 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Sample Selection by Cutting Mislabeled Easy Examples
Feb 12, 2025Sample selection is a prevalent approach in learning with noisy labels, aiming to identify confident samples for training. Although existing sample selection methods have achieved decent results by reducing the noise rate of the selected subset, they often overlook that not all mislabeled examples harm the model's performance equally. In this paper, we demonstrate that mislabeled examples correctly predicted by the model early in the training process are particularly harmful to model performance. We refer to these examples as Mislabeled Easy Examples (MEEs). To address this, we propose Early Cutting, which introduces a recalibration step that employs the model's later training state to re-select the confident subset identified early in training, thereby avoiding misleading confidence from early learning and effectively filtering out MEEs. Experiments on the CIFAR, WebVision, and full ImageNet-1k datasets demonstrate that our method effectively improves sample selection and model performance by reducing MEEs.
Instance-dependent Early Stopping
Feb 11, 2025In machine learning practice, early stopping has been widely used to regularize models and can save computational costs by halting the training process when the model's performance on a validation set stops improving. However, conventional early stopping applies the same stopping criterion to all instances without considering their individual learning statuses, which leads to redundant computations on instances that are already well-learned. To further improve the efficiency, we propose an Instance-dependent Early Stopping (IES) method that adapts the early stopping mechanism from the entire training set to the instance level, based on the core principle that once the model has mastered an instance, the training on it should stop. IES considers an instance as mastered if the second-order differences of its loss value remain within a small range around zero. This offers a more consistent measure of an instance's learning status compared with directly using the loss value, and thus allows for a unified threshold to determine when an instance can be excluded from further backpropagation. We show that excluding mastered instances from backpropagation can increase the gradient norms, thereby accelerating the decrease of the training loss and speeding up the training process. Extensive experiments on benchmarks demonstrate that IES method can reduce backpropagation instances by 10%-50% while maintaining or even slightly improving the test accuracy and transfer learning performance of a model.
Image-based Multimodal Models as Intruders: Transferable Multimodal Attacks on Video-based MLLMs
Jan 02, 2025



Video-based multimodal large language models (V-MLLMs) have shown vulnerability to adversarial examples in video-text multimodal tasks. However, the transferability of adversarial videos to unseen models--a common and practical real world scenario--remains unexplored. In this paper, we pioneer an investigation into the transferability of adversarial video samples across V-MLLMs. We find that existing adversarial attack methods face significant limitations when applied in black-box settings for V-MLLMs, which we attribute to the following shortcomings: (1) lacking generalization in perturbing video features, (2) focusing only on sparse key-frames, and (3) failing to integrate multimodal information. To address these limitations and deepen the understanding of V-MLLM vulnerabilities in black-box scenarios, we introduce the Image-to-Video MLLM (I2V-MLLM) attack. In I2V-MLLM, we utilize an image-based multimodal model (IMM) as a surrogate model to craft adversarial video samples. Multimodal interactions and temporal information are integrated to disrupt video representations within the latent space, improving adversarial transferability. In addition, a perturbation propagation technique is introduced to handle different unknown frame sampling strategies. Experimental results demonstrate that our method can generate adversarial examples that exhibit strong transferability across different V-MLLMs on multiple video-text multimodal tasks. Compared to white-box attacks on these models, our black-box attacks (using BLIP-2 as surrogate model) achieve competitive performance, with average attack success rates of 55.48% on MSVD-QA and 58.26% on MSRVTT-QA for VideoQA tasks, respectively. Our code will be released upon acceptance.
Eliciting Causal Abilities in Large Language Models for Reasoning Tasks
Dec 19, 2024



