 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIFEval-Audio: Benchmarking Instruction-Following Capability in Audio-based Large Language Models
May 22, 2025Large language models (LLMs) have demonstrated strong instruction-following capabilities in text-based tasks. However, this ability often deteriorates in multimodal models after alignment with non-text modalities such as images or audio. While several recent efforts have investigated instruction-following performance in text and vision-language models, instruction-following in audio-based large language models remains largely unexplored. To bridge this gap, we introduce IFEval-Audio, a novel evaluation dataset designed to assess the ability to follow instructions in an audio LLM. IFEval-Audio contains 280 audio-instruction-answer triples across six diverse dimensions: Content, Capitalization, Symbol, List Structure, Length, and Format. Each example pairs an audio input with a text instruction, requiring the model to generate an output that follows a specified structure. We benchmark state-of-the-art audio LLMs on their ability to follow audio-involved instructions. The dataset is released publicly to support future research in this emerging area.
Towards Spoken Mathematical Reasoning: Benchmarking Speech-based Models over Multi-faceted Math Problems
May 21, 2025Recent advances in large language models (LLMs) and multimodal LLMs (MLLMs) have led to strong reasoning ability across a wide range of tasks. However, their ability to perform mathematical reasoning from spoken input remains underexplored. Prior studies on speech modality have mostly focused on factual speech understanding or simple audio reasoning tasks, providing limited insight into logical step-by-step reasoning, such as that required for mathematical problem solving. To address this gap, we introduce Spoken Math Question Answering (Spoken-MQA), a new benchmark designed to evaluate the mathematical reasoning capabilities of speech-based models, including both cascade models (ASR + LLMs) and end-to-end speech LLMs. Spoken-MQA covers a diverse set of math problems, including pure arithmetic, single-step and multi-step contextual reasoning, and knowledge-oriented reasoning problems, all presented in unambiguous natural spoken language. Through extensive experiments, we find that: (1) while some speech LLMs perform competitively on contextual reasoning tasks involving basic arithmetic, they still struggle with direct arithmetic problems; (2) current LLMs exhibit a strong bias toward symbolic mathematical expressions written in LaTex and have difficulty interpreting verbalized mathematical expressions; and (3) mathematical knowledge reasoning abilities are significantly degraded in current speech LLMs.
Enhance Mobile Agents Thinking Process Via Iterative Preference Learning
May 18, 2025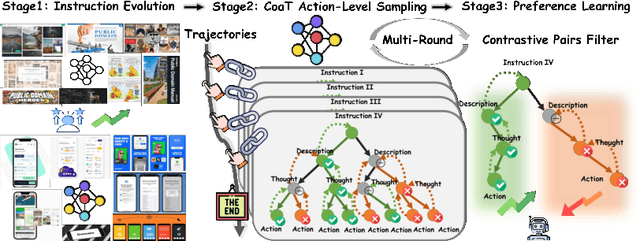
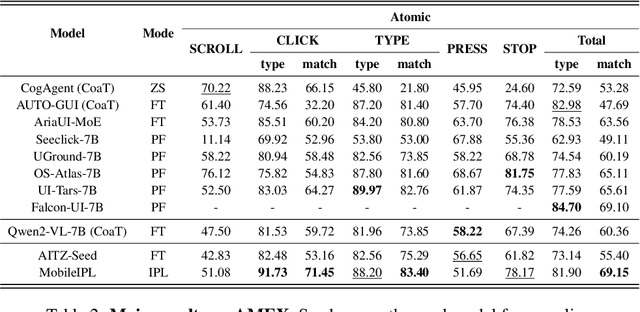
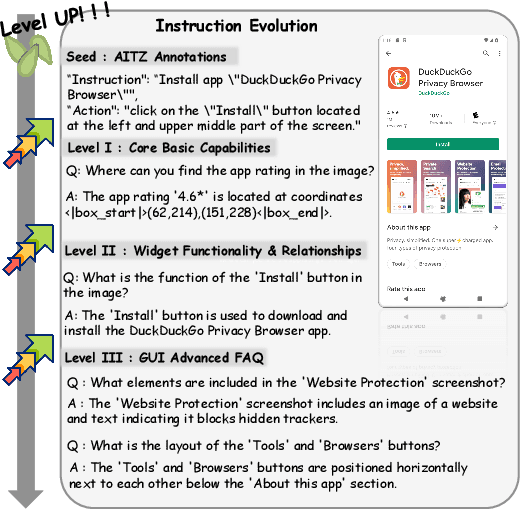
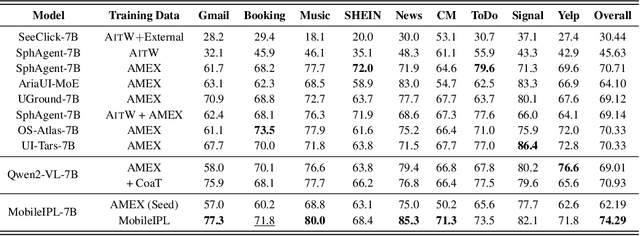
The Chain of Action-Planning Thoughts (CoaT) paradigm has been shown to improve the reasoning performance of VLM-based mobile agents in GUI tasks. However, the scarcity of diverse CoaT trajectories limits the expressiveness and generalization ability of such agents. While self-training is commonly employed to address data scarcity, existing approaches either overlook the correctness of intermediate reasoning steps or depend on expensive process-level annotations to construct process reward models (PRM). To address the above problems, we propose an Iterative Preference Learning (IPL) that constructs a CoaT-tree through interative sampling, scores leaf nodes using rule-based reward, and backpropagates feedback to derive Thinking-level Direct Preference Optimization (T-DPO) pairs. To prevent overfitting during warm-up supervised fine-tuning, we further introduce a three-stage instruction evolution, which leverages GPT-4o to generate diverse Q\&A pairs based on real mobile UI screenshots, enhancing both generality and layout understanding. Experiments on three standard Mobile GUI-agent benchmarks demonstrate that our agent MobileIPL outperforms strong baselines, including continual pretraining models such as OS-ATLAS and UI-TARS. It achieves state-of-the-art performance across three standard Mobile GUI-Agents benchmarks and shows strong generalization to out-of-domain scenarios.
