 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter-Level Perturbations Disrupt LLM Watermarks
Sep 11, 2025Large Language Model (LLM) watermarking embeds detectable signals into generated text for copyright protection, misuse prevention, and content detection. While prior studies evaluate robustness using watermark removal attacks, these methods are often suboptimal, creating the misconception that effective removal requires large perturbations or powerful adversaries. To bridge the gap, we first formalize the system model for LLM watermark, and characterize two realistic threat models constrained on limited access to the watermark detector. We then analyze how different types of perturbation vary in their attack range, i.e., the number of tokens they can affect with a single edit. We observe that character-level perturbations (e.g., typos, swaps, deletions, homoglyphs) can influence multiple tokens simultaneously by disrupting the tokenization process. We demonstrate that character-level perturbations are significantly more effective for watermark removal under the most restrictive threat model. We further propose guided removal attacks based on the Genetic Algorithm (GA) that uses a reference detector for optimization. Under a practical threat model with limited black-box queries to the watermark detector, our method demonstrates strong removal performance. Experiments confirm the superiority of character-level perturbations and the effectiveness of the GA in removing watermarks under realistic constraints. Additionally, we argue there is an adversarial dilemma when considering potential defenses: any fixed defense can be bypassed by a suitable perturbation strategy. Motivated by this principle, we propose an adaptive compound character-level attack. Experimental results show that this approach can effectively defeat the defenses. Our findings highlight significant vulnerabilities in existing LLM watermark schemes and underline the urgency for the development of new robust mechanisms.
An Iterative LLM Framework for SIBT utilizing RAG-based Adaptive Weight Optimization
Sep 10, 2025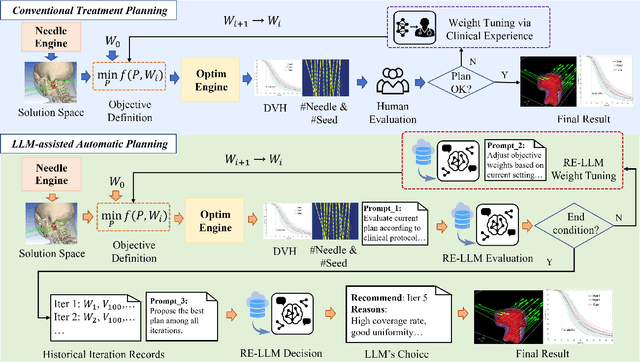
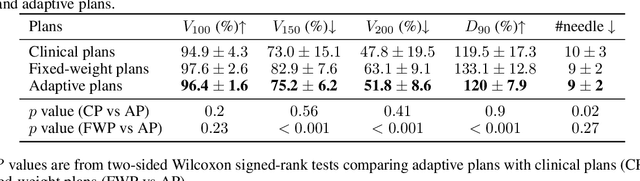

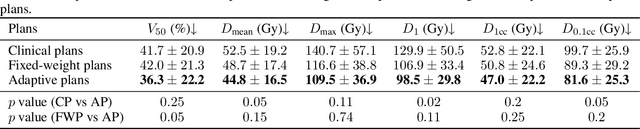
Seed implant brachytherapy (SIBT) is an effective cancer treatment modality; however, clinical planning often relies on manual adjustment of objective function weights, leading to inefficiencies and suboptimal results. This study proposes an adaptive weight optimization framework for SIBT planning, driven by large language models (LLMs). A locally deployed DeepSeek-R1 LLM is integrated with an automatic planning algorithm in an iterative loop. Starting with fixed weights, the LLM evaluates plan quality and recommends new weights in the next iteration. This process continues until convergence criteria are met, after which the LLM conducts a comprehensive evaluation to identify the optimal plan. A clinical knowledge base, constructed and queried via retrieval-augmented generation (RAG), enhances the model's domain-specific reasoning. The proposed method was validated on 23 patient cases, showing that the LLM-assisted approach produces plans that are comparable to or exceeding clinically approved and fixed-weight plans, in terms of dose homogeneity for the clinical target volume (CTV) and sparing of organs at risk (OARs). The study demonstrates the potential use of LLMs in SIBT planning automation.
