 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025



Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
Neural-FST Class Language Model for End-to-End Speech Recognition
Jan 31, 2022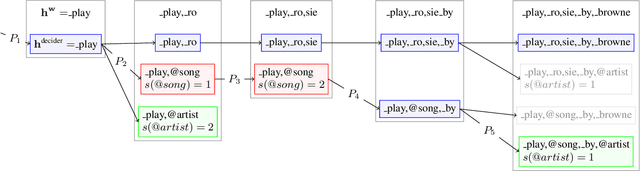
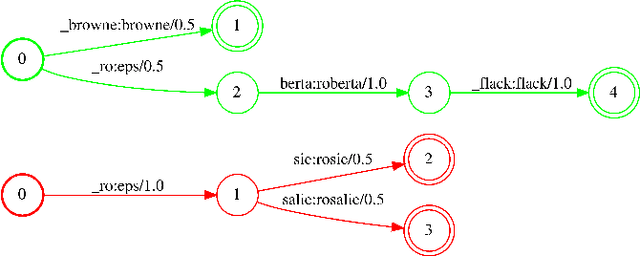
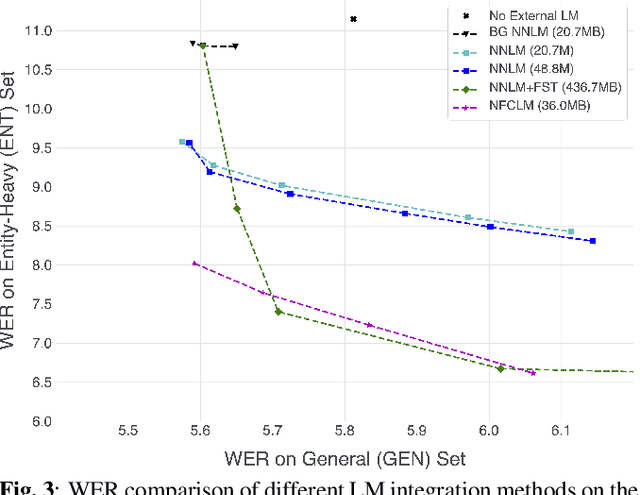
We propose Neural-FST Class Language Model (NFCLM) for end-to-end speech recognition, a novel method that combines neural network language models (NNLMs) and finite state transducers (FSTs) in a mathematically consistent framework. Our method utilizes a background NNLM which models generic background text together with a collection of domain-specific entities modeled as individual FSTs. Each output token is generated by a mixture of these components; the mixture weights are estimated with a separately trained neural decider. We show that NFCLM significantly outperforms NNLM by 15.8% relative in terms of Word Error Rate. NFCLM achieves similar performance as traditional NNLM and FST shallow fusion while being less prone to overbiasing and 12 times more compact, making it more suitable for on-device usage.