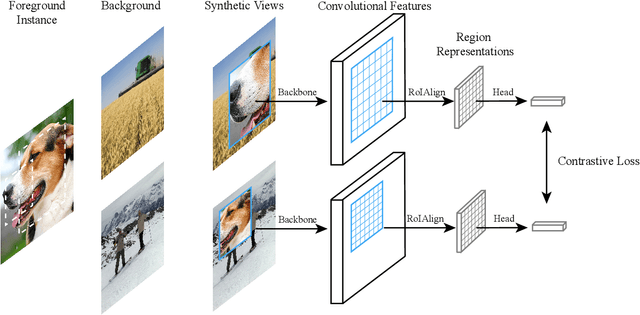
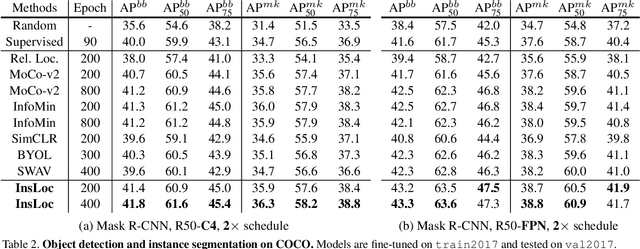
Prior research on self-supervised learning has led to considerable progress on image classification, but often with degraded transfer performance on object detection. The objective of this paper is to advance self-supervised pretrained models specifically for object detection. Based on the inherent difference between classification and detection, we propose a new self-supervised pretext task, called instance localization. Image instances are pasted at various locations and scales onto background images. The pretext task is to predict the instance category given the composited images as well as the foreground bounding boxes. We show that integration of bounding boxes into pretraining promotes better task alignment and architecture alignment for transfer learning. In addition, we propose an augmentation method on the bounding boxes to further enhance the feature alignment. As a result, our model becomes weaker at Imagenet semantic classification but stronger at image patch localization, with an overall stronger pretrained model for object detection. Experimental results demonstrate that our approach yields state-of-the-art transfer learning results for object detection on PASCAL VOC and MSCOCO.
GAN Inversion: A Survey
Jan 14, 2021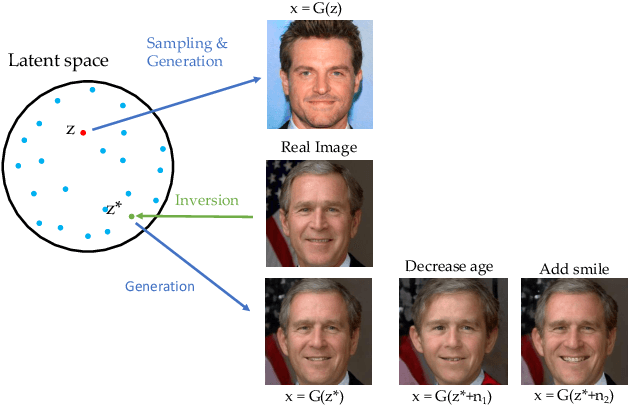
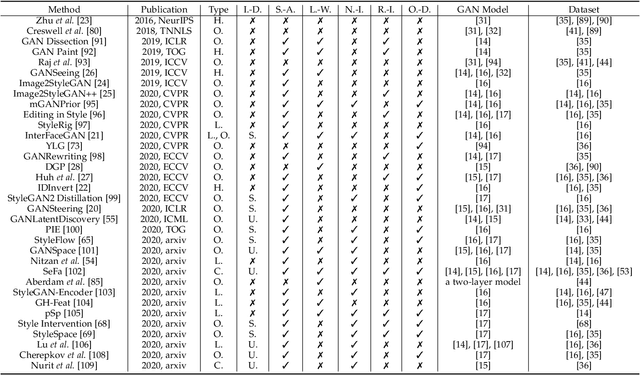
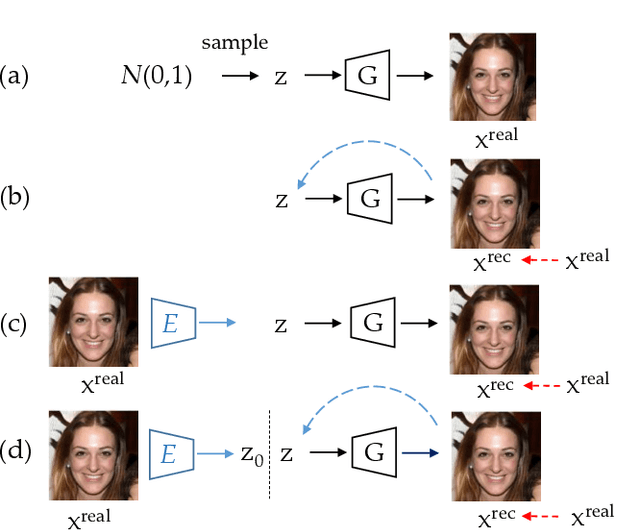
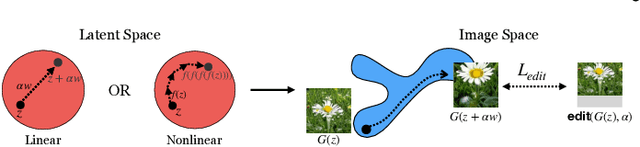
GAN inversion aims to invert a given image back into the latent space of a pretrained GAN model, for the image to be faithfully reconstructed from the inverted code by the generator. As an emerging technique to bridge the real and fake image domains, GAN inversion plays an essential role in enabling the pretrained GAN models such as StyleGAN and BigGAN to be used for real image editing applications. Meanwhile, GAN inversion also provides insights on the interpretation of GAN's latent space and how the realistic images can be generated. In this paper, we provide an overview of GAN inversion with a focus on its recent algorithms and applications. We cover important techniques of GAN inversion and their applications to image restoration and image manipulation. We further elaborate on some trends and challenges for future directions.