 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Explainable Divide-and-Conquer Learning for Intrusion Detection
May 03, 2026Machine learning-based intrusion detection requires complex models to capture patterns in high-dimensional, noisy, and class-imbalanced raw network traffic, yet deploying such models remains impractical on resource-constrained devices with limited processing power and memory. In this paper, we present a correlation-aware divide-and-conquer learning technique that decomposes a complex learning problem into smaller, more manageable subproblems. This enables lightweight models as simple as decision trees to be trained on focused subtasks, yielding up to 43.3% higher local accuracy and up to 257 times reduction in model size on real-world network intrusion detection datasets, while also improving adversarial robustness and explainability.
SPRINT: Semi-supervised Prototypical Representation for Few-Shot Class-Incremental Tabular Learning
Mar 04, 2026Real-world systems must continuously adapt to novel concepts from limited data without forgetting previously acquired knowledge. While Few-Shot Class-Incremental Learning (FSCIL) is established in computer vision, its application to tabular domains remains largely unexplored. Unlike images, tabular streams (e.g., logs, sensors) offer abundant unlabeled data, a scarcity of expert annotations and negligible storage costs, features ignored by existing vision-based methods that rely on restrictive buffers. We introduce SPRINT, the first FSCIL framework tailored for tabular distributions. SPRINT introduces a mixed episodic training strategy that leverages confidence-based pseudo-labeling to enrich novel class representations and exploits low storage costs to retain base class history. Extensive evaluation across six diverse benchmarks spanning cybersecurity, healthcare, and ecological domains, demonstrates SPRINT's cross-domain robustness. It achieves a state-of-the-art average accuracy of 77.37% (5-shot), outperforming the strongest incremental baseline by 4.45%.
Retrieval Augmented Generation-based Large Language Models for Bridging Transportation Cybersecurity Legal Knowledge Gaps
May 23, 2025As connected and automated transportation systems evolve, there is a growing need for federal and state authorities to revise existing laws and develop new statutes to address emerging cybersecurity and data privacy challenges. This study introduces a Retrieval-Augmented Generation (RAG) based Large Language Model (LLM) framework designed to support policymakers by extracting relevant legal content and generating accurate, inquiry-specific responses. The framework focuses on reducing hallucinations in LLMs by using a curated set of domain-specific questions to guide response generation. By incorporating retrieval mechanisms, the system enhances the factual grounding and specificity of its outputs. Our analysis shows that the proposed RAG-based LLM outperforms leading commercial LLMs across four evaluation metrics: AlignScore, ParaScore, BERTScore, and ROUGE, demonstrating its effectiveness in producing reliable and context-aware legal insights. This approach offers a scalable, AI-driven method for legislative analysis, supporting efforts to update legal frameworks in line with advancements in transportation technologies.
MUBox: A Critical Evaluation Framework of Deep Machine Unlearning
May 13, 2025Recent legal frameworks have mandated the right to be forgotten, obligating the removal of specific data upon user requests. Machine Unlearning has emerged as a promising solution by selectively removing learned information from machine learning models. This paper presents MUBox, a comprehensive platform designed to evaluate unlearning methods in deep learning. MUBox integrates 23 advanced unlearning techniques, tested across six practical scenarios with 11 diverse evaluation metrics. It allows researchers and practitioners to (1) assess and compare the effectiveness of different machine unlearning methods across various scenarios; (2) examine the impact of current evaluation metrics on unlearning performance; and (3) conduct detailed comparative studies on machine unlearning in a unified framework. Leveraging MUBox, we systematically evaluate these unlearning methods in deep learning and uncover several key insights: (a) Even state-of-the-art unlearning methods, including those published in top-tier venues and winners of unlearning competitions, demonstrate inconsistent effectiveness across diverse scenarios. Prior research has predominantly focused on simplified settings, such as random forgetting and class-wise unlearning, highlighting the need for broader evaluations across more difficult unlearning tasks. (b) Assessing unlearning performance remains a non-trivial problem, as no single evaluation metric can comprehensively capture the effectiveness, efficiency, and preservation of model utility. Our findings emphasize the necessity of employing multiple metrics to achieve a balanced and holistic assessment of unlearning methods. (c) In the context of depoisoning, our evaluation reveals significant variability in the effectiveness of existing approaches, which is highly dependent on the specific type of poisoning attacks.