Accelerating Diffusion-based Super-Resolution with Dynamic Time-Spatial Sampling
May 17, 2025



Diffusion models have gained attention for their success in modeling complex distributions, achieving impressive perceptual quality in SR tasks. However, existing diffusion-based SR methods often suffer from high computational costs, requiring numerous iterative steps for training and inference. Existing acceleration techniques, such as distillation and solver optimization, are generally task-agnostic and do not fully leverage the specific characteristics of low-level tasks like super-resolution (SR). In this study, we analyze the frequency- and spatial-domain properties of diffusion-based SR methods, revealing key insights into the temporal and spatial dependencies of high-frequency signal recovery. Specifically, high-frequency details benefit from concentrated optimization during early and late diffusion iterations, while spatially textured regions demand adaptive denoising strategies. Building on these observations, we propose the Time-Spatial-aware Sampling strategy (TSS) for the acceleration of Diffusion SR without any extra training cost. TSS combines Time Dynamic Sampling (TDS), which allocates more iterations to refining textures, and Spatial Dynamic Sampling (SDS), which dynamically adjusts strategies based on image content. Extensive evaluations across multiple benchmarks demonstrate that TSS achieves state-of-the-art (SOTA) performance with significantly fewer iterations, improving MUSIQ scores by 0.2 - 3.0 and outperforming the current acceleration methods with only half the number of steps.
Mobile-Bench-v2: A More Realistic and Comprehensive Benchmark for VLM-based Mobile Agents
May 17, 2025



VLM-based mobile agents are increasingly popular due to their capabilities to interact with smartphone GUIs and XML-structured texts and to complete daily tasks. However, existing online benchmarks struggle with obtaining stable reward signals due to dynamic environmental changes. Offline benchmarks evaluate the agents through single-path trajectories, which stands in contrast to the inherently multi-solution characteristics of GUI tasks. Additionally, both types of benchmarks fail to assess whether mobile agents can handle noise or engage in proactive interactions due to a lack of noisy apps or overly full instructions during the evaluation process. To address these limitations, we use a slot-based instruction generation method to construct a more realistic and comprehensive benchmark named Mobile-Bench-v2. Mobile-Bench-v2 includes a common task split, with offline multi-path evaluation to assess the agent's ability to obtain step rewards during task execution. It contains a noisy split based on pop-ups and ads apps, and a contaminated split named AITZ-Noise to formulate a real noisy environment. Furthermore, an ambiguous instruction split with preset Q\&A interactions is released to evaluate the agent's proactive interaction capabilities. We conduct evaluations on these splits using the single-agent framework AppAgent-v1, the multi-agent framework Mobile-Agent-v2, as well as other mobile agents such as UI-Tars and OS-Atlas. Code and data are available at https://huggingface.co/datasets/xwk123/MobileBench-v2.
