 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnca D. Dragan
Learning under Misspecified Objective Spaces
Oct 26, 2018


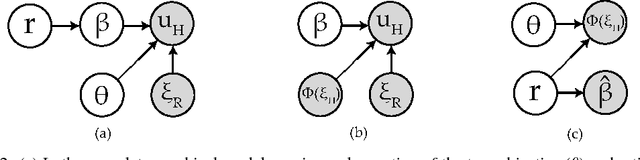
Learning robot objective functions from human input has become increasingly important, but state-of-the-art techniques assume that the human's desired objective lies within the robot's hypothesis space. When this is not true, even methods that keep track of uncertainty over the objective fail because they reason about which hypothesis might be correct, and not whether any of the hypotheses are correct. We focus specifically on learning from physical human corrections during the robot's task execution, where not having a rich enough hypothesis space leads to the robot updating its objective in ways that the person did not actually intend. We observe that such corrections appear irrelevant to the robot, because they are not the best way of achieving any of the candidate objectives. Instead of naively trusting and learning from every human interaction, we propose robots learn conservatively by reasoning in real time about how relevant the human's correction is for the robot's hypothesis space. We test our inference method in an experiment with human interaction data, and demonstrate that this alleviates unintended learning in an in-person user study with a 7DoF robot manipulator.
Where Do You Think You're Going?: Inferring Beliefs about Dynamics from Behavior
Oct 20, 2018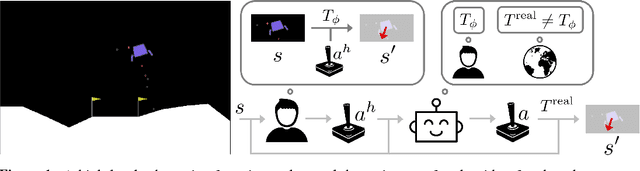

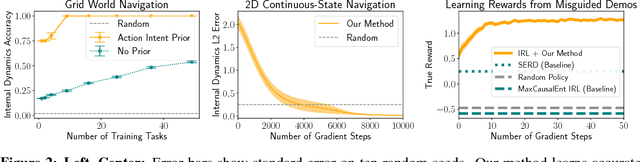
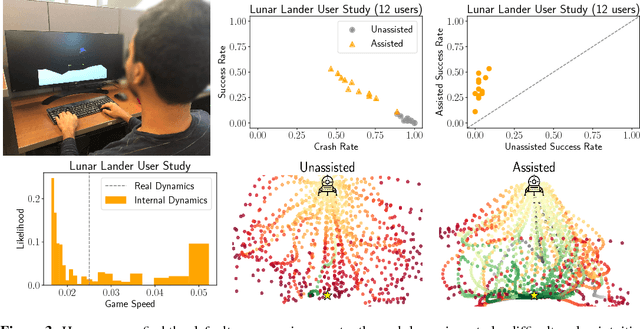
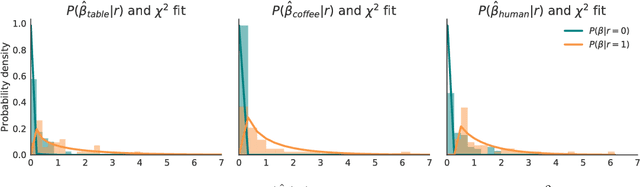
Inferring intent from observed behavior has been studied extensively within the frameworks of Bayesian inverse planning and inverse reinforcement learning. These methods infer a goal or reward function that best explains the actions of the observed agent, typically a human demonstrator. Another agent can use this inferred intent to predict, imitate, or assist the human user. However, a central assumption in inverse reinforcement learning is that the demonstrator is close to optimal. While models of suboptimal behavior exist, they typically assume that suboptimal actions are the result of some type of random noise or a known cognitive bias, like temporal inconsistency. In this paper, we take an alternative approach, and model suboptimal behavior as the result of internal model misspecification: the reason that user actions might deviate from near-optimal actions is that the user has an incorrect set of beliefs about the rules -- the dynamics -- governing how actions affect the environment. Our insight is that while demonstrated actions may be suboptimal in the real world, they may actually be near-optimal with respect to the user's internal model of the dynamics. By estimating these internal beliefs from observed behavior, we arrive at a new method for inferring intent. We demonstrate in simulation and in a user study with 12 participants that this approach enables us to more accurately model human intent, and can be used in a variety of applications, including offering assistance in a shared autonomy framework and inferring human preferences.
