 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyAlign: Conditional Human-Distribution Alignment
Jun 11, 2026Post-training methods such as supervised fine-tuning (SFT) and preference optimization typically align language models toward a single global assistant behavior. While effective for improving average helpfulness, this can suppress the natural variation of human responses across languages, tasks, and dialogue settings. We study this problem as conditional human-distribution alignment: models should match the human response distribution appropriate to the current interaction context, rather than a universal response style. We introduce PolyAlign, a distribution-aware alignment framework that organizes bilingual interaction data into bucket-specific human reference distributions defined by language, interaction track, response family, and length. PolyAlign combines Bucket-Aware SFT, which balances optimization across heterogeneous buckets, with Human-Distribution Preference Optimization (HDPO), which regularizes preference learning using critic-estimated distance to bucket-specific human support. Across a bilingual evaluation suite covering English and Chinese single- and multi-turn settings, PolyAlign improves conditional naturalness and distributional faithfulness while preserving competitive task utility. The results suggest that post-training should move beyond global alignment objectives toward interaction-aware alignment with human response distributions.
Counterfactual Reasoning for Fine-Grained Evidence Disentanglement in VideoQA
Jun 08, 2026Recent advances in video multimodal models have significantly improved VideoQA performance. However, these systems often rely on spurious statistical correlations rather than answer-relevant causal evidence, resulting in unfaithful and brittle reasoning, especially in complex real-world scenarios. Existing methods either rely on cross-modality correlations, costly curated training resources, or insufficient causal assumptions and constraints, and typically operate at the time-interval level. As a result, they fail to explicitly disentangle causal visual cues from confounders and provide limited fine-grained evidence localization. To address this issue, we propose a Counterfactual Reasoning framework for fine-grained Evidence Disentanglement (CREDiT). CREDiT formulates the VideoQA process using a structural causal model and learns cross-modality representations that are explicitly decomposed into causal and non-causal components under independence and minimality constraints. To facilitate faithful disentanglement, we introduce feature-level causal interventions and construct counterfactual inputs that approximate causal effects while suppressing non-causal correlations. Extensive experiments on NExT-GQA, SportsQA, and SPORTU-video demonstrate that CREDiT consistently improves answer accuracy and reasoning reliability across both generic and complex sports scenarios, leading to more trustworthy VideoQA systems.
Disentanglement-Based Equivariant Learning for Compositional VQA
Jun 01, 2026Compositional visual question answering (VQA) represents a challenging yet fundamental task that requires models to comprehend novel combinations of previously learned concepts. The current methods often overlook the disentanglement of underlying concepts and are restricted in terms of their ability to effectively capture the compositional variation mechanism. Moreover, the state-of-the-art techniques depend on additional clues for training, which is not feasible in real-world VQA scenarios. To address these issues, in this paper, we introduce a novel Disentanglement-based EquivAriant Learning (DEAL) framework for compositional VQA, which is guided exclusively by ground-truth answers. In DEAL, we employ causality-inspired interventions to disentangle concepts derived from visual and textual inputs within a re-encoding framework. Based on the principle of equivariance, we subsequently perform a compositional transformation on the inference input and impose the equivariant constraint on the output to augment the compositional reasoning capacity of the model. Comprehensive experiments conducted on the benchmark CLEVR-CoGenT and GQA-SGL datasets validate the superiority of our proposed DEAL approach over the existing state-of-the-art methods for compositional VQA tasks in both visual and linguistic generalization settings.