EndoUFM: Utilizing Foundation Models for Monocular depth estimation of endoscopic images
Aug 25, 2025Depth estimation is a foundational component for 3D reconstruction in minimally invasive endoscopic surgeries. However, existing monocular depth estimation techniques often exhibit limited performance to the varying illumination and complex textures of the surgical environment. While powerful visual foundation models offer a promising solution, their training on natural images leads to significant domain adaptability limitations and semantic perception deficiencies when applied to endoscopy. In this study, we introduce EndoUFM, an unsupervised monocular depth estimation framework that innovatively integrating dual foundation models for surgical scenes, which enhance the depth estimation performance by leveraging the powerful pre-learned priors. The framework features a novel adaptive fine-tuning strategy that incorporates Random Vector Low-Rank Adaptation (RVLoRA) to enhance model adaptability, and a Residual block based on Depthwise Separable Convolution (Res-DSC) to improve the capture of fine-grained local features. Furthermore, we design a mask-guided smoothness loss to enforce depth consistency within anatomical tissue structures. Extensive experiments on the SCARED, Hamlyn, SERV-CT, and EndoNeRF datasets confirm that our method achieves state-of-the-art performance while maintaining an efficient model size. This work contributes to augmenting surgeons' spatial perception during minimally invasive procedures, thereby enhancing surgical precision and safety, with crucial implications for augmented reality and navigation systems.
Hierarchical knowledge guided fault intensity diagnosis of complex industrial systems
Aug 17, 2025



Fault intensity diagnosis (FID) plays a pivotal role in monitoring and maintaining mechanical devices within complex industrial systems. As current FID methods are based on chain of thought without considering dependencies among target classes. To capture and explore dependencies, we propose a hierarchical knowledge guided fault intensity diagnosis framework (HKG) inspired by the tree of thought, which is amenable to any representation learning methods. The HKG uses graph convolutional networks to map the hierarchical topological graph of class representations into a set of interdependent global hierarchical classifiers, where each node is denoted by word embeddings of a class. These global hierarchical classifiers are applied to learned deep features extracted by representation learning, allowing the entire model to be end-to-end learnable. In addition, we develop a re-weighted hierarchical knowledge correlation matrix (Re-HKCM) scheme by embedding inter-class hierarchical knowledge into a data-driven statistical correlation matrix (SCM) which effectively guides the information sharing of nodes in graphical convolutional neural networks and avoids over-smoothing issues. The Re-HKCM is derived from the SCM through a series of mathematical transformations. Extensive experiments are performed on four real-world datasets from different industrial domains (three cavitation datasets from SAMSON AG and one existing publicly) for FID, all showing superior results and outperform recent state-of-the-art FID methods.
* 12 pages
DEAL: Disentangling Transformer Head Activations for LLM Steering
Jun 10, 2025Inference-time steering aims to alter the response characteristics of large language models (LLMs) without modifying their underlying parameters. A critical step in this process is the identification of internal modules within LLMs that are associated with the target behavior. However, current approaches to module selection often depend on superficial cues or ad-hoc heuristics, which can result in suboptimal or unintended outcomes. In this work, we propose a principled causal-attribution framework for identifying behavior-relevant attention heads in transformers. For each head, we train a vector-quantized autoencoder (VQ-AE) on its attention activations, partitioning the latent space into behavior-relevant and behavior-irrelevant subspaces, each quantized with a shared learnable codebook. We assess the behavioral relevance of each head by quantifying the separability of VQ-AE encodings for behavior-aligned versus behavior-violating responses using a binary classification metric. This yields a behavioral relevance score that reflects each head discriminative capacity with respect to the target behavior, guiding both selection and importance weighting. Experiments on seven LLMs from two model families and five behavioral steering datasets demonstrate that our method enables more accurate inference-time interventions, achieving superior performance on the truthfulness-steering task. Furthermore, the heads selected by our approach exhibit strong zero-shot generalization in cross-domain truthfulness-steering scenarios.
