 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Transfer via Semantic Skill Imitation
Dec 14, 2022



We propose an approach for semantic imitation, which uses demonstrations from a source domain, e.g. human videos, to accelerate reinforcement learning (RL) in a different target domain, e.g. a robotic manipulator in a simulated kitchen. Instead of imitating low-level actions like joint velocities, our approach imitates the sequence of demonstrated semantic skills like "opening the microwave" or "turning on the stove". This allows us to transfer demonstrations across environments (e.g. real-world to simulated kitchen) and agent embodiments (e.g. bimanual human demonstration to robotic arm). We evaluate on three challenging cross-domain learning problems and match the performance of demonstration-accelerated RL approaches that require in-domain demonstrations. In a simulated kitchen environment, our approach learns long-horizon robot manipulation tasks, using less than 3 minutes of human video demonstrations from a real-world kitchen. This enables scaling robot learning via the reuse of demonstrations, e.g. collected as human videos, for learning in any number of target domains.
* Project website: https://kpertsch.github.io/star
Rethinking Sim2Real: Lower Fidelity Simulation Leads to Higher Sim2Real Transfer in Navigation
Jul 21, 2022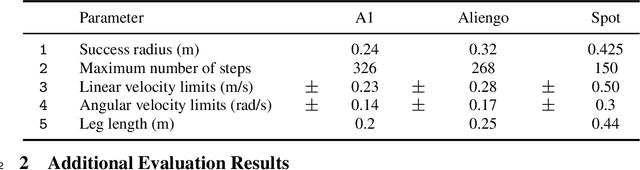
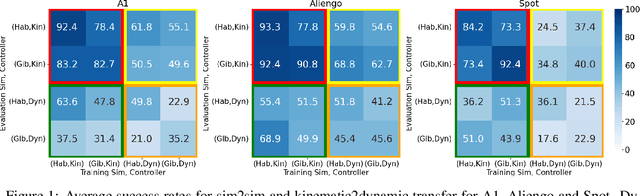


If we want to train robots in simulation before deploying them in reality, it seems natural and almost self-evident to presume that reducing the sim2real gap involves creating simulators of increasing fidelity (since reality is what it is). We challenge this assumption and present a contrary hypothesis -- sim2real transfer of robots may be improved with lower (not higher) fidelity simulation. We conduct a systematic large-scale evaluation of this hypothesis on the problem of visual navigation -- in the real world, and on 2 different simulators (Habitat and iGibson) using 3 different robots (A1, AlienGo, Spot). Our results show that, contrary to expectation, adding fidelity does not help with learning; performance is poor due to slow simulation speed (preventing large-scale learning) and overfitting to inaccuracies in simulation physics. Instead, building simple models of the robot motion using real-world data can improve learning and generalization.
Transformers are Adaptable Task Planners
Jul 06, 2022
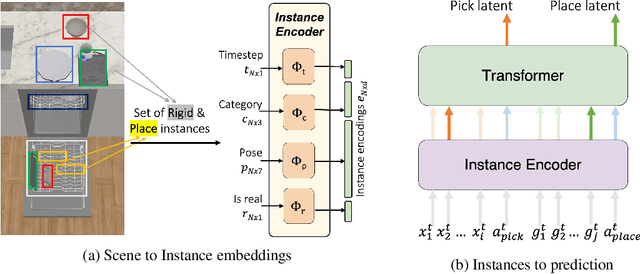
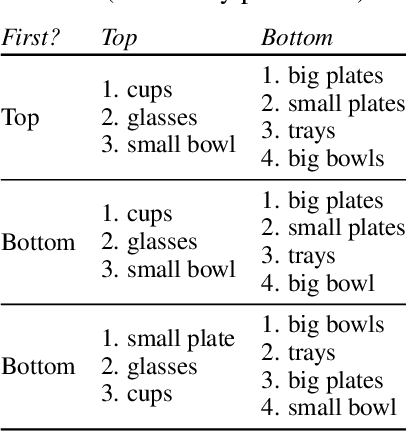
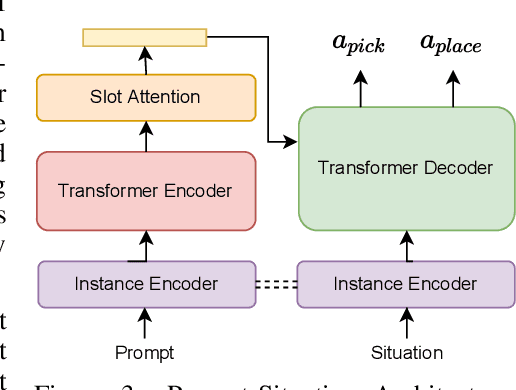
Every home is different, and every person likes things done in their particular way. Therefore, home robots of the future need to both reason about the sequential nature of day-to-day tasks and generalize to user's preferences. To this end, we propose a Transformer Task Planner(TTP) that learns high-level actions from demonstrations by leveraging object attribute-based representations. TTP can be pre-trained on multiple preferences and shows generalization to unseen preferences using a single demonstration as a prompt in a simulated dishwasher loading task. Further, we demonstrate real-world dish rearrangement using TTP with a Franka Panda robotic arm, prompted using a single human demonstration.