* Accepted by IEEE Transactions on Multimedia
FedCoE: Bridging Generalization and Personalization via Federated Coordinated Dual-level MoEs
May 20, 2026Federated Learning (FL) has emerged as a promising paradigm for privacy-preserving distributed learning. However, existing FL methods face a fundamental challenge. Traditional averaging-based approaches suffer from parameter divergence under non-IID conditions, while personalized FL methods overfit to local data and fail to generalize to new clients (cold-start problem). Mixture-of-Experts naturally addresses this by routing heterogeneous data to specialized experts rather than forcing uniform aggregation. In this paper, we propose FedCoE, a Federated Coordinated dual-level mixture-of-Experts framework that effectively balances global generalization with local personalization. FedCoE maintains multiple independent global expert models on the server and employs a shared gating network to dynamically model client-expert correlations during aggregation, effectively mitigating expert drift and gating inconsistency. To address the cold-start challenge, we introduce an adaptive mechanism that enables new clients to immediately leverage the global expert pool without extensive local training. Extensive experiments demonstrate that FedCoE achieves 78.00% global accuracy and 89.32% personalized accuracy on average, outperforming the baseline by 8.82% and 29.19%, respectively. In cold-start scenarios, FedCoE delivers 77.27% accuracy without any local fine-tuning, outperforming baselines by over 12.54%.
AutoMCU: Feasibility-First MCU Neural Network Customization via LLM-based Multi-Agent Systems
May 20, 2026Deploying neural networks on microcontroller units (MCUs) is critical for edge intelligence but remains challenging due to tight memory, storage, and computation constraints. Existing approaches, such as model compression and hardware-aware neural architecture search (HW-NAS), often depend on proxy metrics, incur high search cost, and do not fully bridge the gap between architecture design and verified deployment. This paper presents AutoMCU, a feasibility-first large language model (LLM)-based multi-agent system for automated neural network customization under MCU constraints. Given natural-language task requirements and hardware specifications, AutoMCU iteratively generates structured architecture candidates, filters infeasible designs through vendor toolchain feedback before training, evaluates feasible models under a controlled protocol, and verifies deployability through backend-grounded deployment analysis. AutoMCU includes two key mechanisms: 1) hardware-in-the-loop architecture generation for early elimination of undeployable candidates under RAM and Flash constraints, and 2) state-isolated multi-agent scheduling for stable coordination of proposal, training, evaluation, and deployment stages. Experiments on CIFAR-10 and CIFAR-100 under strict MCU constraints show that AutoMCU achieves competitive accuracy while reducing customization time to about 1--2 hours, compared with hundreds of GPU hours for representative MCU-oriented HW-NAS baselines. Comparisons with ColabNAS and the LLM-based NAS method GENIUS on NAS-Bench-201 further demonstrate the effectiveness and stability of AutoMCU. Real-device deployments on multiple STM32 microcontrollers validate its practical applicability to MCU-scale edge intelligence.
InfoCom: Kilobyte-Scale Communication-Efficient Collaborative Perception with Information Bottleneck
Dec 11, 2025Precise environmental perception is critical for the reliability of autonomous driving systems. While collaborative perception mitigates the limitations of single-agent perception through information sharing, it encounters a fundamental communication-performance trade-off. Existing communication-efficient approaches typically assume MB-level data transmission per collaboration, which may fail due to practical network constraints. To address these issues, we propose InfoCom, an information-aware framework establishing the pioneering theoretical foundation for communication-efficient collaborative perception via extended Information Bottleneck principles. Departing from mainstream feature manipulation, InfoCom introduces a novel information purification paradigm that theoretically optimizes the extraction of minimal sufficient task-critical information under Information Bottleneck constraints. Its core innovations include: i) An Information-Aware Encoding condensing features into minimal messages while preserving perception-relevant information; ii) A Sparse Mask Generation identifying spatial cues with negligible communication cost; and iii) A Multi-Scale Decoding that progressively recovers perceptual information through mask-guided mechanisms rather than simple feature reconstruction. Comprehensive experiments across multiple datasets demonstrate that InfoCom achieves near-lossless perception while reducing communication overhead from megabyte to kilobyte-scale, representing 440-fold and 90-fold reductions per agent compared to Where2comm and ERMVP, respectively.
