 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Language-Supervised Zero-Shot Learning with Self-Distillation
Apr 18, 2021
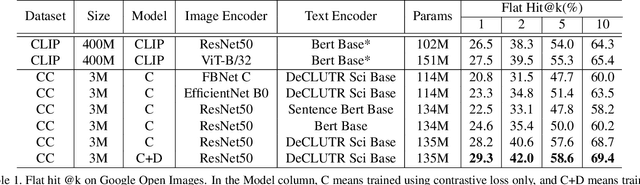
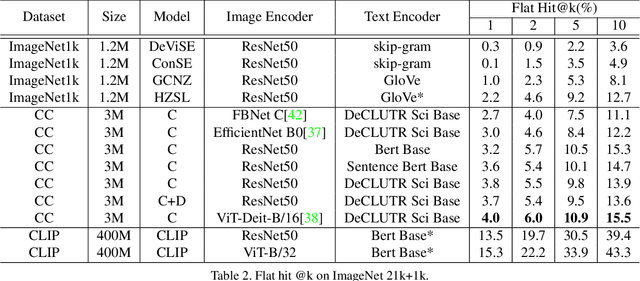
Traditional computer vision models are trained to predict a fixed set of predefined categories. Recently, natural language has been shown to be a broader and richer source of supervision that provides finer descriptions to visual concepts than supervised "gold" labels. Previous works, such as CLIP, use a simple pretraining task of predicting the pairings between images and text captions. CLIP, however, is data hungry and requires more than 400M image text pairs for training. We propose a data-efficient contrastive distillation method that uses soft labels to learn from noisy image-text pairs. Our model transfers knowledge from pretrained image and sentence encoders and achieves strong performance with only 3M image text pairs, 133x smaller than CLIP. Our method exceeds the previous SoTA of general zero-shot learning on ImageNet 21k+1k by 73% relatively with a ResNet50 image encoder and DeCLUTR text encoder. We also beat CLIP by 10.5% relatively on zero-shot evaluation on Google Open Images (19,958 classes).
You Only Group Once: Efficient Point-Cloud Processing with Token Representation and Relation Inference Module
Mar 24, 2021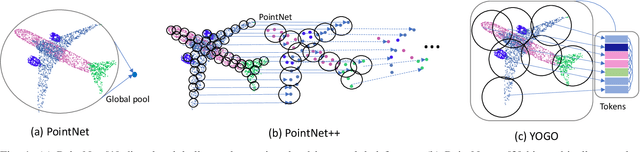
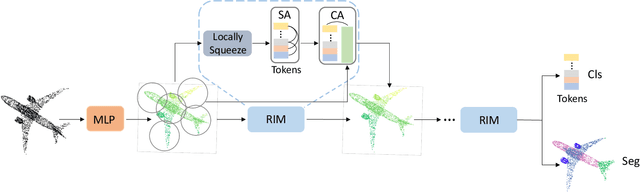
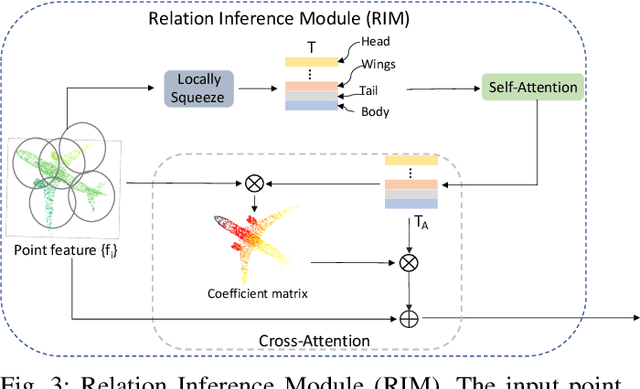
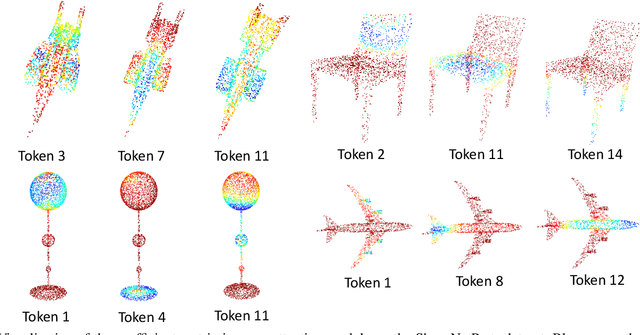
3D point-cloud-based perception is a challenging but crucial computer vision task. A point-cloud consists of a sparse, unstructured, and unordered set of points. To understand a point-cloud, previous point-based methods, such as PointNet++, extract visual features through hierarchically aggregation of local features. However, such methods have several critical limitations: 1) Such methods require several sampling and grouping operations, which slow down the inference speed. 2) Such methods spend an equal amount of computation on each points in a point-cloud, though many of points are redundant. 3) Such methods aggregate local features together through downsampling, which leads to information loss and hurts the perception performance. To overcome these challenges, we propose a novel, simple, and elegant deep learning model called YOGO (You Only Group Once). Compared with previous methods, YOGO only needs to sample and group a point-cloud once, so it is very efficient. Instead of operating on points, YOGO operates on a small number of tokens, each of which summarizes the point features in a sub-region. This allows us to avoid computing on the redundant points and thus boosts efficiency.Moreover, YOGO preserves point-wise features by projecting token features to point features although the computation is performed on tokens. This avoids information loss and can improve point-wise perception performance. We conduct thorough experiments to demonstrate that YOGO achieves at least 3.0x speedup over point-based baselines while delivering competitive classification and segmentation performance on the ModelNet, ShapeNetParts and S3DIS datasets.