Collaborative Navigation and Manipulation of a Cable-towed Load by Multiple Quadrupedal Robots
Jun 29, 2022
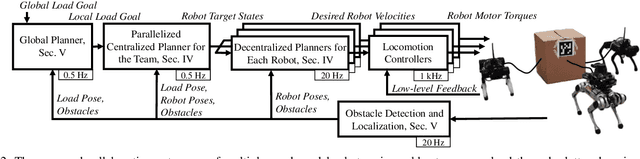
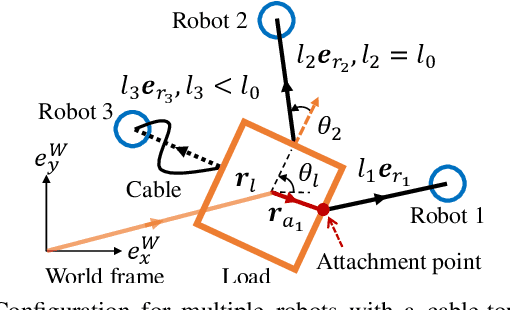
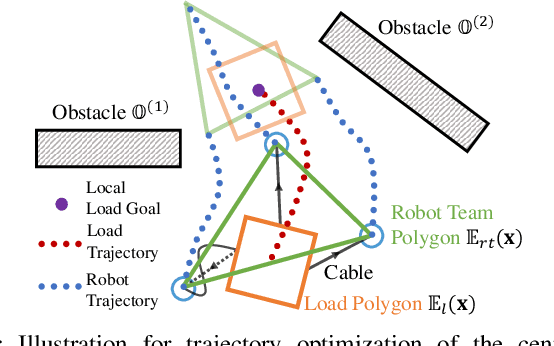
This paper tackles the problem of robots collaboratively towing a load with cables to a specified goal location while avoiding collisions in real time. The introduction of cables (as opposed to rigid links) enables the robotic team to travel through narrow spaces by changing its intrinsic dimensions through slack/taut switches of the cable. However, this is a challenging problem because of the hybrid mode switches and the dynamical coupling among multiple robots and the load. Previous attempts at addressing such a problem were performed offline and do not consider avoiding obstacles online. In this paper, we introduce a cascaded planning scheme with a parallelized centralized trajectory optimization that deals with hybrid mode switches. We additionally develop a set of decentralized planners per robot, which enables our approach to solve the problem of collaborative load manipulation online. We develop and demonstrate one of the first collaborative autonomy framework that is able to move a cable-towed load, which is too heavy to move by a single robot, through narrow spaces with real-time feedback and reactive planning in experiments.
