 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELIOS: Hierarchical Exploration for Language-grounded Interaction in Open Scenes
Sep 26, 2025Language-specified mobile manipulation tasks in novel environments simultaneously face challenges interacting with a scene which is only partially observed, grounding semantic information from language instructions to the partially observed scene, and actively updating knowledge of the scene with new observations. To address these challenges, we propose HELIOS, a hierarchical scene representation and associated search objective to perform language specified pick and place mobile manipulation tasks. We construct 2D maps containing the relevant semantic and occupancy information for navigation while simultaneously actively constructing 3D Gaussian representations of task-relevant objects. We fuse observations across this multi-layered representation while explicitly modeling the multi-view consistency of the detections of each object. In order to efficiently search for the target object, we formulate an objective function balancing exploration of unobserved or uncertain regions with exploitation of scene semantic information. We evaluate HELIOS on the OVMM benchmark in the Habitat simulator, a pick and place benchmark in which perception is challenging due to large and complex scenes with comparatively small target objects. HELIOS achieves state-of-the-art results on OVMM. As our approach is zero-shot, HELIOS can also transfer to the real world without requiring additional data, as we illustrate by demonstrating it in a real world office environment on a Spot robot.
ASHiTA: Automatic Scene-grounded HIerarchical Task Analysis
Apr 10, 2025While recent work in scene reconstruction and understanding has made strides in grounding natural language to physical 3D environments, it is still challenging to ground abstract, high-level instructions to a 3D scene. High-level instructions might not explicitly invoke semantic elements in the scene, and even the process of breaking a high-level task into a set of more concrete subtasks, a process called hierarchical task analysis, is environment-dependent. In this work, we propose ASHiTA, the first framework that generates a task hierarchy grounded to a 3D scene graph by breaking down high-level tasks into grounded subtasks. ASHiTA alternates LLM-assisted hierarchical task analysis, to generate the task breakdown, with task-driven 3D scene graph construction to generate a suitable representation of the environment. Our experiments show that ASHiTA performs significantly better than LLM baselines in breaking down high-level tasks into environment-dependent subtasks and is additionally able to achieve grounding performance comparable to state-of-the-art methods.
NL-SLAM for OC-VLN: Natural Language Grounded SLAM for Object-Centric VLN
Nov 12, 2024



Landmark-based navigation (e.g. go to the wooden desk) and relative positional navigation (e.g. move 5 meters forward) are distinct navigation challenges solved very differently in existing robotics navigation methodology. We present a new dataset, OC-VLN, in order to distinctly evaluate grounding object-centric natural language navigation instructions in a method for performing landmark-based navigation. We also propose Natural Language grounded SLAM (NL-SLAM), a method to ground natural language instruction to robot observations and poses. We actively perform NL-SLAM in order to follow object-centric natural language navigation instructions. Our methods leverage pre-trained vision and language foundation models and require no task-specific training. We construct two strong baselines from state-of-the-art methods on related tasks, Object Goal Navigation and Vision Language Navigation, and we show that our approach, NL-SLAM, outperforms these baselines across all our metrics of success on OC-VLN. Finally, we successfully demonstrate the effectiveness of NL-SLAM for performing navigation instruction following in the real world on a Boston Dynamics Spot robot.
Task-Oriented Hierarchical Object Decomposition for Visuomotor Control
Nov 02, 2024



Good pre-trained visual representations could enable robots to learn visuomotor policy efficiently. Still, existing representations take a one-size-fits-all-tasks approach that comes with two important drawbacks: (1) Being completely task-agnostic, these representations cannot effectively ignore any task-irrelevant information in the scene, and (2) They often lack the representational capacity to handle unconstrained/complex real-world scenes. Instead, we propose to train a large combinatorial family of representations organized by scene entities: objects and object parts. This hierarchical object decomposition for task-oriented representations (HODOR) permits selectively assembling different representations specific to each task while scaling in representational capacity with the complexity of the scene and the task. In our experiments, we find that HODOR outperforms prior pre-trained representations, both scene vector representations and object-centric representations, for sample-efficient imitation learning across 5 simulated and 5 real-world manipulation tasks. We further find that the invariances captured in HODOR are inherited into downstream policies, which can robustly generalize to out-of-distribution test conditions, permitting zero-shot skill chaining. Appendix, code, and videos: https://sites.google.com/view/hodor-corl24.
Continuously Improving Mobile Manipulation with Autonomous Real-World RL
Sep 30, 2024