Improving Context-Based Meta-Reinforcement Learning with Self-Supervised Trajectory Contrastive Learning
Mar 10, 2021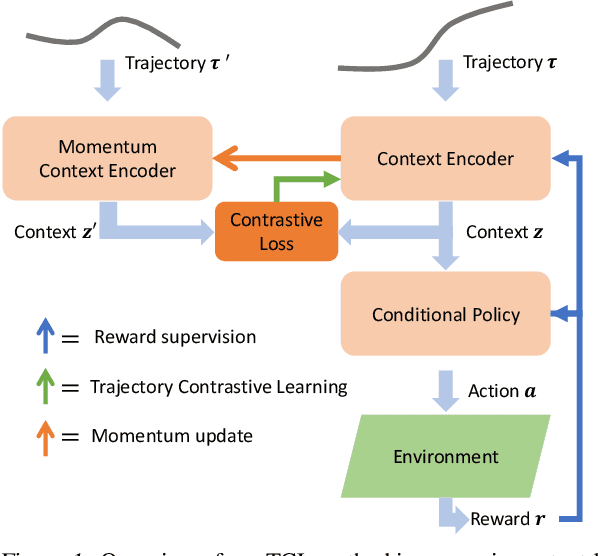
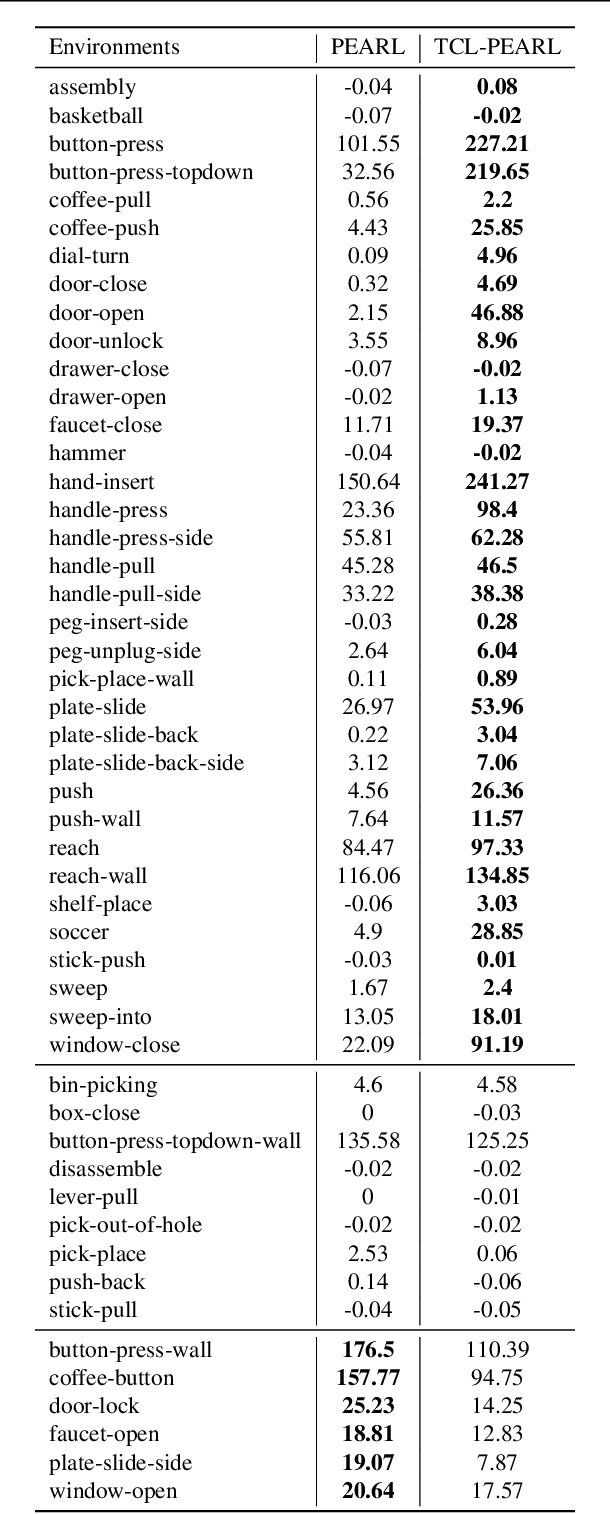
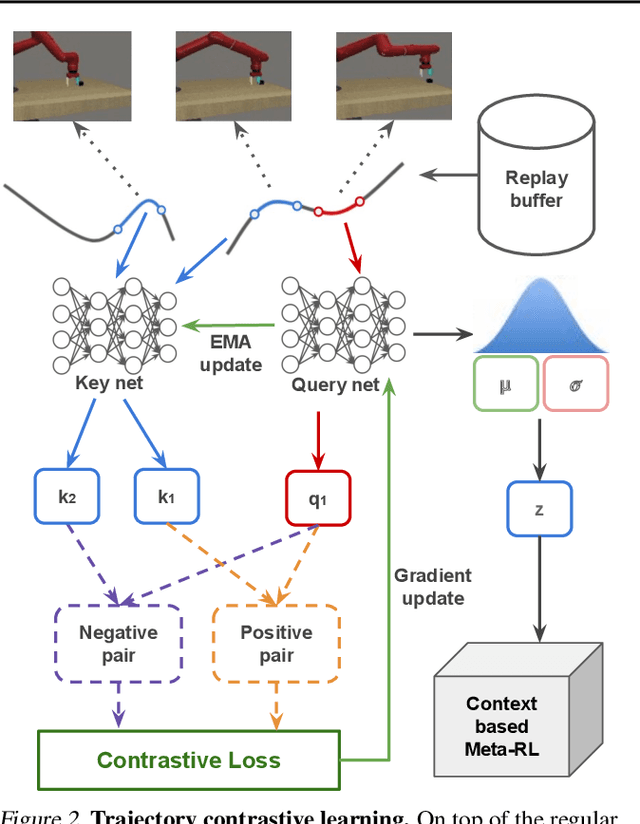

Meta-reinforcement learning typically requires orders of magnitude more samples than single task reinforcement learning methods. This is because meta-training needs to deal with more diverse distributions and train extra components such as context encoders. To address this, we propose a novel self-supervised learning task, which we named Trajectory Contrastive Learning (TCL), to improve meta-training. TCL adopts contrastive learning and trains a context encoder to predict whether two transition windows are sampled from the same trajectory. TCL leverages the natural hierarchical structure of context-based meta-RL and makes minimal assumptions, allowing it to be generally applicable to context-based meta-RL algorithms. It accelerates the training of context encoders and improves meta-training overall. Experiments show that TCL performs better or comparably than a strong meta-RL baseline in most of the environments on both meta-RL MuJoCo (5 of 6) and Meta-World benchmarks (44 out of 50).