Learning Torque Control for Quadrupedal Locomotion
Mar 10, 2022
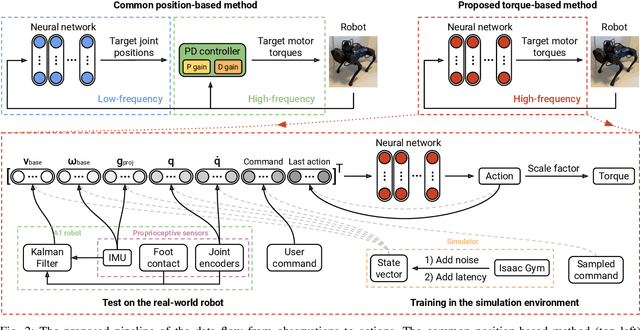

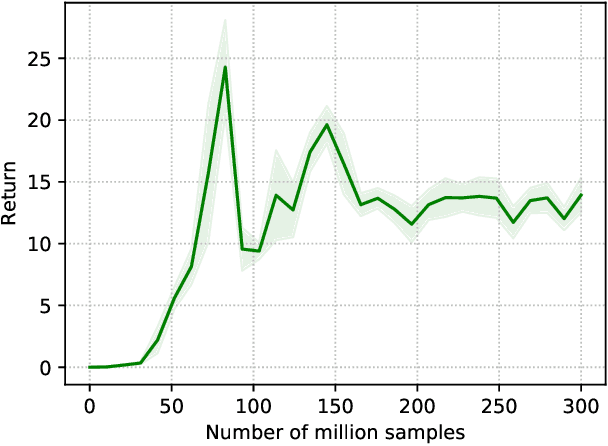
Reinforcement learning (RL) is a promising tool for developing controllers for quadrupedal locomotion. The design of most learning-based locomotion controllers adopts the joint position-based paradigm, wherein a low-frequency RL policy outputs target joint positions that are then tracked by a high-frequency proportional-derivative (PD) controller that outputs joint torques. However, the low frequency of such a policy hinders the advancement of highly dynamic locomotion behaviors. Moreover, determining the PD gains for optimal tracking performance is laborious and dependent on the task at hand. In this paper, we introduce a learning torque control framework for quadrupedal locomotion, which trains an RL policy that directly predicts joint torques at a high frequency, thus circumventing the use of PD controllers. We validate the proposed framework with extensive experiments where the robot is able to both traverse various terrains and resist external pushes, given user-specified commands. To our knowledge, this is the first attempt of learning torque control for quadrupedal locomotion with an end-to-end single neural network that has led to successful real-world experiments among recent research on learning-based quadrupedal locomotion which is mostly position-based.
Vision-aided Dynamic Quadrupedal Locomotion on Discrete Terrain using Motion Libraries
Oct 02, 2021
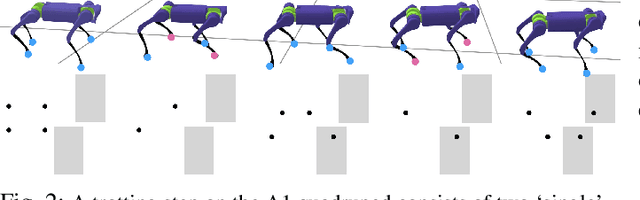
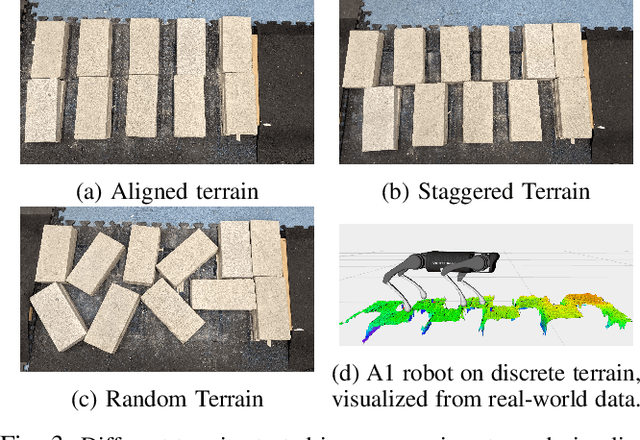

In this paper, we present a framework rooted in control and planning that enables quadrupedal robots to traverse challenging terrains with discrete footholds using visual feedback. Navigating discrete terrain is challenging for quadrupeds because the motion of the robot can be aperiodic, highly dynamic, and blind for the hind legs of the robot. Additionally, the robot needs to reason over both the feasible footholds as well as robot velocity by speeding up and slowing down at different parts of the terrain. We build an offline library of periodic gaits which span two trotting steps on the robot, and switch between different motion primitives to achieve aperiodic motions of different step lengths on an A1 robot. The motion library is used to provide targets to a geometric model predictive controller which controls stance. To incorporate visual feedback, we use terrain mapping tools to build a local height map of the terrain around the robot using RGB and depth cameras, and extract feasible foothold locations around both the front and hind legs of the robot. Our experiments show a Unitree A1 robot navigating multiple unknown, challenging and discrete terrains in the real world.