Enabling Robots to Communicate their Objectives
Oct 18, 2018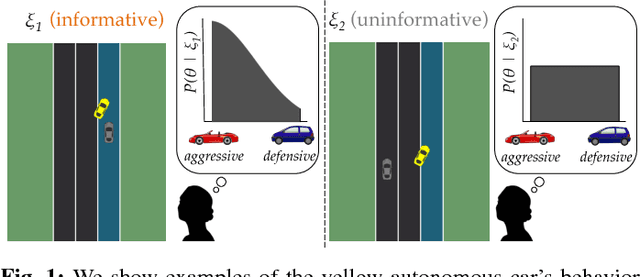

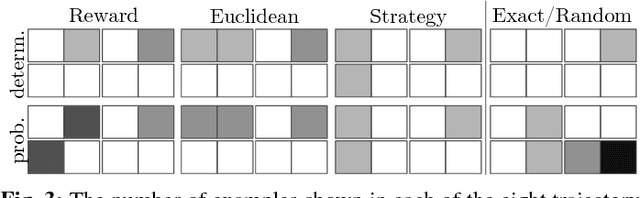
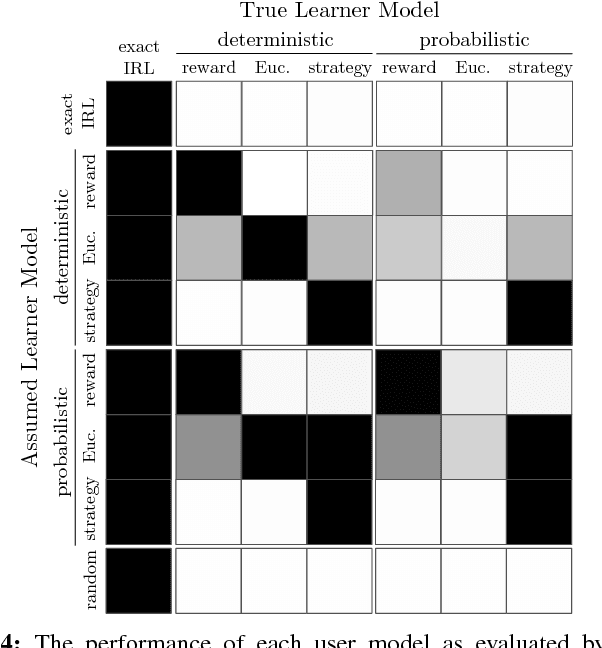
The overarching goal of this work is to efficiently enable end-users to correctly anticipate a robot's behavior in novel situations. Since a robot's behavior is often a direct result of its underlying objective function, our insight is that end-users need to have an accurate mental model of this objective function in order to understand and predict what the robot will do. While people naturally develop such a mental model over time through observing the robot act, this familiarization process may be lengthy. Our approach reduces this time by having the robot model how people infer objectives from observed behavior, and then it selects those behaviors that are maximally informative. The problem of computing a posterior over objectives from observed behavior is known as Inverse Reinforcement Learning (IRL), and has been applied to robots learning human objectives. We consider the problem where the roles of human and robot are swapped. Our main contribution is to recognize that unlike robots, humans will not be exact in their IRL inference. We thus introduce two factors to define candidate approximate-inference models for human learning in this setting, and analyze them in a user study in the autonomous driving domain. We show that certain approximate-inference models lead to the robot generating example behaviors that better enable users to anticipate what it will do in novel situations. Our results also suggest, however, that additional research is needed in modeling how humans extrapolate from examples of robot behavior.