We present a fully autonomous real-world RL framework for mobile manipulation that can learn policies without extensive instrumentation or human supervision. This is enabled by 1) task-relevant autonomy, which guides exploration towards object interactions and prevents stagnation near goal states, 2) efficient policy learning by leveraging basic task knowledge in behavior priors, and 3) formulating generic rewards that combine human-interpretable semantic information with low-level, fine-grained observations. We demonstrate that our approach allows Spot robots to continually improve their performance on a set of four challenging mobile manipulation tasks, obtaining an average success rate of 80% across tasks, a 3-4 improvement over existing approaches. Videos can be found at https://continual-mobile-manip.github.io/
Uncertainty-Aware Deployment of Pre-trained Language-Conditioned Imitation Learning Policies
Mar 27, 2024



Large-scale robotic policies trained on data from diverse tasks and robotic platforms hold great promise for enabling general-purpose robots; however, reliable generalization to new environment conditions remains a major challenge. Toward addressing this challenge, we propose a novel approach for uncertainty-aware deployment of pre-trained language-conditioned imitation learning agents. Specifically, we use temperature scaling to calibrate these models and exploit the calibrated model to make uncertainty-aware decisions by aggregating the local information of candidate actions. We implement our approach in simulation using three such pre-trained models, and showcase its potential to significantly enhance task completion rates. The accompanying code is accessible at the link: https://github.com/BobWu1998/uncertainty_quant_all.git
VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation
Dec 06, 2023



Understanding how humans leverage semantic knowledge to navigate unfamiliar environments and decide where to explore next is pivotal for developing robots capable of human-like search behaviors. We introduce a zero-shot navigation approach, Vision-Language Frontier Maps (VLFM), which is inspired by human reasoning and designed to navigate towards unseen semantic objects in novel environments. VLFM builds occupancy maps from depth observations to identify frontiers, and leverages RGB observations and a pre-trained vision-language model to generate a language-grounded value map. VLFM then uses this map to identify the most promising frontier to explore for finding an instance of a given target object category. We evaluate VLFM in photo-realistic environments from the Gibson, Habitat-Matterport 3D (HM3D), and Matterport 3D (MP3D) datasets within the Habitat simulator. Remarkably, VLFM achieves state-of-the-art results on all three datasets as measured by success weighted by path length (SPL) for the Object Goal Navigation task. Furthermore, we show that VLFM's zero-shot nature enables it to be readily deployed on real-world robots such as the Boston Dynamics Spot mobile manipulation platform. We deploy VLFM on Spot and demonstrate its capability to efficiently navigate to target objects within an office building in the real world, without any prior knowledge of the environment. The accomplishments of VLFM underscore the promising potential of vision-language models in advancing the field of semantic navigation. Videos of real-world deployment can be viewed at naoki.io/vlfm.
EVORA: Deep Evidential Traversability Learning for Risk-Aware Off-Road Autonomy
Nov 10, 2023



Traversing terrain with good traction is crucial for achieving fast off-road navigation. Instead of manually designing costs based on terrain features, existing methods learn terrain properties directly from data via self-supervision, but challenges remain to properly quantify and mitigate risks due to uncertainties in learned models. This work efficiently quantifies both aleatoric and epistemic uncertainties by learning discrete traction distributions and probability densities of the traction predictor's latent features. Leveraging evidential deep learning, we parameterize Dirichlet distributions with the network outputs and propose a novel uncertainty-aware squared Earth Mover's distance loss with a closed-form expression that improves learning accuracy and navigation performance. The proposed risk-aware planner simulates state trajectories with the worst-case expected traction to handle aleatoric uncertainty, and penalizes trajectories moving through terrain with high epistemic uncertainty. Our approach is extensively validated in simulation and on wheeled and quadruped robots, showing improved navigation performance compared to methods that assume no slip, assume the expected traction, or optimize for the worst-case expected cost.
Uncertainty-driven Planner for Exploration and Navigation
Feb 24, 2022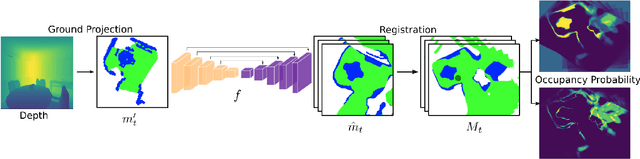
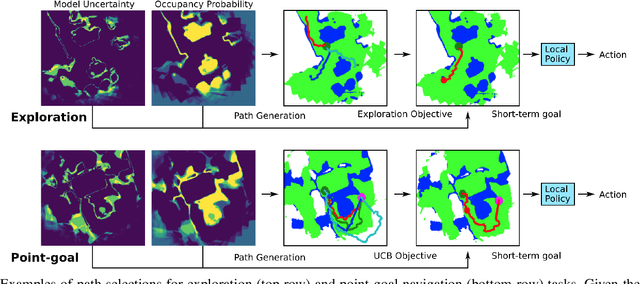