Learning Periodic Tasks from Human Demonstrations
Sep 28, 2021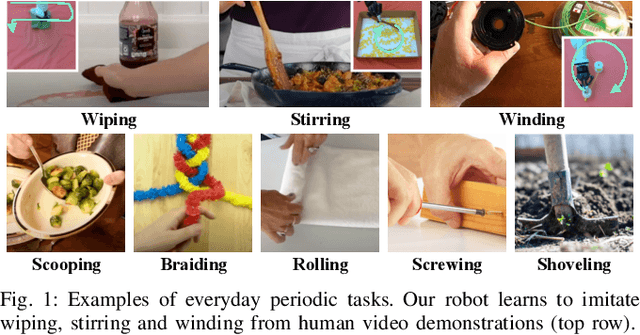
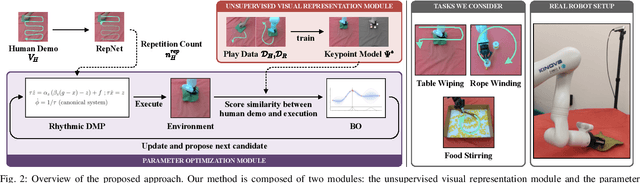
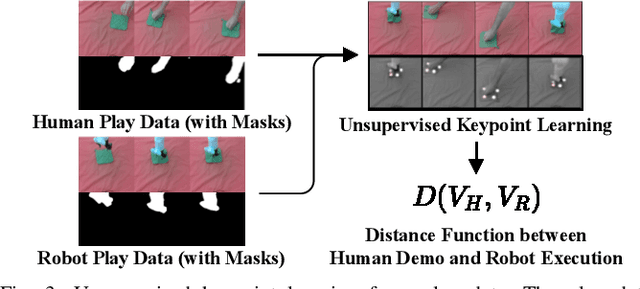
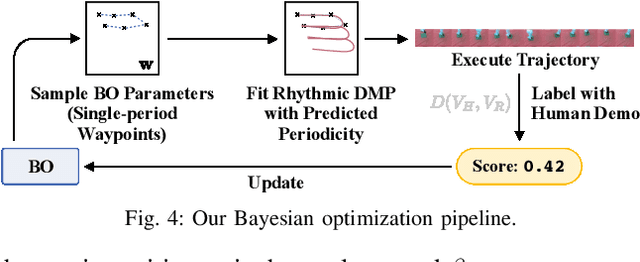
We develop a method for learning periodic tasks from visual demonstrations. The core idea is to leverage periodicity in the policy structure to model periodic aspects of the tasks. We use active learning to optimize parameters of rhythmic dynamic movement primitives (rDMPs) and propose an objective to maximize the similarity between the motion of objects manipulated by the robot and the desired motion in human video demonstrations. We consider tasks with deformable objects and granular matter whose state is challenging to represent and track: wiping surfaces with a cloth, winding cables/wires, stirring granular matter with a spoon. Our method does not require tracking markers or manual annotations. The initial training data consists of 10-minute videos of random unpaired interactions with objects by the robot and human. We use these for unsupervised learning of a keypoint model to get task-agnostic visual correspondences. Then, we use Bayesian optimization to optimize rDMPs from a single human video demonstration within few robot trials. We present simulation and hardware experiments to validate our approach.