An Automated Vulnerability Detection Framework for Smart Contracts
Jan 20, 2023With the increase of the adoption of blockchain technology in providing decentralized solutions to various problems, smart contracts have become more popular to the point that billions of US Dollars are currently exchanged every day through such technology. Meanwhile, various vulnerabilities in smart contracts have been exploited by attackers to steal cryptocurrencies worth millions of dollars. The automatic detection of smart contract vulnerabilities therefore is an essential research problem. Existing solutions to this problem particularly rely on human experts to define features or different rules to detect vulnerabilities. However, this often causes many vulnerabilities to be ignored, and they are inefficient in detecting new vulnerabilities. In this study, to overcome such challenges, we propose a framework to automatically detect vulnerabilities in smart contracts on the blockchain. More specifically, first, we utilize novel feature vector generation techniques from bytecode of smart contract since the source code of smart contracts are rarely available in public. Next, the collected vectors are fed into our novel metric learning-based deep neural network(DNN) to get the detection result. We conduct comprehensive experiments on large-scale benchmarks, and the quantitative results demonstrate the effectiveness and efficiency of our approach.
Fairness-Aware Online Meta-learning
Aug 21, 2021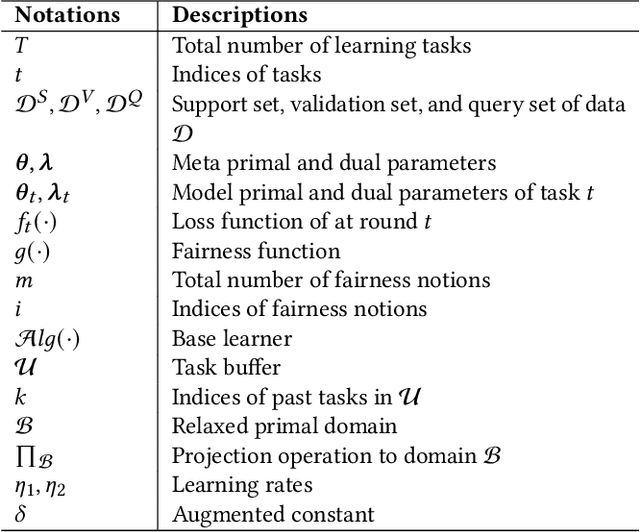
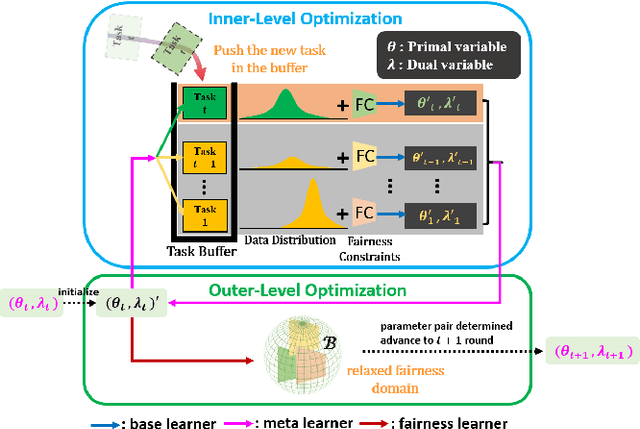

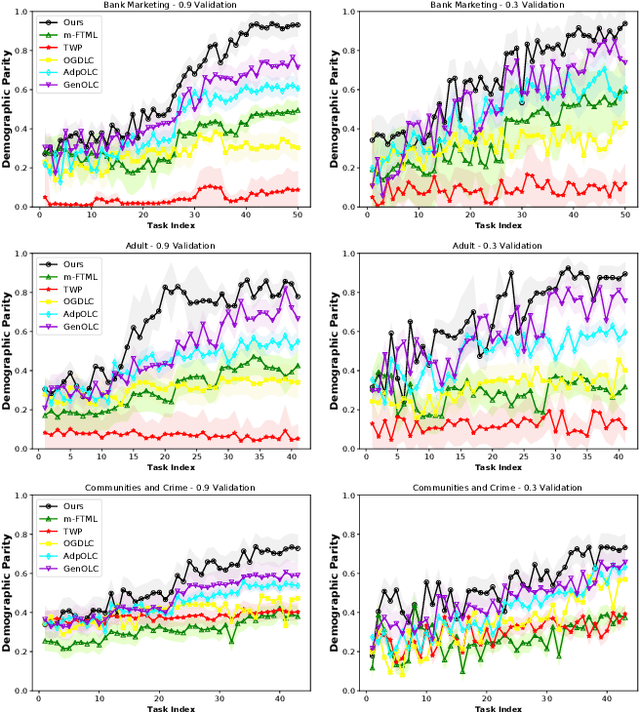
In contrast to offline working fashions, two research paradigms are devised for online learning: (1) Online Meta Learning (OML) learns good priors over model parameters (or learning to learn) in a sequential setting where tasks are revealed one after another. Although it provides a sub-linear regret bound, such techniques completely ignore the importance of learning with fairness which is a significant hallmark of human intelligence. (2) Online Fairness-Aware Learning. This setting captures many classification problems for which fairness is a concern. But it aims to attain zero-shot generalization without any task-specific adaptation. This therefore limits the capability of a model to adapt onto newly arrived data. To overcome such issues and bridge the gap, in this paper for the first time we proposed a novel online meta-learning algorithm, namely FFML, which is