 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Safety: A Descendant of Generative AI and Control Systems Safety
May 16, 2024



Generative artificial intelligence (AI) is interacting with people at an unprecedented scale, offering new avenues for immense positive impact, but also raising widespread concerns around the potential for individual and societal harm. Today, the predominant paradigm for human-AI safety focuses on fine-tuning the generative model's outputs to better agree with human-provided examples or feedback. In reality, however, the consequences of an AI model's outputs cannot be determined in an isolated context: they are tightly entangled with the responses and behavior of human users over time. In this position paper, we argue that meaningful safety assurances for these AI technologies can only be achieved by reasoning about how the feedback loop formed by the AI's outputs and human behavior may drive the interaction towards different outcomes. To this end, we envision a high-value window of opportunity to bridge the rapidly growing capabilities of generative AI and the dynamical safety frameworks from control theory, laying a new foundation for human-centered AI safety in the coming decades.
Gameplay Filters: Safe Robot Walking through Adversarial Imagination
May 01, 2024



Ensuring the safe operation of legged robots in uncertain, novel environments is crucial to their widespread adoption. Despite recent advances in safety filters that can keep arbitrary task-driven policies from incurring safety failures, existing solutions for legged robot locomotion still rely on simplified dynamics and may fail when the robot is perturbed away from predefined stable gaits. This paper presents a general approach that leverages offline game-theoretic reinforcement learning to synthesize a highly robust safety filter for high-order nonlinear dynamics. This gameplay filter then maintains runtime safety by continually simulating adversarial futures and precluding task-driven actions that would cause it to lose future games (and thereby violate safety). Validated on a 36-dimensional quadruped robot locomotion task, the gameplay safety filter exhibits inherent robustness to the sim-to-real gap without manual tuning or heuristic designs. Physical experiments demonstrate the effectiveness of the gameplay safety filter under perturbations, such as tugging and unmodeled irregular terrains, while simulation studies shed light on how to trade off computation and conservativeness without compromising safety.
Who Plays First? Optimizing the Order of Play in Stackelberg Games with Many Robots
Feb 14, 2024



We consider the multi-agent spatial navigation problem of computing the socially optimal order of play, i.e., the sequence in which the agents commit to their decisions, and its associated equilibrium in an N-player Stackelberg trajectory game. We model this problem as a mixed-integer optimization problem over the space of all possible Stackelberg games associated with the order of play's permutations. To solve the problem, we introduce Branch and Play (B&P), an efficient and exact algorithm that provably converges to a socially optimal order of play and its Stackelberg equilibrium. As a subroutine for B&P, we employ and extend sequential trajectory planning, i.e., a popular multi-agent control approach, to scalably compute valid local Stackelberg equilibria for any given order of play. We demonstrate the practical utility of B&P to coordinate air traffic control, swarm formation, and delivery vehicle fleets. We find that B&P consistently outperforms various baselines, and computes the socially optimal equilibrium.
Learning-Aware Safety for Interactive Autonomy
Sep 03, 2023



One of the outstanding challenges for the widespread deployment of robotic systems like autonomous vehicles is ensuring safe interaction with humans without sacrificing efficiency. Existing safety analysis methods often neglect the robot's ability to learn and adapt at runtime, leading to overly conservative behavior. This paper proposes a new closed-loop paradigm for synthesizing safe control policies that explicitly account for the system's evolving uncertainty under possible future scenarios. The formulation reasons jointly about the physical dynamics and the robot's learning algorithm, which updates its internal belief over time. We leverage adversarial deep reinforcement learning (RL) for scaling to high dimensions, enabling tractable safety analysis even for implicit learning dynamics induced by state-of-the-art prediction models. We demonstrate our framework's ability to work with both Bayesian belief propagation and the implicit learning induced by a large pre-trained neural trajectory predictor.
