 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Explainable Divide-and-Conquer Learning for Intrusion Detection
May 03, 2026Machine learning-based intrusion detection requires complex models to capture patterns in high-dimensional, noisy, and class-imbalanced raw network traffic, yet deploying such models remains impractical on resource-constrained devices with limited processing power and memory. In this paper, we present a correlation-aware divide-and-conquer learning technique that decomposes a complex learning problem into smaller, more manageable subproblems. This enables lightweight models as simple as decision trees to be trained on focused subtasks, yielding up to 43.3% higher local accuracy and up to 257 times reduction in model size on real-world network intrusion detection datasets, while also improving adversarial robustness and explainability.
SPRINT: Semi-supervised Prototypical Representation for Few-Shot Class-Incremental Tabular Learning
Mar 04, 2026Real-world systems must continuously adapt to novel concepts from limited data without forgetting previously acquired knowledge. While Few-Shot Class-Incremental Learning (FSCIL) is established in computer vision, its application to tabular domains remains largely unexplored. Unlike images, tabular streams (e.g., logs, sensors) offer abundant unlabeled data, a scarcity of expert annotations and negligible storage costs, features ignored by existing vision-based methods that rely on restrictive buffers. We introduce SPRINT, the first FSCIL framework tailored for tabular distributions. SPRINT introduces a mixed episodic training strategy that leverages confidence-based pseudo-labeling to enrich novel class representations and exploits low storage costs to retain base class history. Extensive evaluation across six diverse benchmarks spanning cybersecurity, healthcare, and ecological domains, demonstrates SPRINT's cross-domain robustness. It achieves a state-of-the-art average accuracy of 77.37% (5-shot), outperforming the strongest incremental baseline by 4.45%.
Controllable Fake Document Infilling for Cyber Deception
Oct 18, 2022
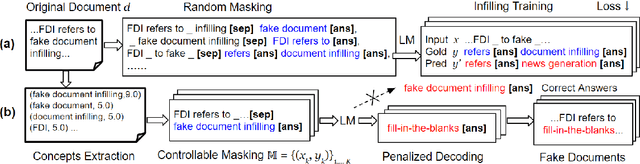

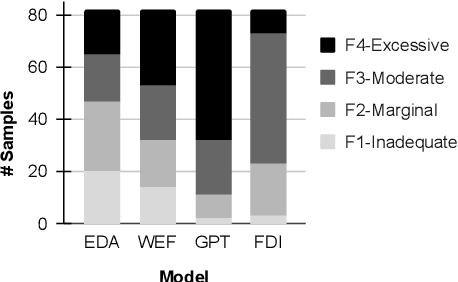
Recent works in cyber deception study how to deter malicious intrusion by generating multiple fake versions of a critical document to impose costs on adversaries who need to identify the correct information. However, existing approaches are context-agnostic, resulting in sub-optimal and unvaried outputs. We propose a novel context-aware model, Fake Document Infilling (FDI), by converting the problem to a controllable mask-then-infill procedure. FDI masks important concepts of varied lengths in the document, then infills a realistic but fake alternative considering both the previous and future contexts. We conduct comprehensive evaluations on technical documents and news stories. Results show that FDI outperforms the baselines in generating highly believable fakes with moderate modification to protect critical information and deceive adversaries.