Establishing Appropriate Trust via Critical States
Oct 18, 2018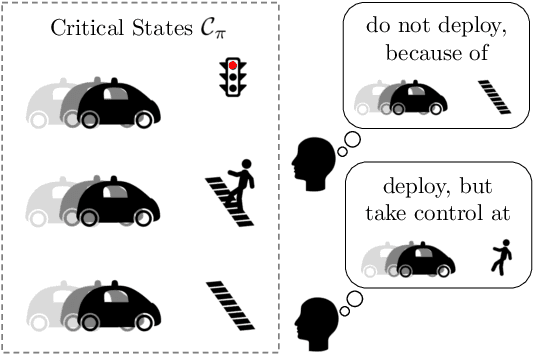
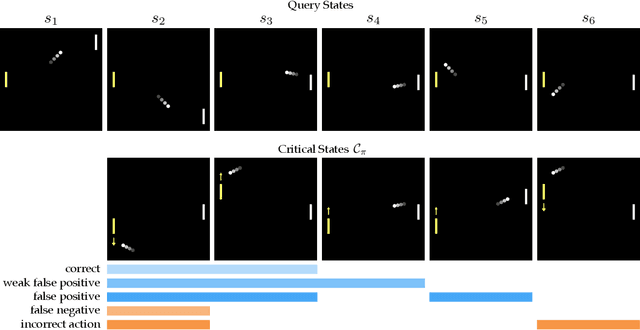
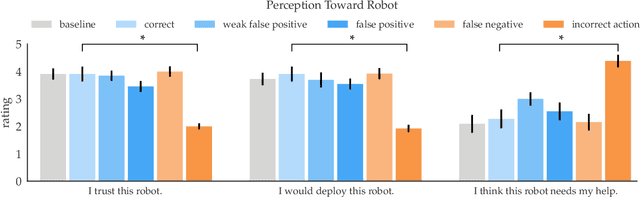
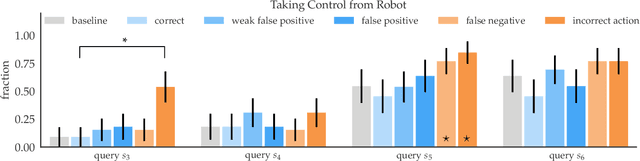
In order to effectively interact with or supervise a robot, humans need to have an accurate mental model of its capabilities and how it acts. Learned neural network policies make that particularly challenging. We propose an approach for helping end-users build a mental model of such policies. Our key observation is that for most tasks, the essence of the policy is captured in a few critical states: states in which it is very important to take a certain action. Our user studies show that if the robot shows a human what its understanding of the task's critical states is, then the human can make a more informed decision about whether to deploy the policy, and if she does deploy it, when she needs to take control from it at execution time.