A Knowledge-driven Adaptive Collaboration of LLMs for Enhancing Medical Decision-making
Sep 18, 2025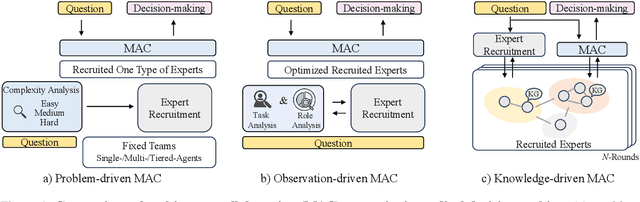
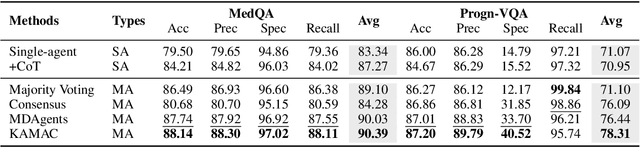
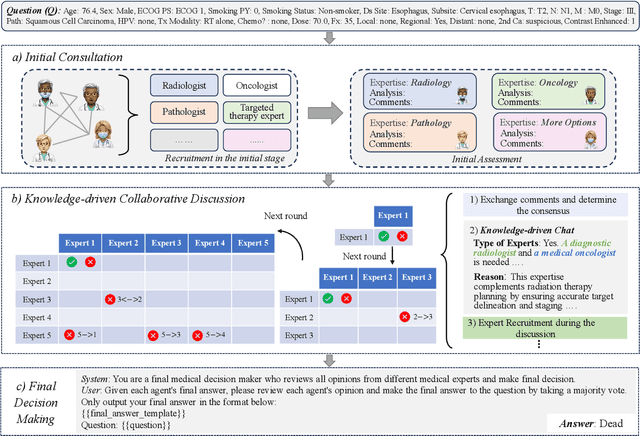
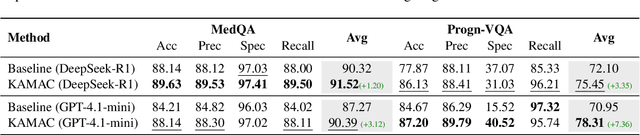
Medical decision-making often involves integrating knowledge from multiple clinical specialties, typically achieved through multidisciplinary teams. Inspired by this collaborative process, recent work has leveraged large language models (LLMs) in multi-agent collaboration frameworks to emulate expert teamwork. While these approaches improve reasoning through agent interaction, they are limited by static, pre-assigned roles, which hinder adaptability and dynamic knowledge integration. To address these limitations, we propose KAMAC, a Knowledge-driven Adaptive Multi-Agent Collaboration framework that enables LLM agents to dynamically form and expand expert teams based on the evolving diagnostic context. KAMAC begins with one or more expert agents and then conducts a knowledge-driven discussion to identify and fill knowledge gaps by recruiting additional specialists as needed. This supports flexible, scalable collaboration in complex clinical scenarios, with decisions finalized through reviewing updated agent comments. Experiments on two real-world medical benchmarks demonstrate that KAMAC significantly outperforms both single-agent and advanced multi-agent methods, particularly in complex clinical scenarios (i.e., cancer prognosis) requiring dynamic, cross-specialty expertise. Our code is publicly available at: https://github.com/XiaoXiao-Woo/KAMAC.