Unbiased Teacher for Semi-Supervised Object Detection
Feb 18, 2021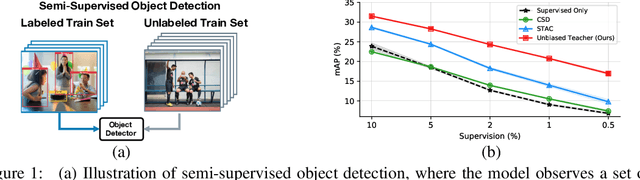

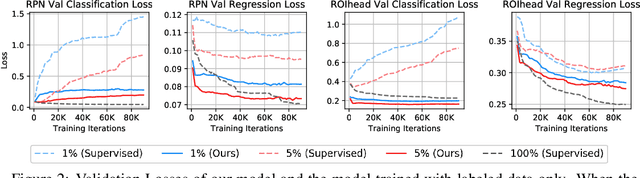
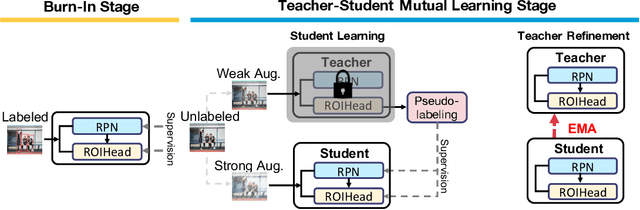
Semi-supervised learning, i.e., training networks with both labeled and unlabeled data, has made significant progress recently. However, existing works have primarily focused on image classification tasks and neglected object detection which requires more annotation effort. In this work, we revisit the Semi-Supervised Object Detection (SS-OD) and identify the pseudo-labeling bias issue in SS-OD. To address this, we introduce Unbiased Teacher, a simple yet effective approach that jointly trains a student and a gradually progressing teacher in a mutually-beneficial manner. Together with a class-balance loss to downweight overly confident pseudo-labels, Unbiased Teacher consistently improved state-of-the-art methods by significant margins on COCO-standard, COCO-additional, and VOC datasets. Specifically, Unbiased Teacher achieves 6.8 absolute mAP improvements against state-of-the-art method when using 1% of labeled data on MS-COCO, achieves around 10 mAP improvements against the supervised baseline when using only 0.5, 1, 2% of labeled data on MS-COCO.