MAGREF: Masked Guidance for Any-Reference Video Generation
May 29, 2025Video generation has made substantial strides with the emergence of deep generative models, especially diffusion-based approaches. However, video generation based on multiple reference subjects still faces significant challenges in maintaining multi-subject consistency and ensuring high generation quality. In this paper, we propose MAGREF, a unified framework for any-reference video generation that introduces masked guidance to enable coherent multi-subject video synthesis conditioned on diverse reference images and a textual prompt. Specifically, we propose (1) a region-aware dynamic masking mechanism that enables a single model to flexibly handle various subject inference, including humans, objects, and backgrounds, without architectural changes, and (2) a pixel-wise channel concatenation mechanism that operates on the channel dimension to better preserve appearance features. Our model delivers state-of-the-art video generation quality, generalizing from single-subject training to complex multi-subject scenarios with coherent synthesis and precise control over individual subjects, outperforming existing open-source and commercial baselines. To facilitate evaluation, we also introduce a comprehensive multi-subject video benchmark. Extensive experiments demonstrate the effectiveness of our approach, paving the way for scalable, controllable, and high-fidelity multi-subject video synthesis. Code and model can be found at: https://github.com/MAGREF-Video/MAGREF
MSEarth: A Benchmark for Multimodal Scientific Comprehension of Earth Science
May 27, 2025The rapid advancement of multimodal large language models (MLLMs) has unlocked new opportunities to tackle complex scientific challenges. Despite this progress, their application in addressing earth science problems, especially at the graduate level, remains underexplored. A significant barrier is the absence of benchmarks that capture the depth and contextual complexity of geoscientific reasoning. Current benchmarks often rely on synthetic datasets or simplistic figure-caption pairs, which do not adequately reflect the intricate reasoning and domain-specific insights required for real-world scientific applications. To address these gaps, we introduce MSEarth, a multimodal scientific benchmark curated from high-quality, open-access scientific publications. MSEarth encompasses the five major spheres of Earth science: atmosphere, cryosphere, hydrosphere, lithosphere, and biosphere, featuring over 7K figures with refined captions. These captions are crafted from the original figure captions and enriched with discussions and reasoning from the papers, ensuring the benchmark captures the nuanced reasoning and knowledge-intensive content essential for advanced scientific tasks. MSEarth supports a variety of tasks, including scientific figure captioning, multiple choice questions, and open-ended reasoning challenges. By bridging the gap in graduate-level benchmarks, MSEarth provides a scalable and high-fidelity resource to enhance the development and evaluation of MLLMs in scientific reasoning. The benchmark is publicly available to foster further research and innovation in this field. Resources related to this benchmark can be found at https://huggingface.co/MSEarth and https://github.com/xiangyu-mm/MSEarth.
SurveillanceVQA-589K: A Benchmark for Comprehensive Surveillance Video-Language Understanding with Large Models
May 19, 2025Understanding surveillance video content remains a critical yet underexplored challenge in vision-language research, particularly due to its real-world complexity, irregular event dynamics, and safety-critical implications. In this work, we introduce SurveillanceVQA-589K, the largest open-ended video question answering benchmark tailored to the surveillance domain. The dataset comprises 589,380 QA pairs spanning 12 cognitively diverse question types, including temporal reasoning, causal inference, spatial understanding, and anomaly interpretation, across both normal and abnormal video scenarios. To construct the benchmark at scale, we design a hybrid annotation pipeline that combines temporally aligned human-written captions with Large Vision-Language Model-assisted QA generation using prompt-based techniques. We also propose a multi-dimensional evaluation protocol to assess contextual, temporal, and causal comprehension. We evaluate eight LVLMs under this framework, revealing significant performance gaps, especially in causal and anomaly-related tasks, underscoring the limitations of current models in real-world surveillance contexts. Our benchmark provides a practical and comprehensive resource for advancing video-language understanding in safety-critical applications such as intelligent monitoring, incident analysis, and autonomous decision-making.
LEAM: A Prompt-only Large Language Model-enabled Antenna Modeling Method
Apr 25, 2025Antenna modeling is a time-consuming and complex process, decreasing the speed of antenna analysis and design. In this paper, a large language model (LLM)- enabled antenna modeling method, called LEAM, is presented to address this challenge. LEAM enables automatic antenna model generation based on language descriptions via prompt input, images, descriptions from academic papers, patents, and technical reports (either one or multiple). The effectiveness of LEAM is demonstrated by three examples: a Vivaldi antenna generated from a complete user description, a slotted patch antenna generated from an incomplete user description and the operating frequency, and a monopole slotted antenna generated from images and descriptions scanned from the literature. For all the examples, correct antenna models are generated in a few minutes. The code can be accessed via https://github.com/TaoWu974/LEAM.
TextArena
Apr 15, 2025



TextArena is an open-source collection of competitive text-based games for training and evaluation of agentic behavior in Large Language Models (LLMs). It spans 57+ unique environments (including single-player, two-player, and multi-player setups) and allows for easy evaluation of model capabilities via an online-play system (against humans and other submitted models) with real-time TrueSkill scores. Traditional benchmarks rarely assess dynamic social skills such as negotiation, theory of mind, and deception, creating a gap that TextArena addresses. Designed with research, community and extensibility in mind, TextArena emphasizes ease of adding new games, adapting the framework, testing models, playing against the models, and training models. Detailed documentation of environments, games, leaderboard, and examples are available on https://github.com/LeonGuertler/TextArena and https://www.textarena.ai/.