Fast, Smooth, and Safe: Implicit Control Barrier Functions through Reach-Avoid Differential Dynamic Programming
Jul 01, 2023Safety is a central requirement for autonomous system operation across domains. Hamilton-Jacobi (HJ) reachability analysis can be used to construct "least-restrictive" safety filters that result in infrequent, but often extreme, control overrides. In contrast, control barrier function (CBF) methods apply smooth control corrections to guard the system against an often conservative safety boundary. This paper provides an online scheme to construct an implicit CBF through HJ reach-avoid differential dynamic programming in a receding-horizon framework, enabling smooth safety filtering with infinite-time safety guarantees. Simulations with the Dubins car and 5D bicycle dynamics demonstrate the scheme's ability to preserve safety smoothly without the conservativeness of handcrafted CBFs.
Active Uncertainty Reduction for Safe and Efficient Interaction Planning: A Shielding-Aware Dual Control Approach
Feb 01, 2023



The ability to accurately predict the opponent's behavior is central to the safety and efficiency of robotic systems in interactive settings, such as human-robot interaction and multi-robot teaming tasks. Unfortunately, robots often lack access to key information on which these predictions may hinge, such as opponent's goals, attention, and willingness to cooperate. Dual control theory addresses this challenge by treating unknown parameters of a predictive model as hidden states and inferring their values at runtime using information gathered during system operation. While able to optimally and automatically trade off exploration and exploitation, dual control is computationally intractable for general interactive motion planning. In this paper, we present a novel algorithmic approach to enable active uncertainty reduction for interactive motion planning based on the implicit dual control paradigm. Our approach relies on sampling-based approximation of stochastic dynamic programming, leading to a model predictive control problem. The resulting policy is shown to preserve the dual control effect for a broad class of predictive models with both continuous and categorical uncertainty. To ensure the safe operation of the interacting agents, we leverage a supervisory control scheme, oftentimes referred to as ``shielding'', which overrides the ego agent's dual control policy with a safety fallback strategy when a safety-critical event is imminent. We then augment the dual control framework with an improved variant of the recently proposed shielding-aware robust planning scheme, which proactively balances the nominal planning performance with the risk of high-cost emergency maneuvers triggered by low-probability opponent's behaviors. We demonstrate the efficacy of our approach with both simulated driving examples and hardware experiments using 1/10 scale autonomous vehicles.
Active Uncertainty Learning for Human-Robot Interaction: An Implicit Dual Control Approach
