 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGitInject: Real-World Prompt Injection Attacks in AI-Powered CI/CD Pipelines
Jun 07, 2026AI-powered agents are increasingly embedded in continuous integration and continuous delivery/deployment (CI/CD) pipelines to autonomously review pull requests (PRs), triage issues, and maintain codebases. These agents ingest untrusted content while operating with elevated repository permissions, making them a natural target for prompt injection attacks with supply chain consequences. We present GitInject, an open-source framework for evaluating prompt injection vulnerabilities in real, live GitHub workflows, a widely deployed instance of CI/CD pipelines. Unlike prior agent security benchmarks that simulate tool calls, GitInject provisions ephemeral repositories and triggers actual workflow runs, so that sandbox constraints, credential handling, and permission boundaries behave exactly as in production. Using GitInject, we study workflow configurations across four AI providers and document eleven named attacks spanning config-file injection, credential exfiltration, judgment manipulation, and availability. We find that all tested providers are susceptible to at least one attack class in their default configuration, and that the most critical vulnerabilities are structural: they arise from how CI/CD infrastructure handles credentials and configuration files, not from any specific model's behavior. For each confirmed attack class, we identify the minimum-cost workflow-level countermeasure and analyze its coverage and limitations. GitInject is released publicly to facilitate further research in this direction.
SPRINT: Semi-supervised Prototypical Representation for Few-Shot Class-Incremental Tabular Learning
Mar 04, 2026Real-world systems must continuously adapt to novel concepts from limited data without forgetting previously acquired knowledge. While Few-Shot Class-Incremental Learning (FSCIL) is established in computer vision, its application to tabular domains remains largely unexplored. Unlike images, tabular streams (e.g., logs, sensors) offer abundant unlabeled data, a scarcity of expert annotations and negligible storage costs, features ignored by existing vision-based methods that rely on restrictive buffers. We introduce SPRINT, the first FSCIL framework tailored for tabular distributions. SPRINT introduces a mixed episodic training strategy that leverages confidence-based pseudo-labeling to enrich novel class representations and exploits low storage costs to retain base class history. Extensive evaluation across six diverse benchmarks spanning cybersecurity, healthcare, and ecological domains, demonstrates SPRINT's cross-domain robustness. It achieves a state-of-the-art average accuracy of 77.37% (5-shot), outperforming the strongest incremental baseline by 4.45%.
CourtGuard: A Model-Agnostic Framework for Zero-Shot Policy Adaptation in LLM Safety
Feb 26, 2026Current safety mechanisms for Large Language Models (LLMs) rely heavily on static, fine-tuned classifiers that suffer from adaptation rigidity, the inability to enforce new governance rules without expensive retraining. To address this, we introduce CourtGuard, a retrieval-augmented multi-agent framework that reimagines safety evaluation as Evidentiary Debate. By orchestrating an adversarial debate grounded in external policy documents, CourtGuard achieves state-of-the-art performance across 7 safety benchmarks, outperforming dedicated policy-following baselines without fine-tuning. Beyond standard metrics, we highlight two critical capabilities: (1) Zero-Shot Adaptability, where our framework successfully generalized to an out-of-domain Wikipedia Vandalism task (achieving 90\% accuracy) by swapping the reference policy; and (2) Automated Data Curation and Auditing, where we leveraged CourtGuard to curate and audit nine novel datasets of sophisticated adversarial attacks. Our results demonstrate that decoupling safety logic from model weights offers a robust, interpretable, and adaptable path for meeting current and future regulatory requirements in AI governance.
Beyond Refusal: Probing the Limits of Agentic Self-Correction for Semantic Sensitive Information
Feb 25, 2026While defenses for structured PII are mature, Large Language Models (LLMs) pose a new threat: Semantic Sensitive Information (SemSI), where models infer sensitive identity attributes, generate reputation-harmful content, or hallucinate potentially wrong information. The capacity of LLMs to self-regulate these complex, context-dependent sensitive information leaks without destroying utility remains an open scientific question. To address this, we introduce SemSIEdit, an inference-time framework where an agentic "Editor" iteratively critiques and rewrites sensitive spans to preserve narrative flow rather than simply refusing to answer. Our analysis reveals a Privacy-Utility Pareto Frontier, where this agentic rewriting reduces leakage by 34.6% across all three SemSI categories while incurring a marginal utility loss of 9.8%. We also uncover a Scale-Dependent Safety Divergence: large reasoning models (e.g., GPT-5) achieve safety through constructive expansion (adding nuance), whereas capacity-constrained models revert to destructive truncation (deleting text). Finally, we identify a Reasoning Paradox: while inference-time reasoning increases baseline risk by enabling the model to make deeper sensitive inferences, it simultaneously empowers the defense to execute safe rewrites.