under the setting of unfairness prevention. The key part of FFML is to learn good priors of an online fair classification model's primal and dual parameters that are associated with the model's accuracy and fairness, respectively. The problem is formulated in the form of a bi-level convex-concave optimization. Theoretic analysis provides sub-linear upper bounds for loss regret and for violation of cumulative fairness constraints. Our experiments demonstrate the versatility of FFML by applying it to classification on three real-world datasets and show substantial improvements over the best prior work on the tradeoff between fairness and classification accuracy
Imbalanced Adversarial Training with Reweighting
Jul 28, 2021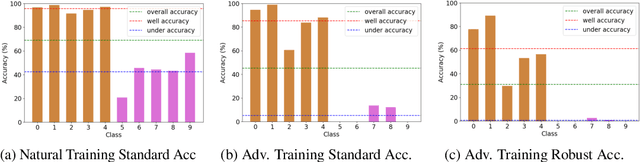
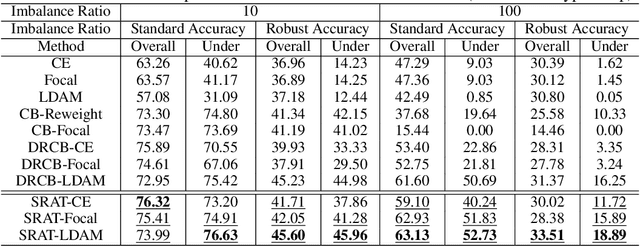
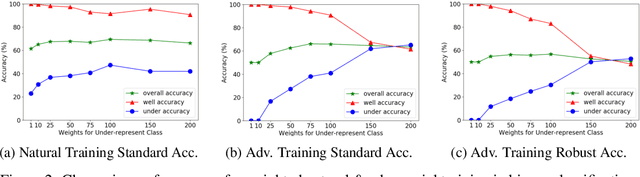
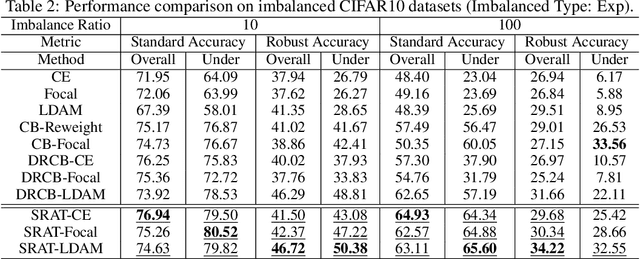
Adversarial training has been empirically proven to be one of the most effective and reliable defense methods against adversarial attacks. However, almost all existing studies about adversarial training are focused on balanced datasets, where each class has an equal amount of training examples. Research on adversarial training with imbalanced training datasets is rather limited. As the initial effort to investigate this problem, we reveal the facts that adversarially trained models present two distinguished behaviors from naturally trained models in imbalanced datasets: (1) Compared to natural training, adversarially trained models can suffer much worse performance on under-represented classes, when the training dataset is extremely imbalanced. (2) Traditional reweighting strategies may lose efficacy to deal with the imbalance issue for adversarial training. For example, upweighting the under-represented classes will drastically hurt the model's performance on well-represented classes, and as a result, finding an optimal reweighting value can be tremendously challenging. In this paper, to further understand our observations, we theoretically show that the poor data separability is one key reason causing this strong tension between under-represented and well-represented classes. Motivated by this finding, we propose Separable Reweighted Adversarial Training (SRAT) to facilitate adversarial training under imbalanced scenarios, by learning more separable features for different classes. Extensive experiments on various datasets verify the effectiveness of the proposed framework.
