 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning under Misspecified Objective Spaces
Paper and Code


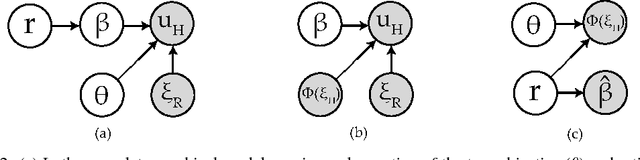
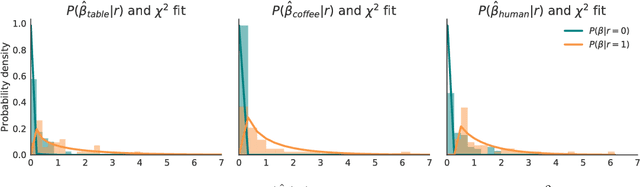
Learning robot objective functions from human input has become increasingly important, but state-of-the-art techniques assume that the human's desired objective lies within the robot's hypothesis space. When this is not true, even methods that keep track of uncertainty over the objective fail because they reason about which hypothesis might be correct, and not whether any of the hypotheses are correct. We focus specifically on learning from physical human corrections during the robot's task execution, where not having a rich enough hypothesis space leads to the robot updating its objective in ways that the person did not actually intend. We observe that such corrections appear irrelevant to the robot, because they are not the best way of achieving any of the candidate objectives. Instead of naively trusting and learning from every human interaction, we propose robots learn conservatively by reasoning in real time about how relevant the human's correction is for the robot's hypothesis space. We test our inference method in an experiment with human interaction data, and demonstrate that this alleviates unintended learning in an in-person user study with a 7DoF robot manipulator.