SIGMA: Search-Augmented On-Demand Knowledge Integration for Agentic Mathematical Reasoning
Oct 31, 2025Solving mathematical reasoning problems requires not only accurate access to relevant knowledge but also careful, multi-step thinking. However, current retrieval-augmented models often rely on a single perspective, follow inflexible search strategies, and struggle to effectively combine information from multiple sources. We introduce SIGMA (Search-Augmented On-Demand Knowledge Integration for AGentic Mathematical reAsoning), a unified framework that orchestrates specialized agents to independently reason, perform targeted searches, and synthesize findings through a moderator mechanism. Each agent generates hypothetical passages to optimize retrieval for its analytic perspective, ensuring knowledge integration is both context-sensitive and computation-efficient. When evaluated on challenging benchmarks such as MATH500, AIME, and PhD-level science QA GPQA, SIGMA consistently outperforms both open- and closed-source systems, achieving an absolute performance improvement of 7.4%. Our results demonstrate that multi-agent, on-demand knowledge integration significantly enhances both reasoning accuracy and efficiency, offering a scalable approach for complex, knowledge-intensive problem-solving. We will release the code upon publication.
Text Classification for Azerbaijani Language Using Machine Learning and Embedding
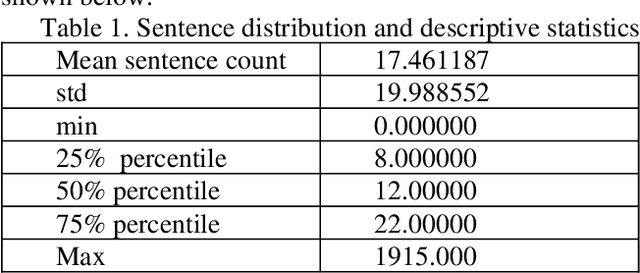
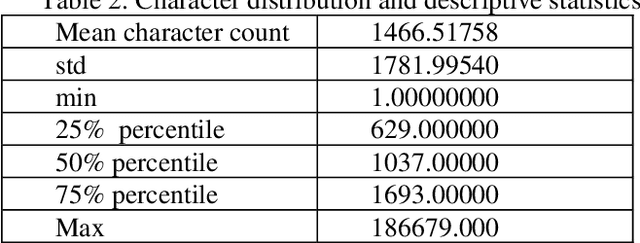
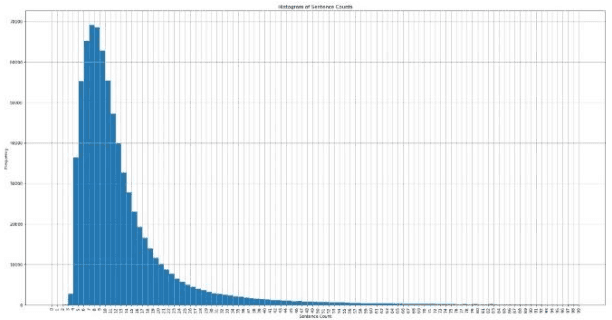
Dec 26, 2019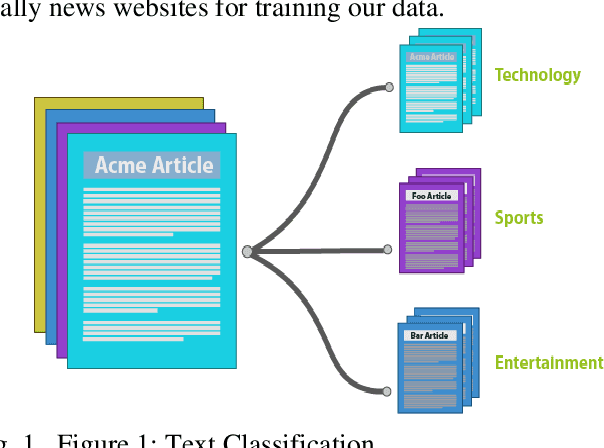
Text classification systems will help to solve the text clustering problem in the Azerbaijani language. There are some text-classification applications for foreign languages, but we tried to build a newly developed system to solve this problem for the Azerbaijani language. Firstly, we tried to find out potential practice areas. The system will be useful in a lot of areas. It will be mostly used in news feed categorization. News websites can automatically categorize news into classes such as sports, business, education, science, etc. The system is also used in sentiment analysis for product reviews. For example, the company shares a photo of a new product on Facebook and the company receives a thousand comments for new products. The systems classify the comments into categories like positive or negative. The system can also be applied in recommended systems, spam filtering, etc. Various machine learning techniques such as Naive Bayes, SVM, Decision Trees have been devised to solve the text classification problem in Azerbaijani language.