Model-based Motion Imitation for Agile, Diverse and Generalizable Quadupedal Locomotion
Sep 27, 2021
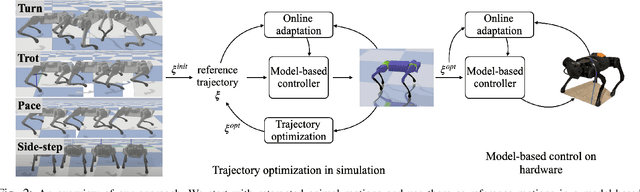
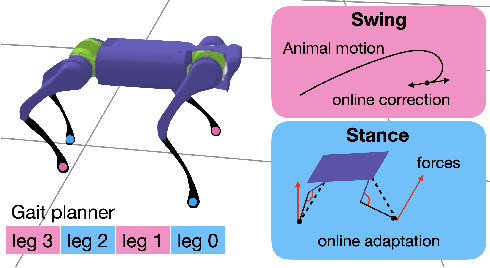
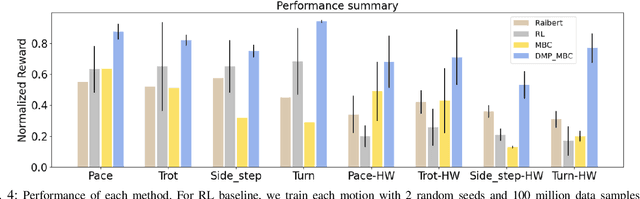
Robots operating in human environments need a variety of skills, like slow and fast walking, turning, and side-stepping. However, building robot controllers that can exhibit such a large range of behaviors is challenging, and unsolved. We present an approach that uses a model-based controller for imitating different animal gaits without requiring any real-world fine-tuning. Unlike previous works that learn one policy per motion, we present a unified controller which is capable of generating four different animal gaits on the A1 robot. Our framework includes a trajectory optimization procedure that improves the quality of real-world imitation. We demonstrate our results in simulation and on a real 12-DoF A1 quadruped robot. Our result shows that our approach can mimic four animal motions, and outperform baselines learned per motion.
Learning-based Initialization Strategy for Safety of Multi-Vehicle Systems
Sep 24, 2021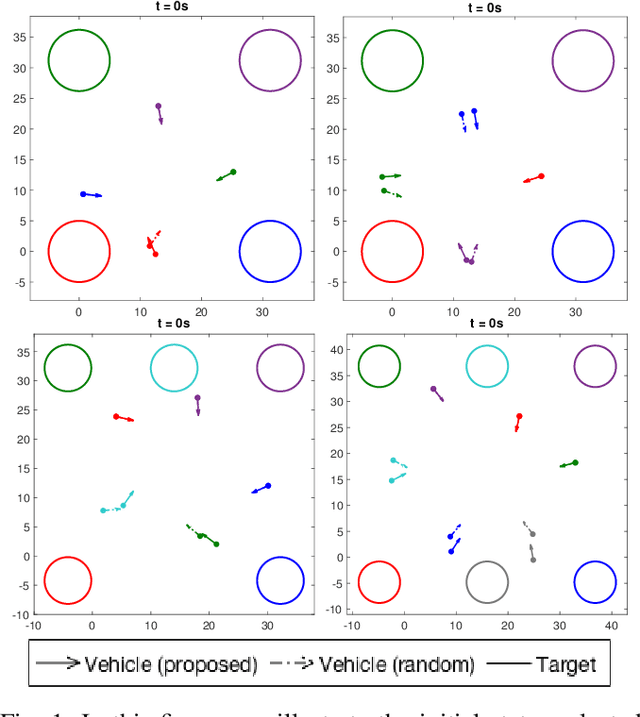
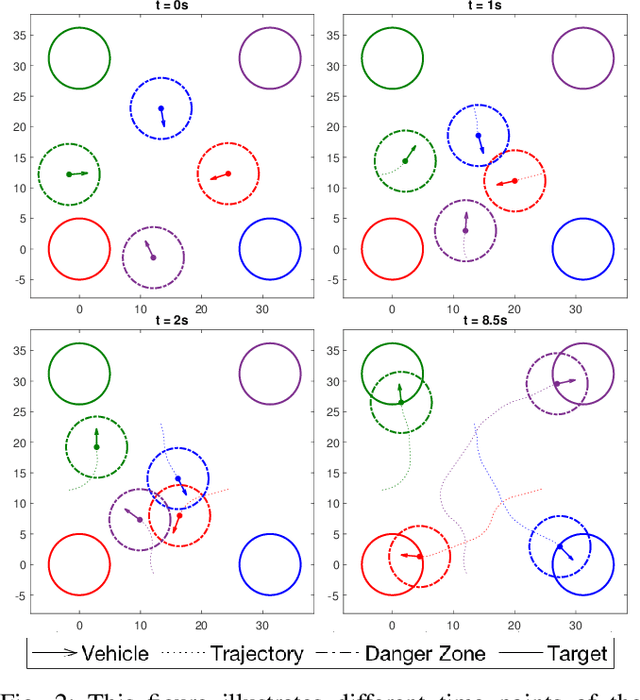
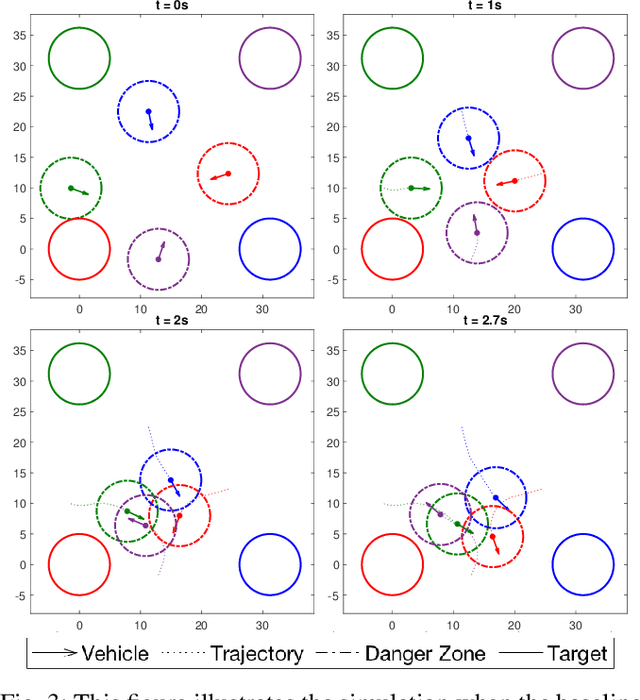
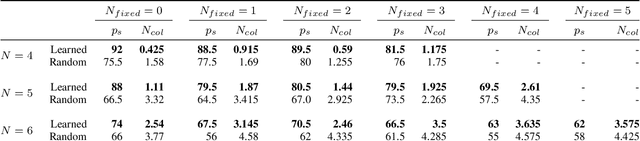