Prompt optimization automatically refines prompting expressions, unlocking the full potential of LLMs in downstream tasks. However, current prompt optimization methods are costly to train and lack sufficient interpretability. This paper proposes enhancing LLMs' reasoning performance by eliciting their causal inference ability from prompting instructions to correct answers. Specifically, we introduce the Self-Causal Instruction Enhancement (SCIE) method, which enables LLMs to generate high-quality, low-quantity observational data, then estimates the causal effect based on these data, and ultimately generates instructions with the optimized causal effect. In SCIE, the instructions are treated as the treatment, and textual features are used to process natural language, establishing causal relationships through treatments between instructions and downstream tasks. Additionally, we propose applying Object-Relational (OR) principles, where the uncovered causal relationships are treated as the inheritable class across task objects, ensuring low-cost reusability. Extensive experiments demonstrate that our method effectively generates instructions that enhance reasoning performance with reduced training cost of prompts, leveraging interpretable textual features to provide actionable insights.
Physics Reasoner: Knowledge-Augmented Reasoning for Solving Physics Problems with Large Language Models
Dec 18, 2024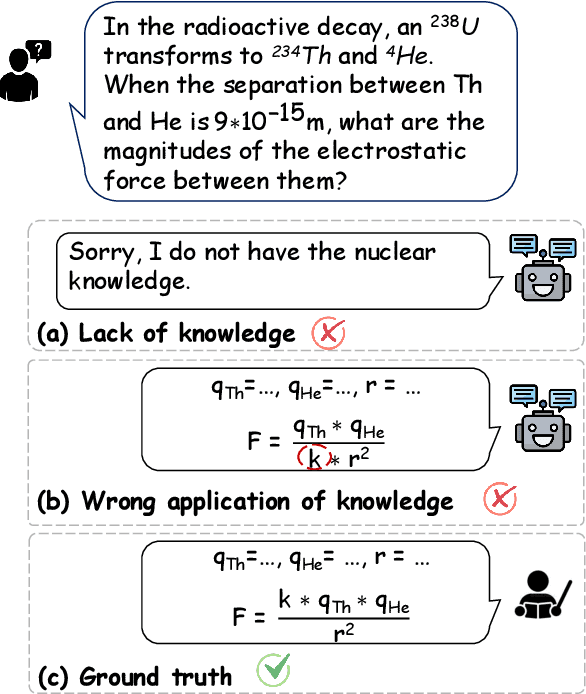
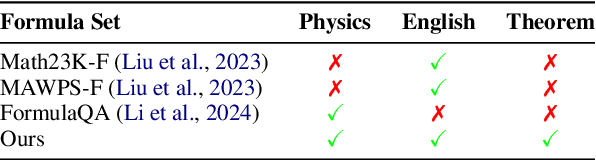
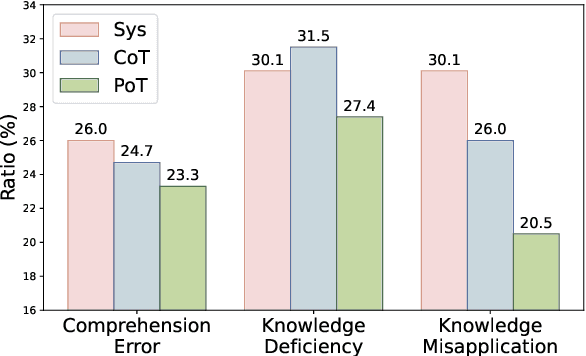
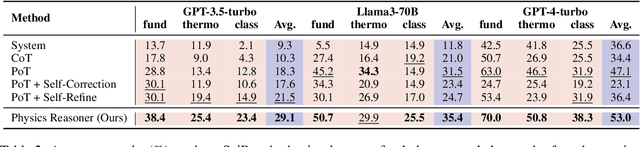
Physics problems constitute a significant aspect of reasoning, necessitating complicated reasoning ability and abundant physics knowledge. However, existing large language models (LLMs) frequently fail due to a lack of knowledge or incorrect knowledge application. To mitigate these issues, we propose Physics Reasoner, a knowledge-augmented framework to solve physics problems with LLMs. Specifically, the proposed framework constructs a comprehensive formula set to provide explicit physics knowledge and utilizes checklists containing detailed instructions to guide effective knowledge application. Namely, given a physics problem, Physics Reasoner solves it through three stages: problem analysis, formula retrieval, and guided reasoning. During the process, checklists are employed to enhance LLMs' self-improvement in the analysis and reasoning stages. Empirically, Physics Reasoner mitigates the issues of insufficient knowledge and incorrect application, achieving state-of-the-art performance on SciBench with an average accuracy improvement of 5.8%.
Adversarial Purification by Consistency-aware Latent Space Optimization on Data Manifolds
Dec 11, 2024



Deep neural networks (DNNs) are vulnerable to adversarial samples crafted by adding imperceptible perturbations to clean data, potentially leading to incorrect and dangerous predictions. Adversarial purification has been an effective means to improve DNNs robustness by removing these perturbations before feeding the data into the model. However, it faces significant challenges in preserving key structural and semantic information of data, as the imperceptible nature of adversarial perturbations makes it hard to avoid over-correcting, which can destroy important information and degrade model performance. In this paper, we break away from traditional adversarial purification methods by focusing on the clean data manifold. To this end, we reveal that samples generated by a well-trained generative model are close to clean ones but far from adversarial ones. Leveraging this insight, we propose Consistency Model-based Adversarial Purification (CMAP), which optimizes vectors within the latent space of a pre-trained consistency model to generate samples for restoring clean data. Specifically, 1) we propose a \textit{Perceptual consistency restoration} mechanism by minimizing the discrepancy between generated samples and input samples in both pixel and perceptual spaces. 2) To maintain the optimized latent vectors within the valid data manifold, we introduce a \textit{Latent distribution consistency constraint} strategy to align generated samples with the clean data distribution. 3) We also apply a \textit{Latent vector consistency prediction} scheme via an ensemble approach to enhance prediction reliability. CMAP fundamentally addresses adversarial perturbations at their source, providing a robust purification. Extensive experiments on CIFAR-10 and ImageNet-100 show that our CMAP significantly enhances robustness against strong adversarial attacks while preserving high natural accuracy.
Detecting Discrepancies Between AI-Generated and Natural Images Using Uncertainty
Dec 08, 2024