Feb 15, 2022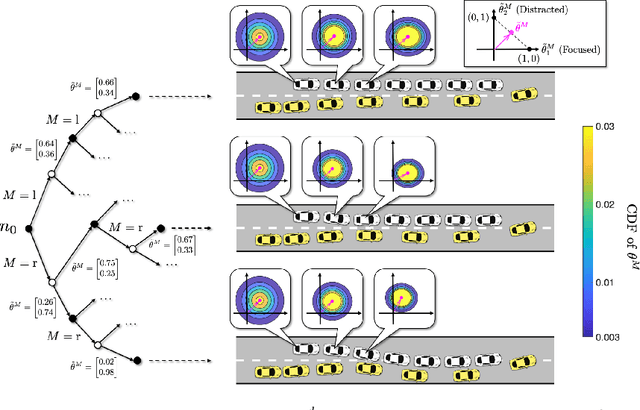
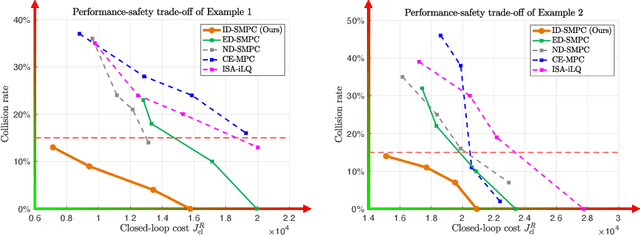
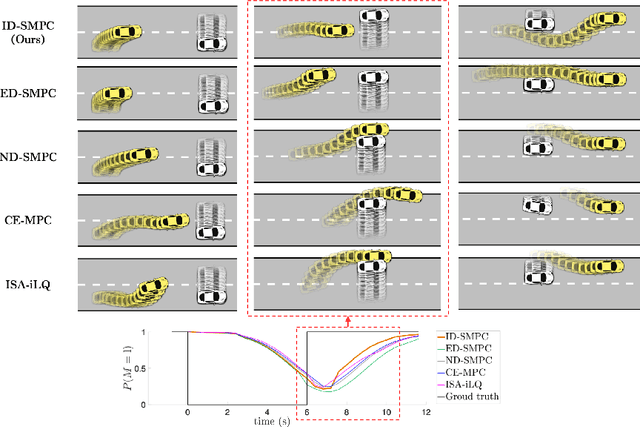

Predictive models are effective in reasoning about human motion, a crucial part that affects safety and efficiency in human-robot interaction. However, robots often lack access to certain key parameters of such models, for example, human's objectives, their level of distraction, and willingness to cooperate. Dual control theory addresses this challenge by treating unknown parameters as stochastic hidden states and identifying their values using information gathered during control of the robot. Despite its ability to optimally and automatically trade off exploration and exploitation, dual control is computationally intractable for general human-in-the-loop motion planning, mainly due to nested trajectory optimization and human intent prediction. In this paper, we present a novel algorithmic approach to enable active uncertainty learning for human-in-the-loop motion planning based on the implicit dual control paradigm. Our approach relies on sampling-based approximation of stochastic dynamic programming, leading to a model predictive control problem that can be readily solved by real-time gradient-based optimization methods. The resulting policy is shown to preserve the dual control effect for generic human predictive models with both continuous and categorical uncertainty. The efficacy of our approach is demonstrated with simulated driving examples.
Sim-to-Lab-to-Real: Safe Reinforcement Learning with Shielding and Generalization Guarantees
Feb 10, 2022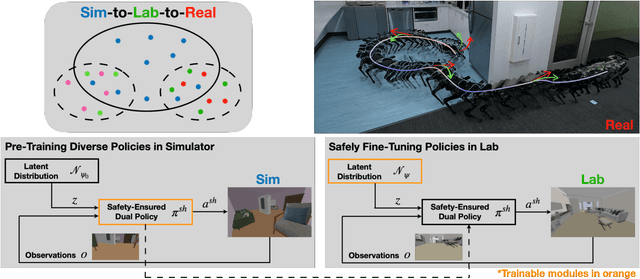

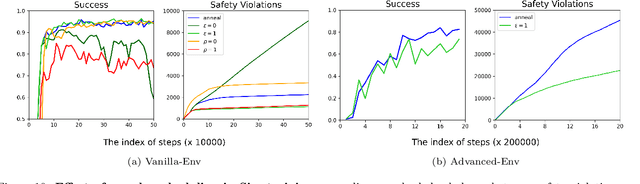
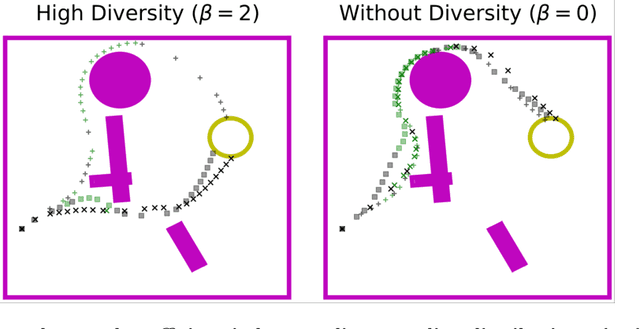
Safety is a critical component of autonomous systems and remains a challenge for learning-based policies to be utilized in the real world. In particular, policies learned using reinforcement learning often fail to generalize to novel environments due to unsafe behavior. In this paper, we propose Sim-to-Lab-to-Real to safely close the reality gap. To improve safety, we apply a dual policy setup where a performance policy is trained using the cumulative task reward and a backup (safety) policy is trained by solving the reach-avoid Bellman Equation based on Hamilton-Jacobi reachability analysis. In Sim-to-Lab transfer, we apply a supervisory control scheme to shield unsafe actions during exploration; in Lab-to-Real transfer, we leverage the Probably Approximately Correct (PAC)-Bayes framework to provide lower bounds on the expected performance and safety of policies in unseen environments. We empirically study the proposed framework for ego-vision navigation in two types of indoor environments including a photo-realistic one. We also demonstrate strong generalization performance through hardware experiments in real indoor spaces with a quadrupedal robot. See https://sites.google.com/princeton.edu/sim-to-lab-to-real for supplementary material.