Expressing Robot Incapability
Oct 18, 2018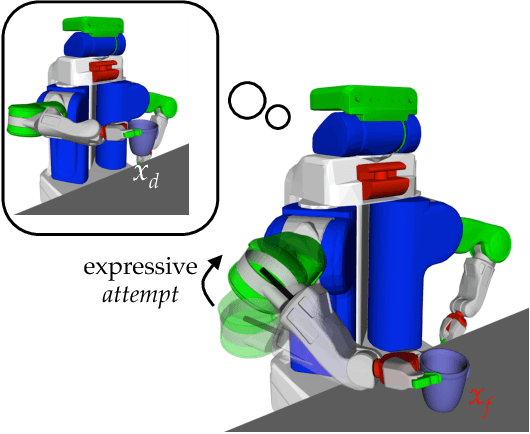
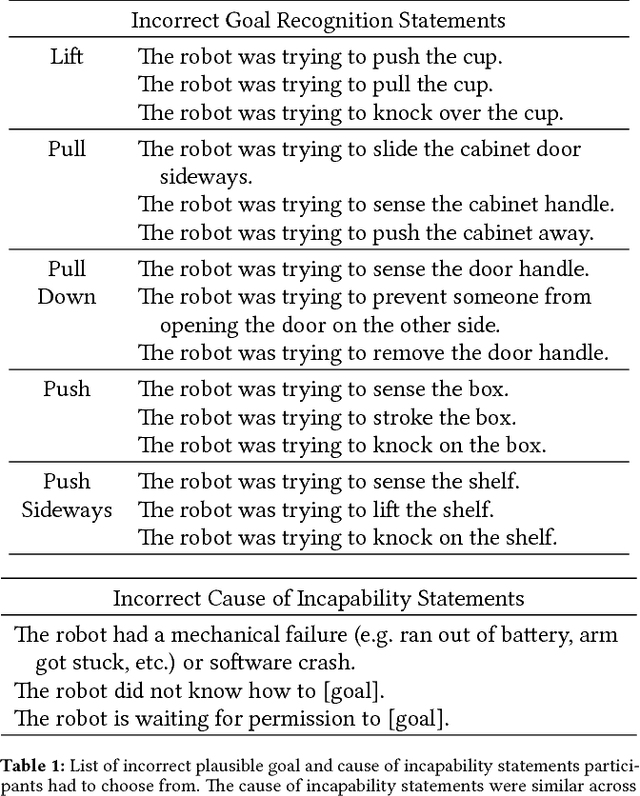
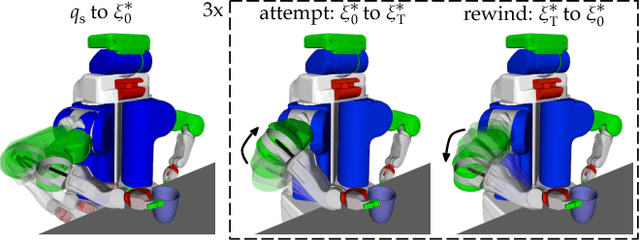
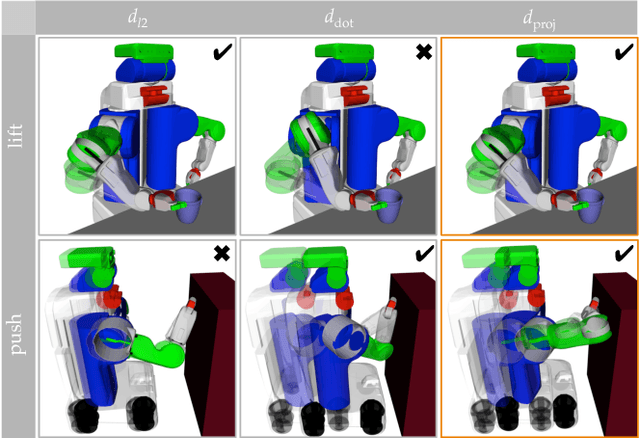
Our goal is to enable robots to express their incapability, and to do so in a way that communicates both what they are trying to accomplish and why they are unable to accomplish it. We frame this as a trajectory optimization problem: maximize the similarity between the motion expressing incapability and what would amount to successful task execution, while obeying the physical limits of the robot. We introduce and evaluate candidate similarity measures, and show that one in particular generalizes to a range of tasks, while producing expressive motions that are tailored to each task. Our user study supports that our approach automatically generates motions expressing incapability that communicate both what and why to end-users, and improve their overall perception of the robot and willingness to collaborate with it in the future.
