 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSumo: Dynamic and Generalizable Whole-Body Loco-Manipulation
Apr 09, 2026This paper presents a sim-to-real approach that enables legged robots to dynamically manipulate large and heavy objects with whole-body dexterity. Our key insight is that by performing test-time steering of a pre-trained whole-body control policy with a sample-based planner, we can enable these robots to solve a variety of dynamic loco-manipulation tasks. Interestingly, we find our method generalizes to a diverse set of objects and tasks with no additional tuning or training, and can be further enhanced by flexibly adjusting the cost function at test time. We demonstrate the capabilities of our approach through a variety of challenging loco-manipulation tasks on a Spot quadruped robot in the real world, including uprighting a tire heavier than the robot's nominal lifting capacity and dragging a crowd-control barrier larger and taller than the robot itself. Additionally, we show that the same approach can be generalized to humanoid loco-manipulation tasks, such as opening a door and pushing a table, in simulation. Project code and videos are available at \href{https://sumo.rai-inst.com/}{https://sumo.rai-inst.com/}.
NovaFlow: Zero-Shot Manipulation via Actionable Flow from Generated Videos
Oct 09, 2025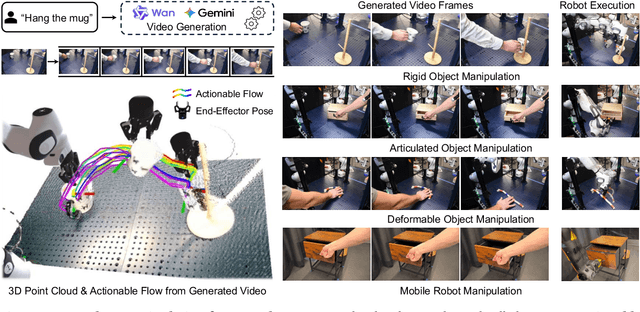
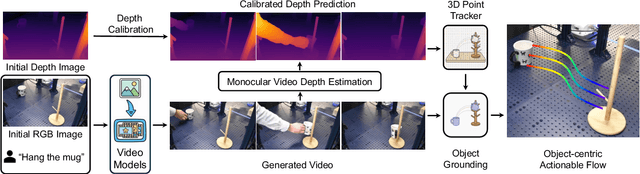


Enabling robots to execute novel manipulation tasks zero-shot is a central goal in robotics. Most existing methods assume in-distribution tasks or rely on fine-tuning with embodiment-matched data, limiting transfer across platforms. We present NovaFlow, an autonomous manipulation framework that converts a task description into an actionable plan for a target robot without any demonstrations. Given a task description, NovaFlow synthesizes a video using a video generation model and distills it into 3D actionable object flow using off-the-shelf perception modules. From the object flow, it computes relative poses for rigid objects and realizes them as robot actions via grasp proposals and trajectory optimization. For deformable objects, this flow serves as a tracking objective for model-based planning with a particle-based dynamics model. By decoupling task understanding from low-level control, NovaFlow naturally transfers across embodiments. We validate on rigid, articulated, and deformable object manipulation tasks using a table-top Franka arm and a Spot quadrupedal mobile robot, and achieve effective zero-shot execution without demonstrations or embodiment-specific training. Project website: https://novaflow.lhy.xyz/.
ASHiTA: Automatic Scene-grounded HIerarchical Task Analysis
Apr 10, 2025While recent work in scene reconstruction and understanding has made strides in grounding natural language to physical 3D environments, it is still challenging to ground abstract, high-level instructions to a 3D scene. High-level instructions might not explicitly invoke semantic elements in the scene, and even the process of breaking a high-level task into a set of more concrete subtasks, a process called hierarchical task analysis, is environment-dependent. In this work, we propose ASHiTA, the first framework that generates a task hierarchy grounded to a 3D scene graph by breaking down high-level tasks into grounded subtasks. ASHiTA alternates LLM-assisted hierarchical task analysis, to generate the task breakdown, with task-driven 3D scene graph construction to generate a suitable representation of the environment. Our experiments show that ASHiTA performs significantly better than LLM baselines in breaking down high-level tasks into environment-dependent subtasks and is additionally able to achieve grounding performance comparable to state-of-the-art methods.
NL-SLAM for OC-VLN: Natural Language Grounded SLAM for Object-Centric VLN
Nov 12, 2024



Landmark-based navigation (e.g. go to the wooden desk) and relative positional navigation (e.g. move 5 meters forward) are distinct navigation challenges solved very differently in existing robotics navigation methodology. We present a new dataset, OC-VLN, in order to distinctly evaluate grounding object-centric natural language navigation instructions in a method for performing landmark-based navigation. We also propose Natural Language grounded SLAM (NL-SLAM), a method to ground natural language instruction to robot observations and poses. We actively perform NL-SLAM in order to follow object-centric natural language navigation instructions. Our methods leverage pre-trained vision and language foundation models and require no task-specific training. We construct two strong baselines from state-of-the-art methods on related tasks, Object Goal Navigation and Vision Language Navigation, and we show that our approach, NL-SLAM, outperforms these baselines across all our metrics of success on OC-VLN. Finally, we successfully demonstrate the effectiveness of NL-SLAM for performing navigation instruction following in the real world on a Boston Dynamics Spot robot.