FBWave: Efficient and Scalable Neural Vocoders for Streaming Text-To-Speech on the Edge
Nov 25, 2020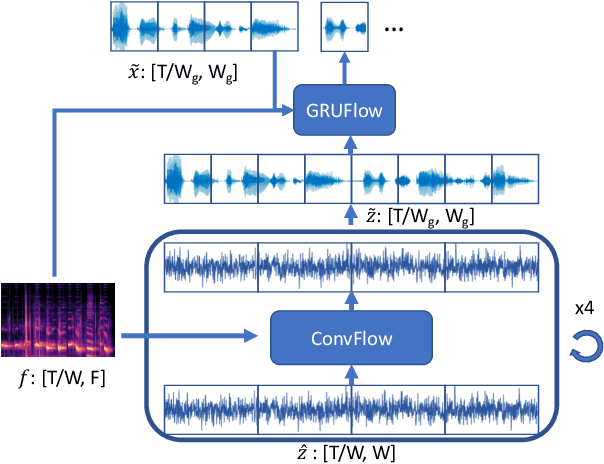
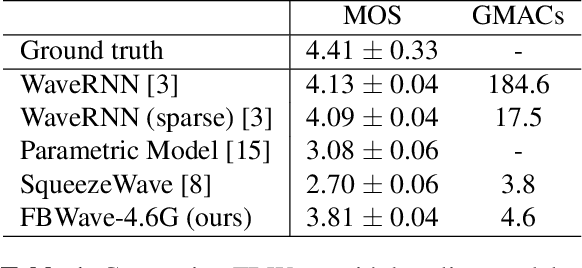
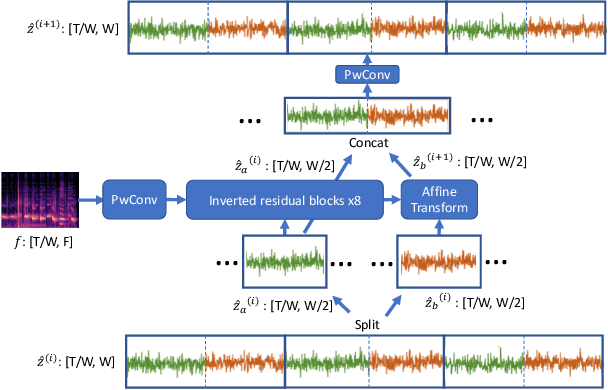

Nowadays more and more applications can benefit from edge-based text-to-speech (TTS). However, most existing TTS models are too computationally expensive and are not flexible enough to be deployed on the diverse variety of edge devices with their equally diverse computational capacities. To address this, we propose FBWave, a family of efficient and scalable neural vocoders that can achieve optimal performance-efficiency trade-offs for different edge devices. FBWave is a hybrid flow-based generative model that combines the advantages of autoregressive and non-autoregressive models. It produces high quality audio and supports streaming during inference while remaining highly computationally efficient. Our experiments show that FBWave can achieve similar audio quality to WaveRNN while reducing MACs by 40x. More efficient variants of FBWave can achieve up to 109x fewer MACs while still delivering acceptable audio quality. Audio demos are available at https://bichenwu09.github.io/vocoder_demos.