Hierarchical Game-Theoretic Planning for Autonomous Vehicles
Oct 13, 2018
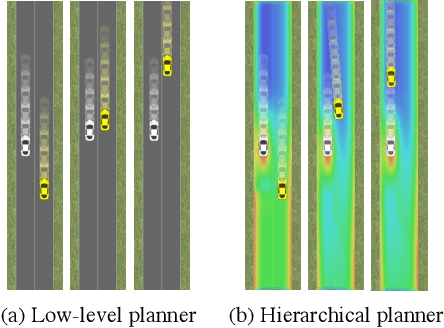
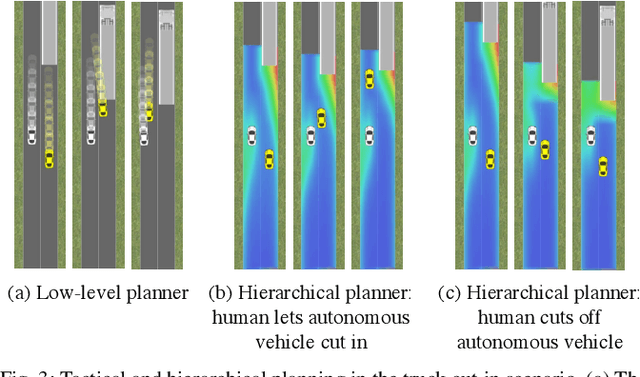
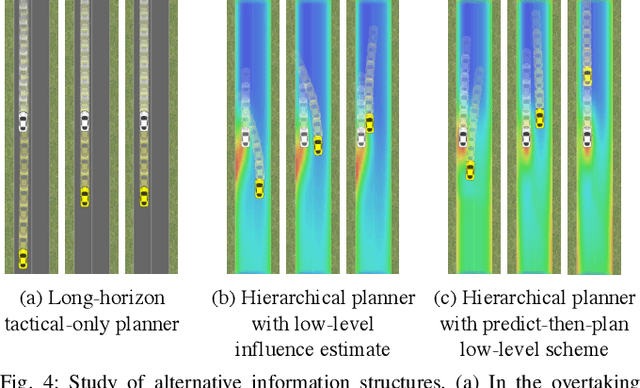
The actions of an autonomous vehicle on the road affect and are affected by those of other drivers, whether overtaking, negotiating a merge, or avoiding an accident. This mutual dependence, best captured by dynamic game theory, creates a strong coupling between the vehicle's planning and its predictions of other drivers' behavior, and constitutes an open problem with direct implications on the safety and viability of autonomous driving technology. Unfortunately, dynamic games are too computationally demanding to meet the real-time constraints of autonomous driving in its continuous state and action space. In this paper, we introduce a novel game-theoretic trajectory planning algorithm for autonomous driving, that enables real-time performance by hierarchically decomposing the underlying dynamic game into a long-horizon "strategic" game with simplified dynamics and full information structure, and a short-horizon "tactical" game with full dynamics and a simplified information structure. The value of the strategic game is used to guide the tactical planning, implicitly extending the planning horizon, pushing the local trajectory optimization closer to global solutions, and, most importantly, quantitatively accounting for the autonomous vehicle and the human driver's ability and incentives to influence each other. In addition, our approach admits non-deterministic models of human decision-making, rather than relying on perfectly rational predictions. Our results showcase richer, safer, and more effective autonomous behavior in comparison to existing techniques.