In this work, we propose a novel approach for detecting AI-generated images by leveraging predictive uncertainty to mitigate misuse and associated risks. The motivation arises from the fundamental assumption regarding the distributional discrepancy between natural and AI-generated images. The feasibility of distinguishing natural images from AI-generated ones is grounded in the distribution discrepancy between them. Predictive uncertainty offers an effective approach for capturing distribution shifts, thereby providing insights into detecting AI-generated images. Namely, as the distribution shift between training and testing data increases, model performance typically degrades, often accompanied by increased predictive uncertainty. Therefore, we propose to employ predictive uncertainty to reflect the discrepancies between AI-generated and natural images. In this context, the challenge lies in ensuring that the model has been trained over sufficient natural images to avoid the risk of determining the distribution of natural images as that of generated images. We propose to leverage large-scale pre-trained models to calculate the uncertainty as the score for detecting AI-generated images. This leads to a simple yet effective method for detecting AI-generated images using large-scale vision models: images that induce high uncertainty are identified as AI-generated. Comprehensive experiments across multiple benchmarks demonstrate the effectiveness of our method.
MotionLLaMA: A Unified Framework for Motion Synthesis and Comprehension
Nov 26, 2024



This paper introduces MotionLLaMA, a unified framework for motion synthesis and comprehension, along with a novel full-body motion tokenizer called the HoMi Tokenizer. MotionLLaMA is developed based on three core principles. First, it establishes a powerful unified representation space through the HoMi Tokenizer. Using a single codebook, the HoMi Tokenizer in MotionLLaMA achieves reconstruction accuracy comparable to residual vector quantization tokenizers utilizing six codebooks, outperforming all existing single-codebook tokenizers. Second, MotionLLaMA integrates a large language model to tackle various motion-related tasks. This integration bridges various modalities, facilitating both comprehensive and intricate motion synthesis and comprehension. Third, MotionLLaMA introduces the MotionHub dataset, currently the most extensive multimodal, multitask motion dataset, which enables fine-tuning of large language models. Extensive experimental results demonstrate that MotionLLaMA not only covers the widest range of motion-related tasks but also achieves state-of-the-art (SOTA) performance in motion completion, interaction dual-person text-to-motion, and all comprehension tasks while reaching performance comparable to SOTA in the remaining tasks. The code and MotionHub dataset are publicly available.
Model Inversion Attacks: A Survey of Approaches and Countermeasures
Nov 15, 2024The success of deep neural networks has driven numerous research studies and applications from Euclidean to non-Euclidean data. However, there are increasing concerns about privacy leakage, as these networks rely on processing private data. Recently, a new type of privacy attack, the model inversion attacks (MIAs), aims to extract sensitive features of private data for training by abusing access to a well-trained model. The effectiveness of MIAs has been demonstrated in various domains, including images, texts, and graphs. These attacks highlight the vulnerability of neural networks and raise awareness about the risk of privacy leakage within the research community. Despite the significance, there is a lack of systematic studies that provide a comprehensive overview and deeper insights into MIAs across different domains. This survey aims to summarize up-to-date MIA methods in both attacks and defenses, highlighting their contributions and limitations, underlying modeling principles, optimization challenges, and future directions. We hope this survey bridges the gap in the literature and facilitates future research in this critical area. Besides, we are maintaining a repository to keep track of relevant research at https://github.com/AndrewZhou924/Awesome-model-inversion-attack.
Golden Noise for Diffusion Models: A Learning Framework
Nov 14, 2024



Text-to-image diffusion model is a popular paradigm that synthesizes personalized images by providing a text prompt and a random Gaussian noise. While people observe that some noises are ``golden noises'' that can achieve better text-image alignment and higher human preference than others, we still lack a machine learning framework to obtain those golden noises. To learn golden noises for diffusion sampling, we mainly make three contributions in this paper. First, we identify a new concept termed the \textit{noise prompt}, which aims at turning a random Gaussian noise into a golden noise by adding a small desirable perturbation derived from the text prompt. Following the concept, we first formulate the \textit{noise prompt learning} framework that systematically learns ``prompted'' golden noise associated with a text prompt for diffusion models. Second, we design a noise prompt data collection pipeline and collect a large-scale \textit{noise prompt dataset}~(NPD) that contains 100k pairs of random noises and golden noises with the associated text prompts. With the prepared NPD as the training dataset, we trained a small \textit{noise prompt network}~(NPNet) that can directly learn to transform a random noise into a golden noise. The learned golden noise perturbation can be considered as a kind of prompt for noise, as it is rich in semantic information and tailored to the given text prompt. Third, our extensive experiments demonstrate the impressive effectiveness and generalization of NPNet on improving the quality of synthesized images across various diffusion models, including SDXL, DreamShaper-xl-v2-turbo, and Hunyuan-DiT. Moreover, NPNet is a small and efficient controller that acts as a plug-and-play module with very limited additional inference and computational costs, as it just provides a golden noise instead of a random noise without accessing the original pipeline.