FP-NAS: Fast Probabilistic Neural Architecture Search
Nov 24, 2020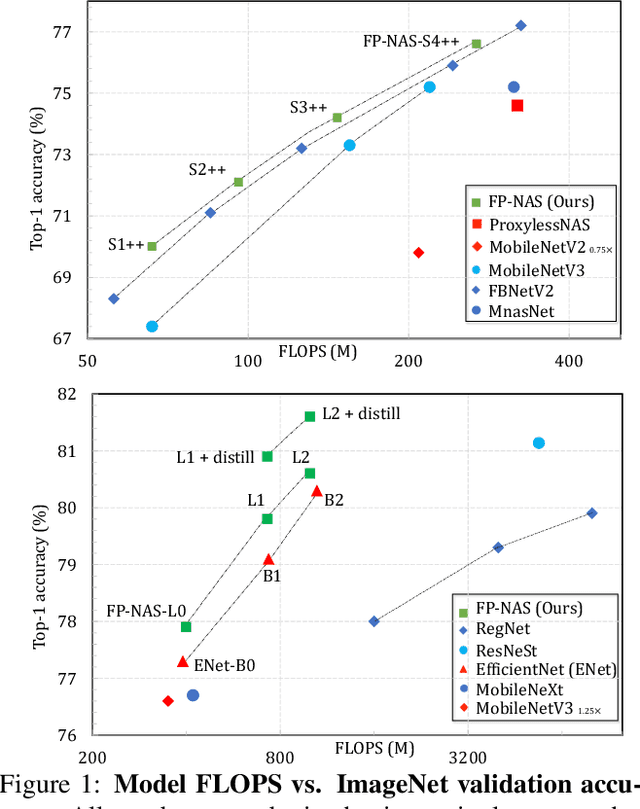
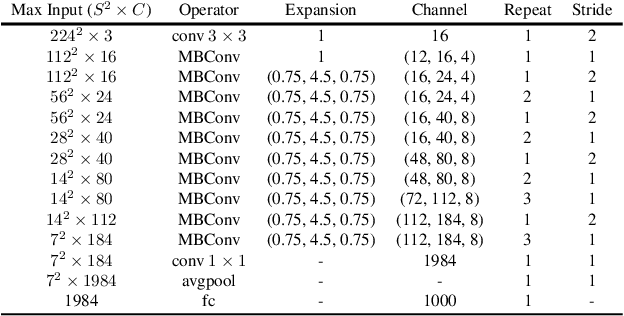
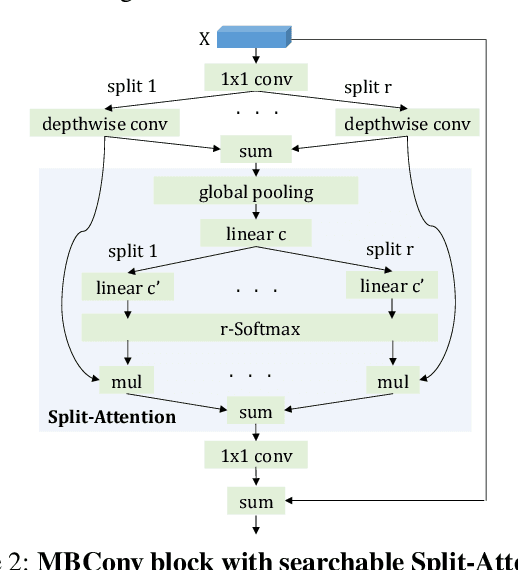

Differential Neural Architecture Search (NAS) requires all layer choices to be held in memory simultaneously; this limits the size of both search space and final architecture. In contrast, Probabilistic NAS, such as PARSEC, learns a distribution over high-performing architectures, and uses only as much memory as needed to train a single model. Nevertheless, it needs to sample many architectures, making it computationally expensive for searching in an extensive space. To solve these problems, we propose a sampling method adaptive to the distribution entropy, drawing more samples to encourage explorations at the beginning, and reducing samples as learning proceeds. Furthermore, to search fast in the multi-variate space, we propose a coarse-to-fine strategy by using a factorized distribution at the beginning which can reduce the number of architecture parameters by over an order of magnitude.We call this method Fast Probabilistic NAS (FP-NAS). Compared with PARSEC, it can sample 64% fewer architectures and search 2.1x faster. Compared with FBNetV2, FP-NAS is 1.9x - 3.6x faster, and the searched models outperform FBNetV2 models on ImageNet. FP-NAS allows us to expand the giant FBNetV2 space to be wider (i.e. larger channel choices) and deeper (i.e. more blocks), while adding Split-Attention block and enabling the search over the number of splits. When searching a model of size 0.4G FLOPS, FP-NAS is 132x faster than EfficientNet, and the searched FP-NAS-L0 model outperforms EfficientNet-B0 by 0.6% accuracy. Without using any architecture surrogate or scaling tricks, we directly search large models up to 1.0G FLOPS. Our FP-NAS-L2 model with simple distillation outperforms BigNAS-XL with advanced inplace distillation by 0.7% accuracy with less FLOPS.