Cost Functions for Robot Motion Style
Sep 01, 2018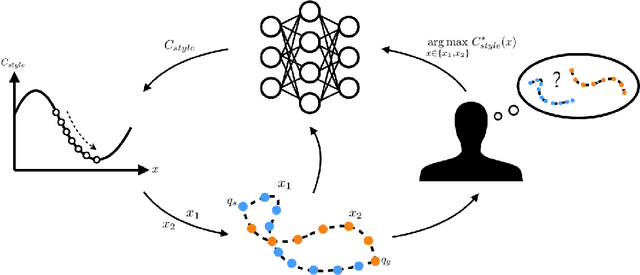
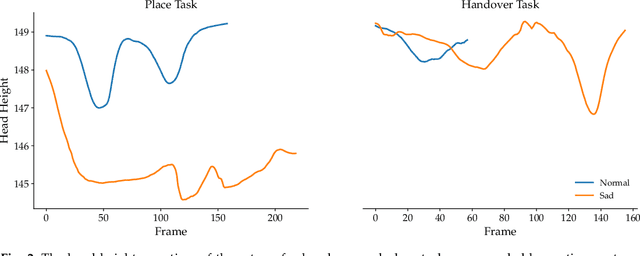
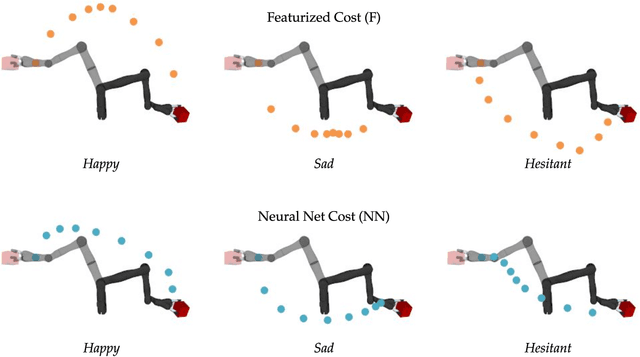

We focus on autonomously generating robot motion for day to day physical tasks that is expressive of a certain style or emotion. Because we seek generalization across task instances and task types, we propose to capture style via cost functions that the robot can use to augment its nominal task cost and task constraints in a trajectory optimization process. We compare two approaches to representing such cost functions: a weighted linear combination of hand-designed features, and a neural network parameterization operating on raw trajectory input. For each cost type, we learn weights for each style from user feedback. We contrast these approaches to a nominal motion across different tasks and for different styles in a user study, and find that they both perform on par with each other, and significantly outperform the baseline. Each approach has its advantages: featurized costs require learning fewer parameters and can perform better on some styles, but neural network representations do not require expert knowledge to design features and could even learn more complex, nuanced costs than an expert can easily design.
Social Cohesion in Autonomous Driving
Aug 27, 2018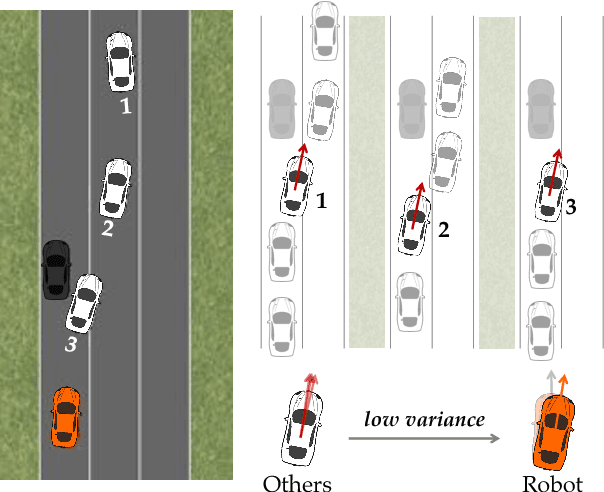

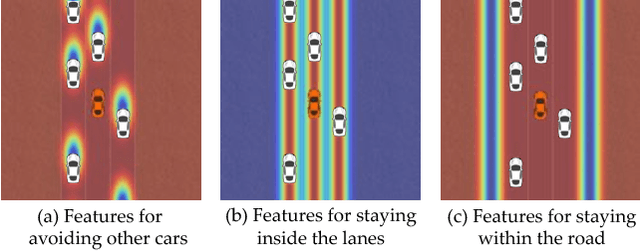
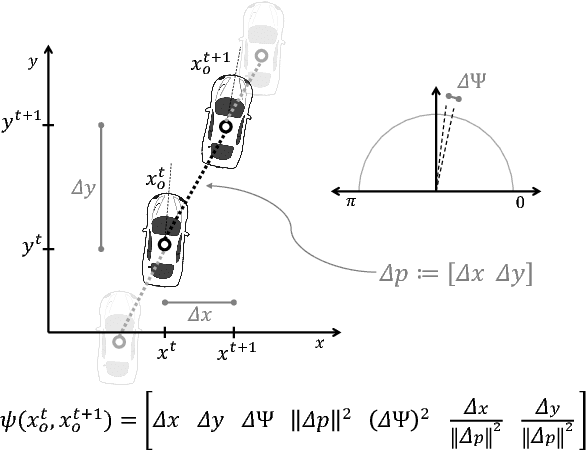