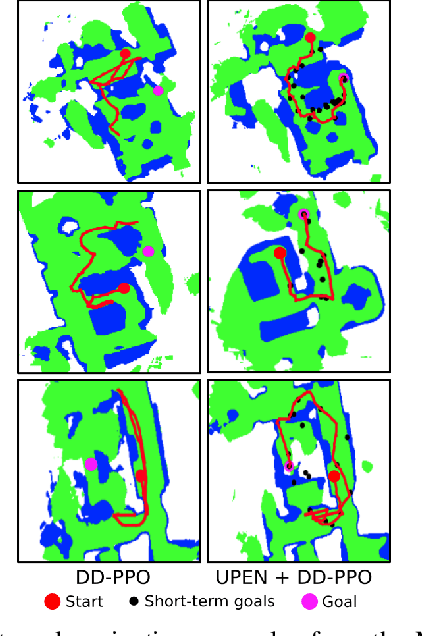
We consider the problems of exploration and point-goal navigation in previously unseen environments, where the spatial complexity of indoor scenes and partial observability constitute these tasks challenging. We argue that learning occupancy priors over indoor maps provides significant advantages towards addressing these problems. To this end, we present a novel planning framework that first learns to generate occupancy maps beyond the field-of-view of the agent, and second leverages the model uncertainty over the generated areas to formulate path selection policies for each task of interest. For point-goal navigation the policy chooses paths with an upper confidence bound policy for efficient and traversable paths, while for exploration the policy maximizes model uncertainty over candidate paths. We perform experiments in the visually realistic environments of Matterport3D using the Habitat simulator and demonstrate: 1) Improved results on exploration and map quality metrics over competitive methods, and 2) The effectiveness of our planning module when paired with the state-of-the-art DD-PPO method for the point-goal navigation task.
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Sep 27, 2021
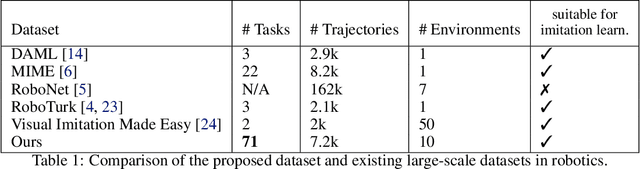

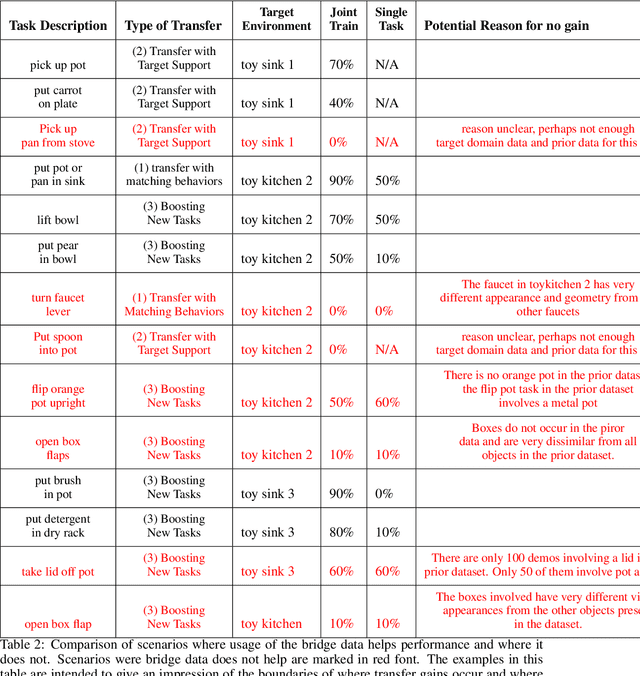
Robot learning holds the promise of learning policies that generalize broadly. However, such generalization requires sufficiently diverse datasets of the task of interest, which can be prohibitively expensive to collect. In other fields, such as computer vision, it is common to utilize shared, reusable datasets, such as ImageNet, to overcome this challenge, but this has proven difficult in robotics. In this paper, we ask: what would it take to enable practical data reuse in robotics for end-to-end skill learning? We hypothesize that the key is to use datasets with multiple tasks and multiple domains, such that a new user that wants to train their robot to perform a new task in a new domain can include this dataset in their training process and benefit from cross-task and cross-domain generalization. To evaluate this hypothesis, we collect a large multi-domain and multi-task dataset, with 7,200 demonstrations constituting 71 tasks across 10 environments, and empirically study how this data can improve the learning of new tasks in new environments. We find that jointly training with the proposed dataset and 50 demonstrations of a never-before-seen task in a new domain on average leads to a 2x improvement in success rate compared to using target domain data alone. We also find that data for only a few tasks in a new domain can bridge the domain gap and make it possible for a robot to perform a variety of prior tasks that were only seen in other domains. These results suggest that reusing diverse multi-task and multi-domain datasets, including our open-source dataset, may pave the way for broader robot generalization, eliminating the need to re-collect data for each new robot learning project.