 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Iterative LLM Framework for SIBT utilizing RAG-based Adaptive Weight Optimization
Sep 10, 2025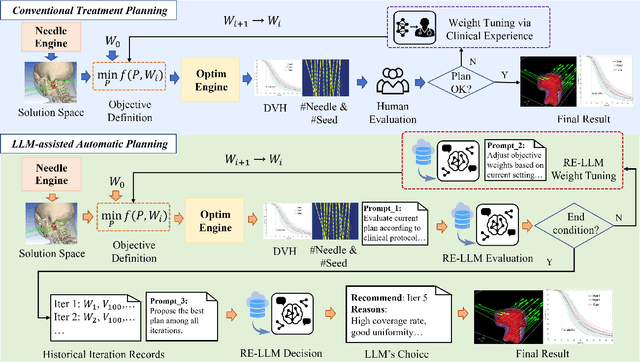
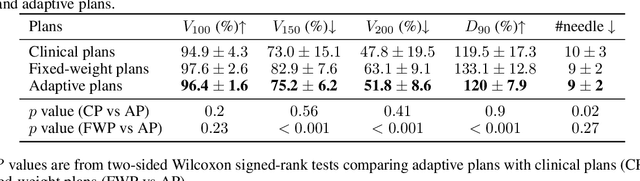

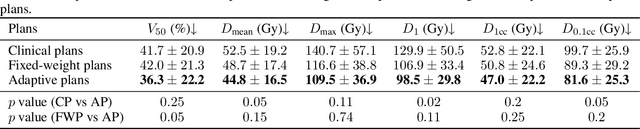
Seed implant brachytherapy (SIBT) is an effective cancer treatment modality; however, clinical planning often relies on manual adjustment of objective function weights, leading to inefficiencies and suboptimal results. This study proposes an adaptive weight optimization framework for SIBT planning, driven by large language models (LLMs). A locally deployed DeepSeek-R1 LLM is integrated with an automatic planning algorithm in an iterative loop. Starting with fixed weights, the LLM evaluates plan quality and recommends new weights in the next iteration. This process continues until convergence criteria are met, after which the LLM conducts a comprehensive evaluation to identify the optimal plan. A clinical knowledge base, constructed and queried via retrieval-augmented generation (RAG), enhances the model's domain-specific reasoning. The proposed method was validated on 23 patient cases, showing that the LLM-assisted approach produces plans that are comparable to or exceeding clinically approved and fixed-weight plans, in terms of dose homogeneity for the clinical target volume (CTV) and sparing of organs at risk (OARs). The study demonstrates the potential use of LLMs in SIBT planning automation.
Accelerate Three-Dimensional Generative Adversarial Networks Using Fast Algorithm
Oct 18, 2022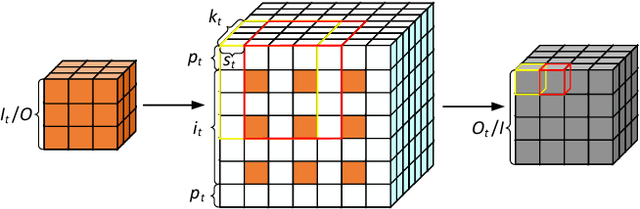
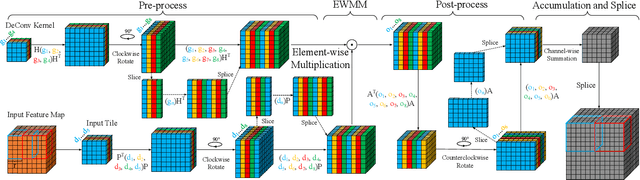
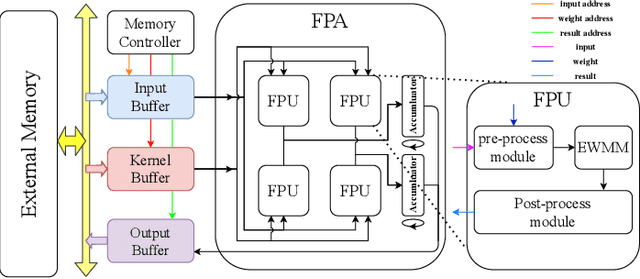
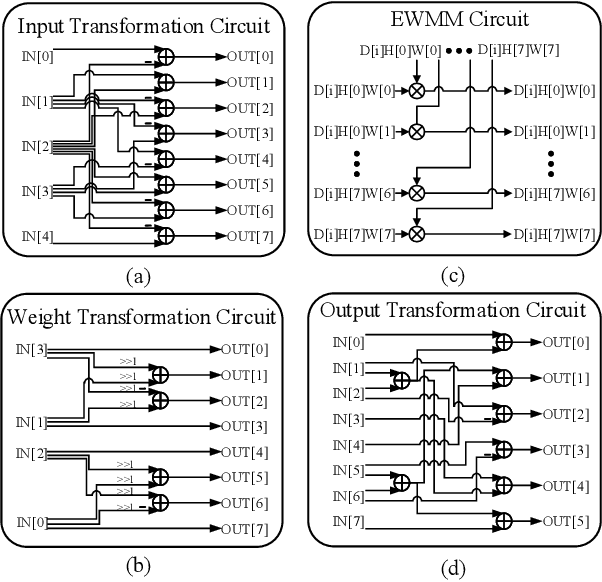
Three-dimensional generative adversarial networks (3D-GAN) have attracted widespread attention in three-dimension (3D) visual tasks. 3D deconvolution (DeConv), as an important computation of 3D-GAN, significantly increases computational complexity compared with 2D DeConv. 3D DeConv has become a bottleneck for the acceleration of 3D-GAN. Previous accelerators suffer from several problems, such as large memory requirements and resource underutilization. To handle the above issues, a fast algorithm for 3D DeConv (F3DC) is proposed in this paper. F3DC applies a fast algorithm to reduce the number of multiplications and achieves a significant algorithmic strength reduction. Besides, F3DC removes the extra memory requirement for overlapped partial sums and avoids computational imbalance to fully utilize resources. Moreover, we design an F3DC-based hardware architecture, which consists of four fast processing units (FPUs). Each FPU includes a pre-process module, a EWMM module and a post-process module for F3DC transformation. By implementing our design on the Xilinx VC709 platform for 3D-GAN, we achieve a throughput up to 1700 GOPS and 4$\times$ computational efficiency improvement compared with prior works.