Autonomous cars can perform poorly for many reasons. They may have perception issues, incorrect dynamics models, be unaware of obscure rules of human traffic systems, or follow certain rules too conservatively. Regardless of the exact failure mode of the car, often human drivers around the car are behaving correctly. For example, even if the car does not know that it should pull over when an ambulance races by, other humans on the road will know and will pull over. We propose to make socially cohesive cars that leverage the behavior of nearby human drivers to act in ways that are safer and more socially acceptable. The simple intuition behind our algorithm is that if all the humans are consistently behaving in a particular way, then the autonomous car probably should too. We analyze the performance of our algorithm in a variety of scenarios and conduct a user study to assess people's attitudes towards socially cohesive cars. We find that people are surprisingly tolerant of mistakes that cohesive cars might make in order to get the benefits of driving in a car with a safer, or even just more socially acceptable behavior.
The Social Cost of Strategic Classification
Aug 25, 2018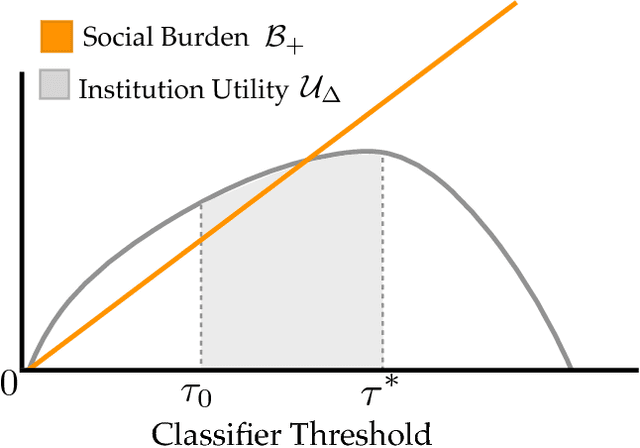
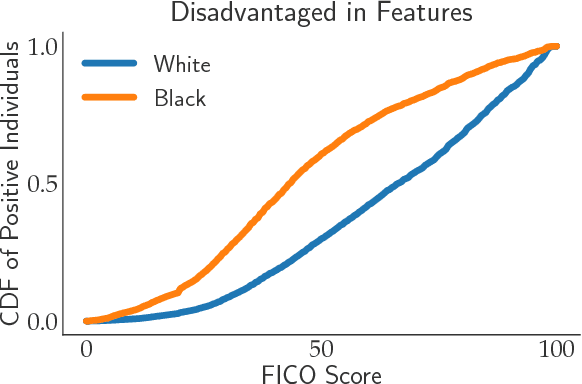
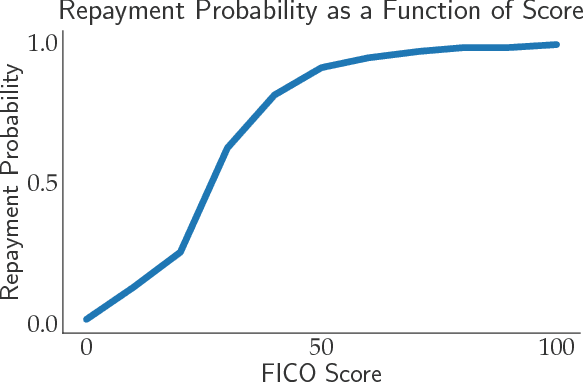
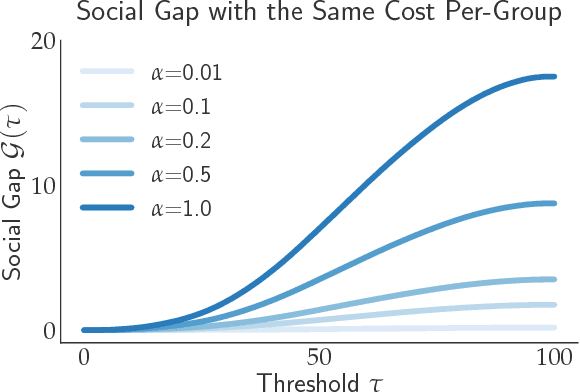
Consequential decision-making typically incentivizes individuals to behave strategically, tailoring their behavior to the specifics of the decision rule. A long line of work has therefore sought to counteract strategic behavior by designing more conservative decision boundaries in an effort to increase robustness to the effects of strategic covariate shift. We show that these efforts benefit the institutional