FG-CLIP: Fine-Grained Visual and Textual Alignment
May 08, 2025Contrastive Language-Image Pre-training (CLIP) excels in multimodal tasks such as image-text retrieval and zero-shot classification but struggles with fine-grained understanding due to its focus on coarse-grained short captions. To address this, we propose Fine-Grained CLIP (FG-CLIP), which enhances fine-grained understanding through three key innovations. First, we leverage large multimodal models to generate 1.6 billion long caption-image pairs for capturing global-level semantic details. Second, a high-quality dataset is constructed with 12 million images and 40 million region-specific bounding boxes aligned with detailed captions to ensure precise, context-rich representations. Third, 10 million hard fine-grained negative samples are incorporated to improve the model's ability to distinguish subtle semantic differences. Corresponding training methods are meticulously designed for these data. Extensive experiments demonstrate that FG-CLIP outperforms the original CLIP and other state-of-the-art methods across various downstream tasks, including fine-grained understanding, open-vocabulary object detection, image-text retrieval, and general multimodal benchmarks. These results highlight FG-CLIP's effectiveness in capturing fine-grained image details and improving overall model performance. The related data, code, and models are available at https://github.com/360CVGroup/FG-CLIP.
Point2Primitive: CAD Reconstruction from Point Cloud by Direct Primitive Prediction
May 04, 2025



Recovering CAD models from point clouds, especially the sketch-extrusion process, can be seen as the process of rebuilding the topology and extrusion primitives. Previous methods utilize implicit fields for sketch representation, leading to shape reconstruction of curved edges. In this paper, we proposed a CAD reconstruction network that produces editable CAD models from input point clouds (Point2Primitive) by directly predicting every element of the extrusion primitives. Point2Primitive can directly detect and predict sketch curves (type and parameter) from point clouds based on an improved transformer. The sketch curve parameters are formulated as position queries and optimized in an autoregressive way, leading to high parameter accuracy. The topology is rebuilt by extrusion segmentation, and each extrusion parameter (sketch and extrusion operation) is recovered by combining the predicted curves and the computed extrusion operation. Extensive experiments demonstrate that our method is superior in primitive prediction accuracy and CAD reconstruction. The reconstructed shapes are of high geometrical fidelity.
100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models
May 01, 2025The recent development of reasoning language models (RLMs) represents a novel evolution in large language models. In particular, the recent release of DeepSeek-R1 has generated widespread social impact and sparked enthusiasm in the research community for exploring the explicit reasoning paradigm of language models. However, the implementation details of the released models have not been fully open-sourced by DeepSeek, including DeepSeek-R1-Zero, DeepSeek-R1, and the distilled small models. As a result, many replication studies have emerged aiming to reproduce the strong performance achieved by DeepSeek-R1, reaching comparable performance through similar training procedures and fully open-source data resources. These works have investigated feasible strategies for supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR), focusing on data preparation and method design, yielding various valuable insights. In this report, we provide a summary of recent replication studies to inspire future research. We primarily focus on SFT and RLVR as two main directions, introducing the details for data construction, method design and training procedure of current replication studies. Moreover, we conclude key findings from the implementation details and experimental results reported by these studies, anticipating to inspire future research. We also discuss additional techniques of enhancing RLMs, highlighting the potential of expanding the application scope of these models, and discussing the challenges in development. By this survey, we aim to help researchers and developers of RLMs stay updated with the latest advancements, and seek to inspire new ideas to further enhance RLMs.
Shifts in Doctors' Eye Movements Between Real and AI-Generated Medical Images
Apr 21, 2025Eye-tracking analysis plays a vital role in medical imaging, providing key insights into how radiologists visually interpret and diagnose clinical cases. In this work, we first analyze radiologists' attention and agreement by measuring the distribution of various eye-movement patterns, including saccades direction, amplitude, and their joint distribution. These metrics help uncover patterns in attention allocation and diagnostic strategies. Furthermore, we investigate whether and how doctors' gaze behavior shifts when viewing authentic (Real) versus deep-learning-generated (Fake) images. To achieve this, we examine fixation bias maps, focusing on first, last, short, and longest fixations independently, along with detailed saccades patterns, to quantify differences in gaze distribution and visual saliency between authentic and synthetic images.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.