Towards Self-Adaptive Metric Learning On the Fly
Apr 03, 2021
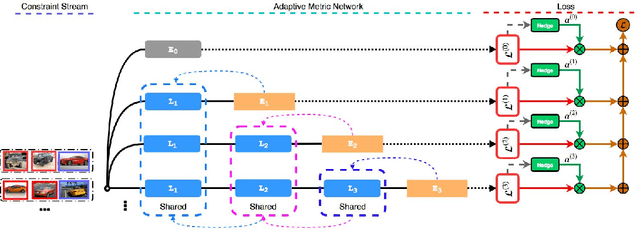
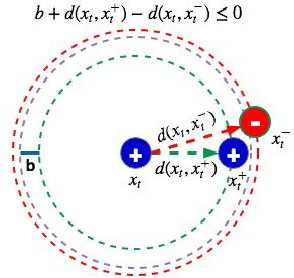
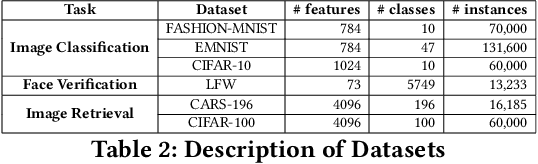
Good quality similarity metrics can significantly facilitate the performance of many large-scale, real-world applications. Existing studies have proposed various solutions to learn a Mahalanobis or bilinear metric in an online fashion by either restricting distances between similar (dissimilar) pairs to be smaller (larger) than a given lower (upper) bound or requiring similar instances to be separated from dissimilar instances with a given margin. However, these linear metrics learned by leveraging fixed bounds or margins may not perform well in real-world applications, especially when data distributions are complex. We aim to address the open challenge of "Online Adaptive Metric Learning" (OAML) for learning adaptive metric functions on the fly. Unlike traditional online metric learning methods, OAML is significantly more challenging since the learned metric could be non-linear and the model has to be self-adaptive as more instances are observed. In this paper, we present a new online metric learning framework that attempts to tackle the challenge by learning an ANN-based metric with adaptive model complexity from a stream of constraints. In particular, we propose a novel Adaptive-Bound Triplet Loss (ABTL) to effectively utilize the input constraints and present a novel Adaptive Hedge Update (AHU) method for online updating the model parameters. We empirically validate the effectiveness and efficacy of our framework on various applications such as real-world image classification, facial verification, and image retrieval.
Progressive One-shot Human Parsing
Dec 22, 2020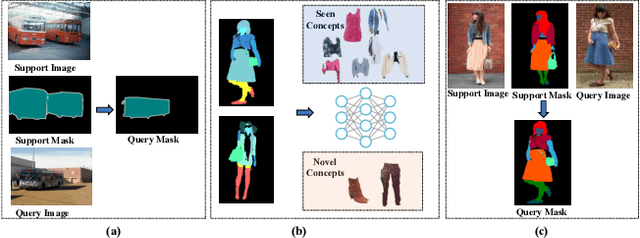

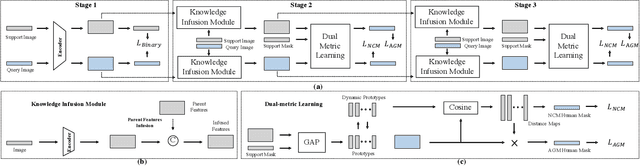
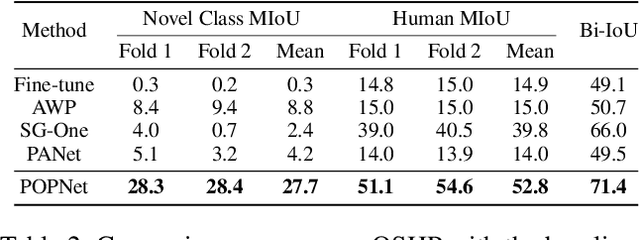
Prior human parsing models are limited to parsing humans into classes pre-defined in the training data, which is not flexible to generalize to unseen classes, e.g., new clothing in fashion analysis. In this paper, we propose a new problem named one-shot human parsing (OSHP) that requires to parse human into an open set of reference classes defined by any single reference example. During training, only base classes defined in the training set are exposed, which can overlap with part of reference classes. In this paper, we devise a novel Progressive One-shot Parsing network (POPNet) to address two critical challenges , i.e., testing bias and small sizes. POPNet consists of two collaborative metric learning modules named Attention Guidance Module and Nearest Centroid Module, which can learn representative prototypes for base classes and quickly transfer the ability to unseen classes during testing, thereby reducing testing bias. Moreover, POPNet adopts a progressive human parsing framework that can incorporate the learned knowledge of parent classes at the coarse granularity to help recognize the descendant classes at the fine granularity, thereby handling the small sizes issue. Experiments on the ATR-OS benchmark tailored for OSHP demonstrate POPNet outperforms other representative one-shot segmentation models by large margins and establishes a strong baseline. Source code can be found at https://github.com/Charleshhy/One-shot-Human-Parsing.