decision maker at the expense of the individuals being classified. Introducing a notion of social burden, we prove that any increase in institutional utility necessarily leads to a corresponding increase in social burden. Moreover, we show that the negative externalities of strategic classification can disproportionately harm disadvantaged groups in the population. Our results highlight that strategy-robustness must be weighed against considerations of social welfare and fairness.
Courteous Autonomous Cars
Aug 16, 2018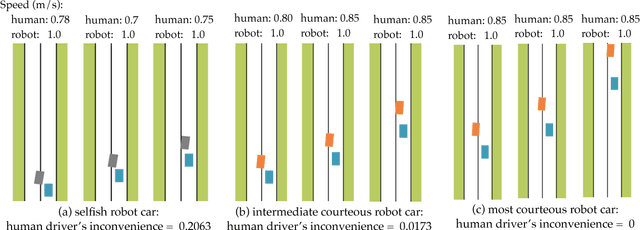

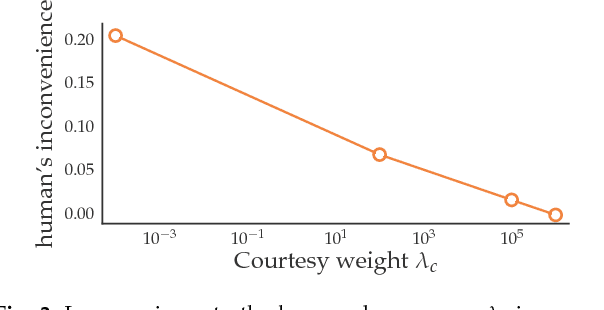
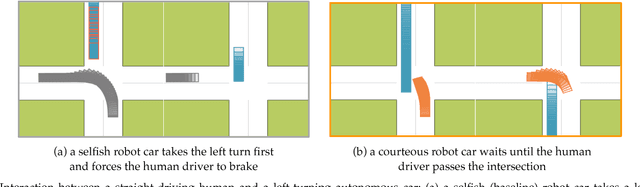
Typically, autonomous cars optimize for a combination of safety, efficiency, and driving quality. But as we get better at this optimization, we start seeing behavior go from too conservative to too aggressive. The car's behavior exposes the incentives we provide in its cost function. In this work, we argue for cars that are not optimizing a purely selfish cost, but also try to be courteous to other interactive drivers. We formalize courtesy as a term in the objective that measures the increase in another driver's cost induced by the autonomous car's behavior. Such a courtesy term enables the robot car to be aware of possible irrationality of the human behavior, and plan accordingly. We analyze the effect of courtesy in a variety of scenarios. We find, for example, that courteous robot cars leave more space when merging in front of a human driver. Moreover, we find that such a courtesy term can help explain real human driver behavior on the NGSIM dataset.