A Review of Single-Source Deep Unsupervised Visual Domain Adaptation
Sep 19, 2020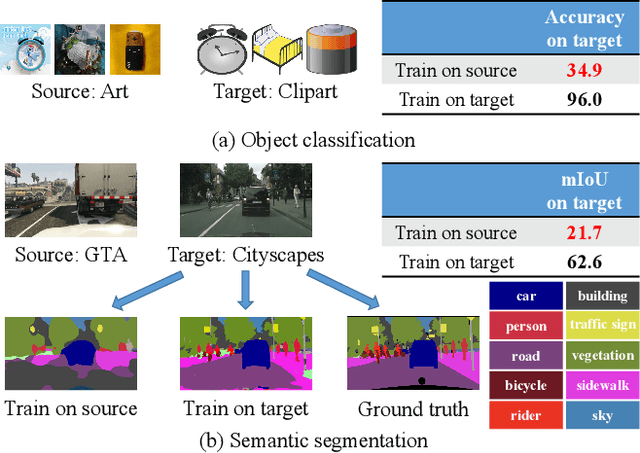
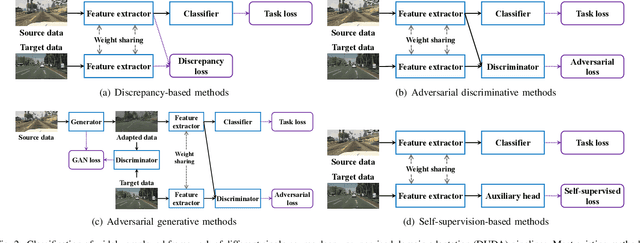

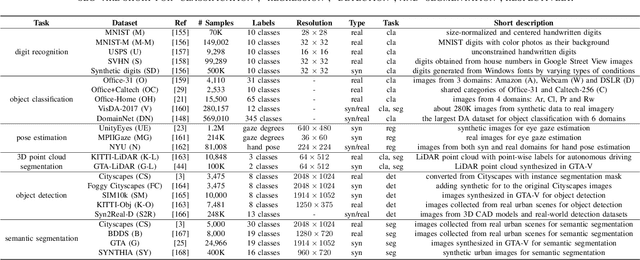
Large-scale labeled training datasets have enabled deep neural networks to excel across a wide range of benchmark vision tasks. However, in many applications, it is prohibitively expensive and time-consuming to obtain large quantities of labeled data. To cope with limited labeled training data, many have attempted to directly apply models trained on a large-scale labeled source domain to another sparsely labeled or unlabeled target domain. Unfortunately, direct transfer across domains often performs poorly due to the presence of domain shift or dataset bias. Domain adaptation is a machine learning paradigm that aims to learn a model from a source domain that can perform well on a different (but related) target domain. In this paper, we review the latest single-source deep unsupervised domain adaptation methods focused on visual tasks and discuss new perspectives for future research. We begin with the definitions of different domain adaptation strategies and the descriptions of existing benchmark datasets. We then summarize and compare different categories of single-source unsupervised domain adaptation methods, including discrepancy-based methods, adversarial discriminative methods, adversarial generative methods, and self-supervision-based methods. Finally, we discuss future research directions with challenges and possible solutions.