Adaptive Confidence-Wise Loss for Improved Lens Structure Segmentation in AS-OCT
Aug 12, 2025Precise lens structure segmentation is essential for the design of intraocular lenses (IOLs) in cataract surgery. Existing deep segmentation networks typically weight all pixels equally under cross-entropy (CE) loss, overlooking the fact that sub-regions of lens structures are inhomogeneous (e.g., some regions perform better than others) and that boundary regions often suffer from poor segmentation calibration at the pixel level. Clinically, experts annotate different sub-regions of lens structures with varying confidence levels, considering factors such as sub-region proportions, ambiguous boundaries, and lens structure shapes. Motivated by this observation, we propose an Adaptive Confidence-Wise (ACW) loss to group each lens structure sub-region into different confidence sub-regions via a confidence threshold from the unique region aspect, aiming to exploit the potential of expert annotation confidence prior. Specifically, ACW clusters each target region into low-confidence and high-confidence groups and then applies a region-weighted loss to reweigh each confidence group. Moreover, we design an adaptive confidence threshold optimization algorithm to adjust the confidence threshold of ACW dynamically. Additionally, to better quantify the miscalibration errors in boundary region segmentation, we propose a new metric, termed Boundary Expected Calibration Error (BECE). Extensive experiments on a clinical lens structure AS-OCT dataset and other multi-structure datasets demonstrate that our ACW significantly outperforms competitive segmentation loss methods across different deep segmentation networks (e.g., MedSAM). Notably, our method surpasses CE with 6.13% IoU gain, 4.33% DSC increase, and 4.79% BECE reduction in lens structure segmentation under U-Net. The code of this paper is available at https://github.com/XiaoLing12138/Adaptive-Confidence-Wise-Loss.
Expert-Like Reparameterization of Heterogeneous Pyramid Receptive Fields in Efficient CNNs for Fair Medical Image Classification
May 19, 2025Efficient convolutional neural network (CNN) architecture designs have attracted growing research interests. However, they usually apply single receptive field (RF), small asymmetric RFs, or pyramid RFs to learn different feature representations, still encountering two significant challenges in medical image classification tasks: 1) They have limitations in capturing diverse lesion characteristics efficiently, e.g., tiny, coordination, small and salient, which have unique roles on results, especially imbalanced medical image classification. 2) The predictions generated by those CNNs are often unfair/biased, bringing a high risk by employing them to real-world medical diagnosis conditions. To tackle these issues, we develop a new concept, Expert-Like Reparameterization of Heterogeneous Pyramid Receptive Fields (ERoHPRF), to simultaneously boost medical image classification performance and fairness. This concept aims to mimic the multi-expert consultation mode by applying the well-designed heterogeneous pyramid RF bags to capture different lesion characteristics effectively via convolution operations with multiple heterogeneous kernel sizes. Additionally, ERoHPRF introduces an expert-like structural reparameterization technique to merge its parameters with the two-stage strategy, ensuring competitive computation cost and inference speed through comparisons to a single RF. To manifest the effectiveness and generalization ability of ERoHPRF, we incorporate it into mainstream efficient CNN architectures. The extensive experiments show that our method maintains a better trade-off than state-of-the-art methods in terms of medical image classification, fairness, and computation overhead. The codes of this paper will be released soon.
CAST: Time-Varying Treatment Effects with Application to Chemotherapy and Radiotherapy on Head and Neck Squamous Cell Carcinoma
May 09, 2025Causal machine learning (CML) enables individualized estimation of treatment effects, offering critical advantages over traditional correlation-based methods. However, existing approaches for medical survival data with censoring such as causal survival forests estimate effects at fixed time points, limiting their ability to capture dynamic changes over time. We introduce Causal Analysis for Survival Trajectories (CAST), a novel framework that models treatment effects as continuous functions of time following treatment. By combining parametric and non-parametric methods, CAST overcomes the limitations of discrete time-point analysis to estimate continuous effect trajectories. Using the RADCURE dataset [1] of 2,651 patients with head and neck squamous cell carcinoma (HNSCC) as a clinically relevant example, CAST models how chemotherapy and radiotherapy effects evolve over time at the population and individual levels. By capturing the temporal dynamics of treatment response, CAST reveals how treatment effects rise, peak, and decline over the follow-up period, helping clinicians determine when and for whom treatment benefits are maximized. This framework advances the application of CML to personalized care in HNSCC and other life-threatening medical conditions. Source code/data available at: https://github.com/CAST-FW/HNSCC