ProBF: Learning Probabilistic Safety Certificates with Barrier Functions
Dec 24, 2021
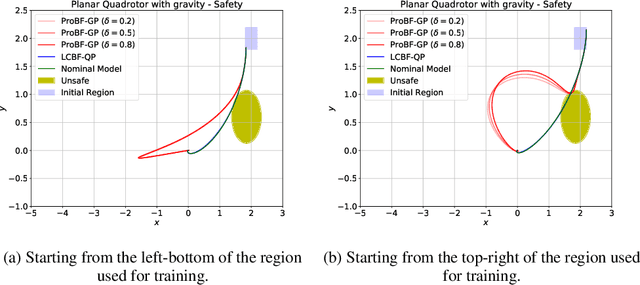
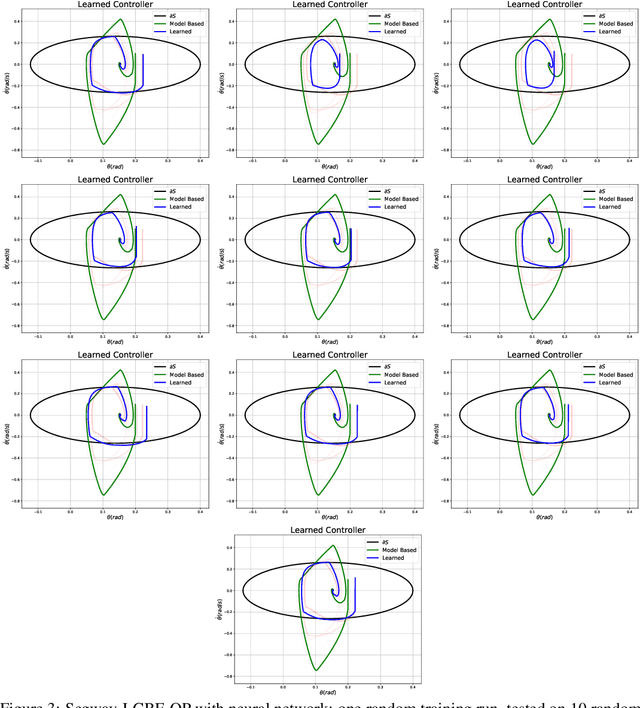
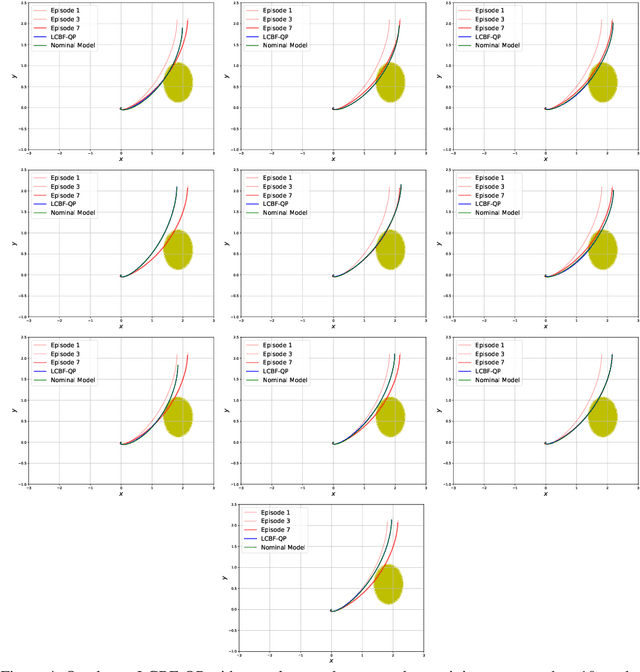
Safety-critical applications require controllers/policies that can guarantee safety with high confidence. The control barrier function is a useful tool to guarantee safety if we have access to the ground-truth system dynamics. In practice, we have inaccurate knowledge of the system dynamics, which can lead to unsafe behaviors due to unmodeled residual dynamics. Learning the residual dynamics with deterministic machine learning models can prevent the unsafe behavior but can fail when the predictions are imperfect. In this situation, a probabilistic learning method that reasons about the uncertainty of its predictions can help provide robust safety margins. In this work, we use a Gaussian process to model the projection of the residual dynamics onto a control barrier function. We propose a novel optimization procedure to generate safe controls that can guarantee safety with high probability. The safety filter is provided with the ability to reason about the uncertainty of the predictions from the GP. We show the efficacy of this method through experiments on Segway and Quadrotor simulations. Our proposed probabilistic approach is able to reduce the number of safety violations significantly as compared to the deterministic approach with a neural network.