ePointDA: An End-to-End Simulation-to-Real Domain Adaptation Framework for LiDAR Point Cloud Segmentation
Sep 07, 2020
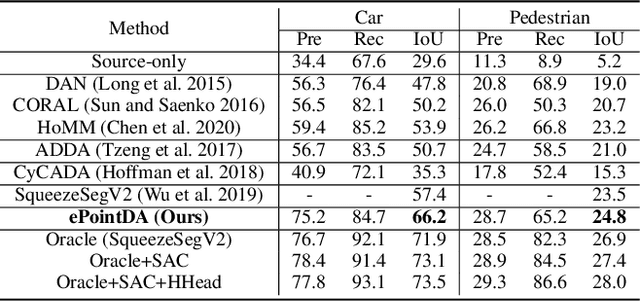
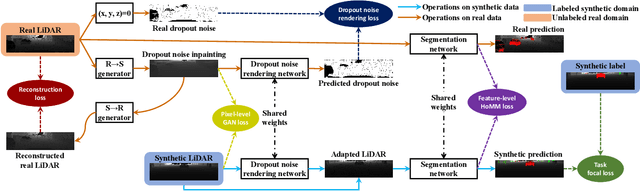
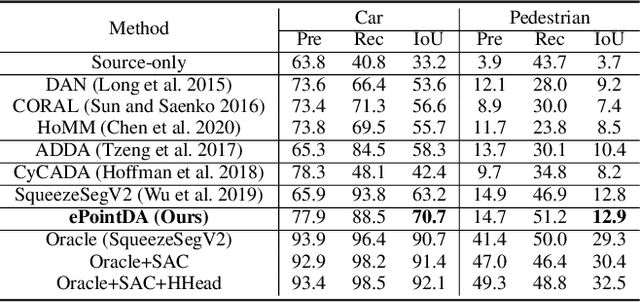
Due to its robust and precise distance measurements, LiDAR plays an important role in scene understanding for autonomous driving. Training deep neural networks (DNNs) on LiDAR data requires large-scale point-wise annotations, which are time-consuming and expensive to obtain. Instead, simulation-to-real domain adaptation (SRDA) trains a DNN using unlimited synthetic data with automatically generated labels and transfers the learned model to real scenarios. Existing SRDA methods for LiDAR point cloud segmentation mainly employ a multi-stage pipeline and focus on feature-level alignment. They require prior knowledge of real-world statistics and ignore the pixel-level dropout noise gap and the spatial feature gap between different domains. In this paper, we propose a novel end-to-end framework, named ePointDA, to address the above issues. Specifically, ePointDA consists of three components: self-supervised dropout noise rendering, statistics-invariant and spatially-adaptive feature alignment, and transferable segmentation learning. The joint optimization enables ePointDA to bridge the domain shift at the pixel-level by explicitly rendering dropout noise for synthetic LiDAR and at the feature-level by spatially aligning the features between different domains, without requiring the real-world statistics. Extensive experiments adapting from synthetic GTA-LiDAR to real KITTI and SemanticKITTI demonstrate the superiority of ePointDA for LiDAR point cloud segmentation.
Visual Transformers: Token-based Image Representation and Processing for Computer Vision
Jul 02, 2020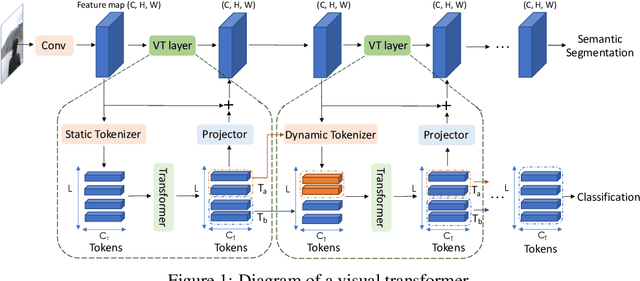
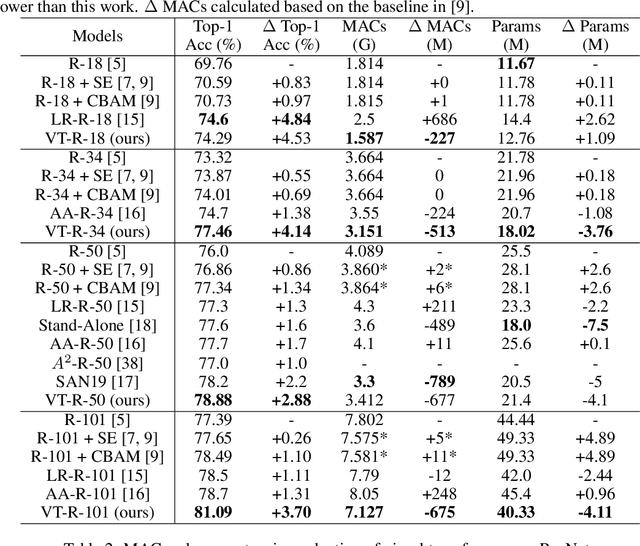
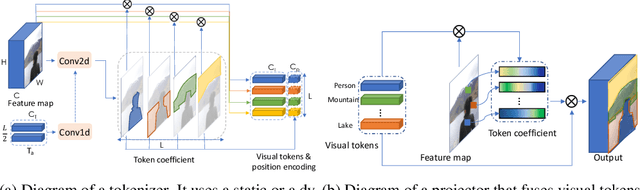

Computer vision has achieved great success using standardized image representations -- pixel arrays, and the corresponding deep learning operators -- convolutions. In this work, we challenge this paradigm: we instead (a) represent images as a set of visual tokens and (b) apply visual transformers to find relationships between visual semantic concepts. Given an input image, we dynamically extract a set of visual tokens from the image to obtain a compact representation for high-level semantics. We then use visual transformers to operate over the visual tokens to densely model relationships between them. We find that this paradigm of token-based image representation and processing drastically outperforms its convolutional counterparts on image classification and semantic segmentation. To demonstrate the power of this approach on ImageNet classification, we use ResNet as a convenient baseline and use visual transformers to replace the last stage of convolutions. This reduces the stage's MACs by up to 6.9x, while attaining up to 4.53 points higher top-1 accuracy. For semantic segmentation, we use a visual-transformer-based FPN (VT-FPN) module to replace a convolution-based FPN, saving 6.5x fewer MACs while achieving up to 0.35 points higher mIoU on LIP and COCO-stuff.