DeepSweep: An Evaluation Framework for Mitigating DNN Backdoor Attacks using Data Augmentation
Dec 13, 2020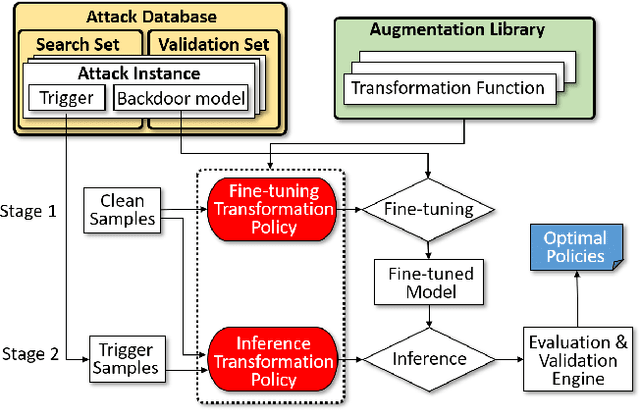
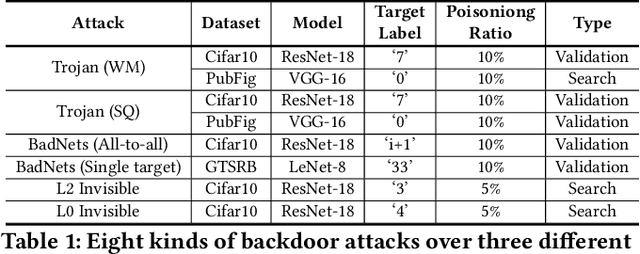

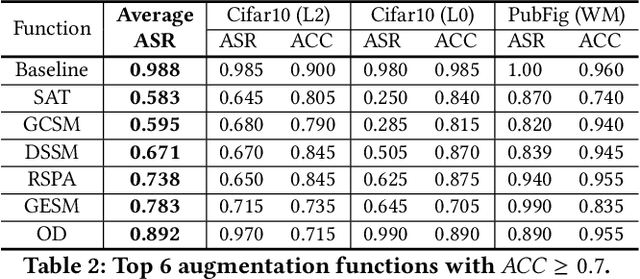
Public resources and services (e.g., datasets, training platforms, pre-trained models) have been widely adopted to ease the development of Deep Learning-based applications. However, if the third-party providers are untrusted, they can inject poisoned samples into the datasets or embed backdoors in those models. Such an integrity breach can cause severe consequences, especially in safety- and security-critical applications. Various backdoor attack techniques have been proposed for higher effectiveness and stealthiness. Unfortunately, existing defense solutions are not practical to thwart those attacks in a comprehensive way. In this paper, we investigate the effectiveness of data augmentation techniques in mitigating backdoor attacks and enhancing DL models' robustness. An evaluation framework is introduced to achieve this goal. Specifically, we consider a unified defense solution, which (1) adopts a data augmentation policy to fine-tune the infected model and eliminate the effects of the embedded backdoor; (2) uses another augmentation policy to preprocess input samples and invalidate the triggers during inference. We propose a systematic approach to discover the optimal policies for defending against different backdoor attacks by comprehensively evaluating 71 state-of-the-art data augmentation functions. Extensive experiments show that our identified policy can effectively mitigate eight different kinds of backdoor attacks and outperform five existing defense methods. We envision this framework can be a good benchmark tool to advance future DNN backdoor studies.