Safety and Liveness Guarantees through Reach-Avoid Reinforcement Learning
Dec 23, 2021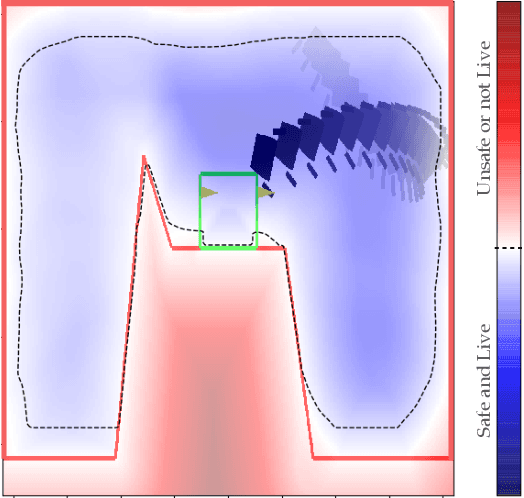
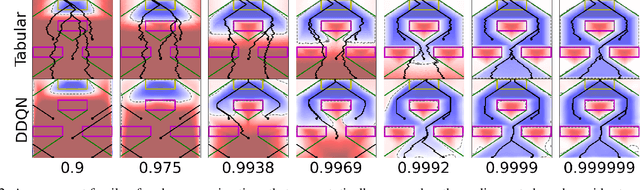
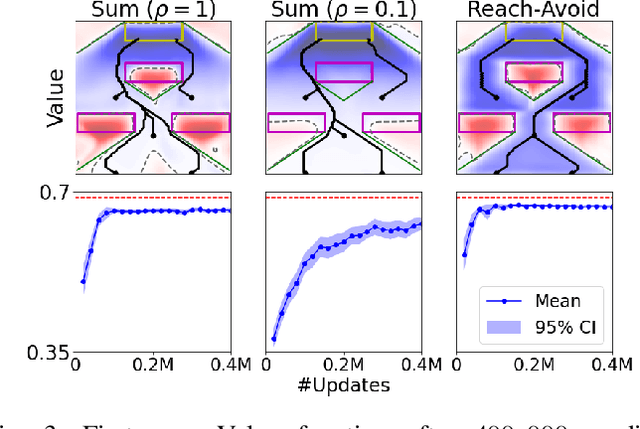
Reach-avoid optimal control problems, in which the system must reach certain goal conditions while staying clear of unacceptable failure modes, are central to safety and liveness assurance for autonomous robotic systems, but their exact solutions are intractable for complex dynamics and environments. Recent successes in reinforcement learning methods to approximately solve optimal control problems with performance objectives make their application to certification problems attractive; however, the Lagrange-type objective used in reinforcement learning is not suitable to encode temporal logic requirements. Recent work has shown promise in extending the reinforcement learning machinery to safety-type problems, whose objective is not a sum, but a minimum (or maximum) over time. In this work, we generalize the reinforcement learning formulation to handle all optimal control problems in the reach-avoid category. We derive a time-discounted reach-avoid Bellman backup with contraction mapping properties and prove that the resulting reach-avoid Q-learning algorithm converges under analogous conditions to the traditional Lagrange-type problem, yielding an arbitrarily tight conservative approximation to the reach-avoid set. We further demonstrate the use of this formulation with deep reinforcement learning methods, retaining zero-violation guarantees by treating the approximate solutions as untrusted oracles in a model-predictive supervisory control framework. We evaluate our proposed framework on a range of nonlinear systems, validating the results against analytic and numerical solutions, and through Monte Carlo simulation in previously intractable problems. Our results open the door to a range of learning-based methods for safe-and-live autonomous behavior, with applications across robotics and automation. See https://github.com/SafeRoboticsLab/safety_rl for code and supplementary material.