CoDeNet: Algorithm-hardware Co-design for Deformable Convolution
Jun 12, 2020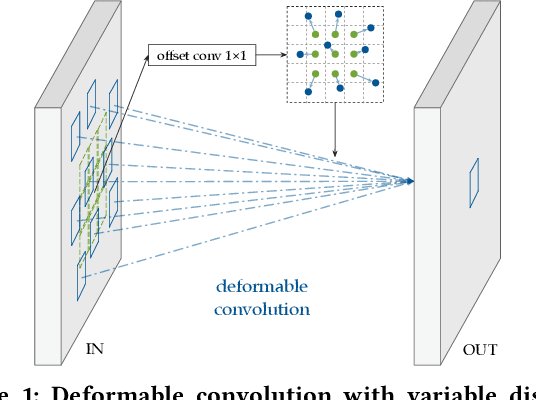
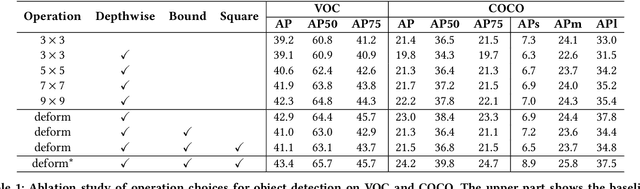
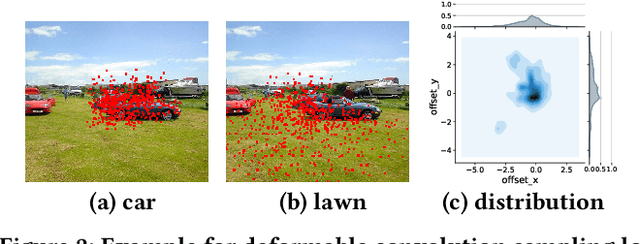
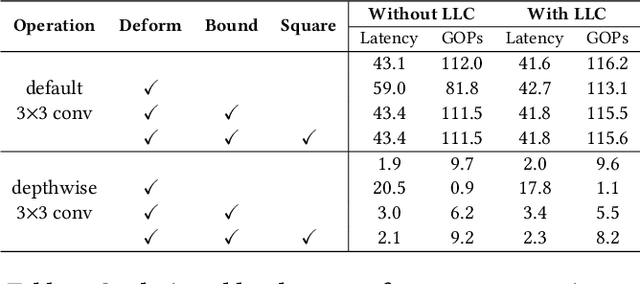
Deploying deep learning models on embedded systems for computer vision tasks has been challenging due to limited compute resources and strict energy budgets. The majority of existing work focuses on accelerating image classification, while other fundamental vision problems, such as object detection, have not been adequately addressed. Compared with image classification, detection problems are more sensitive to the spatial variance of objects, and therefore, require specialized convolutions to aggregate spatial information. To address this, recent work proposes dynamic deformable convolution to augment regular convolutions. Regular convolutions process a fixed grid of pixels across all the spatial locations in an image, while dynamic deformable convolution may access arbitrary pixels in the image and the access pattern is input-dependent and varies per spatial location. These properties lead to inefficient memory accesses of inputs with existing hardware. In this work, we first investigate the overhead of the deformable convolution on embedded FPGA SoCs, and introduce a depthwise deformable convolution to reduce the total number of operations required. We then show the speed-accuracy tradeoffs for a set of algorithm modifications including irregular-access versus limited-range and fixed-shape. We evaluate these algorithmic changes with corresponding hardware optimizations. Results show a 1.36x and 9.76x speedup respectively for the full and depthwise deformable convolution on the embedded FPGA accelerator with minor accuracy loss on the object detection task. We then co-design an efficient network CoDeNet with the modified deformable convolution for object detection and quantize the network to 4-bit weights and 8-bit activations. Results show that our designs lie on the pareto-optimal front of the latency-accuracy tradeoff for the object detection task on embedded FPGAs