Multi-vehicle collision avoidance is a highly crucial problem due to the soaring interests of introducing autonomous vehicles into the real world in recent years. The safety of these vehicles while they complete their objectives is of paramount importance. Hamilton-Jacobi (HJ) reachability is a promising tool for guaranteeing safety for low-dimensional systems. However, due to its exponential complexity in computation time, no reachability-based methods have been able to guarantee safety for more than three vehicles successfully in unstructured scenarios. For systems with four or more vehicles,we can only empirically validate their safety performance.While reachability-based safety methods enjoy a flexible least-restrictive control strategy, it is challenging to reason about long-horizon trajectories online because safety at any given state is determined by looking up its safety value in a pre-computed table that does not exhibit favorable properties that continuous functions have. This motivates the problem of improving the safety performance of unstructured multi-vehicle systems when safety cannot be guaranteed given any least-restrictive safety-aware collision avoidance algorithm while avoiding online trajectory optimization. In this paper, we propose a novel approach using supervised learning to enhance the safety of vehicles by proposing new initial states in very close neighborhood of the original initial states of vehicles. Our experiments demonstrate the effectiveness of our proposed approach and show that vehicles are able to get to their goals with better safety performance with our approach compared to a baseline approach in wide-ranging scenarios.
Efficient and Interpretable Robot Manipulation with Graph Neural Networks
Feb 25, 2021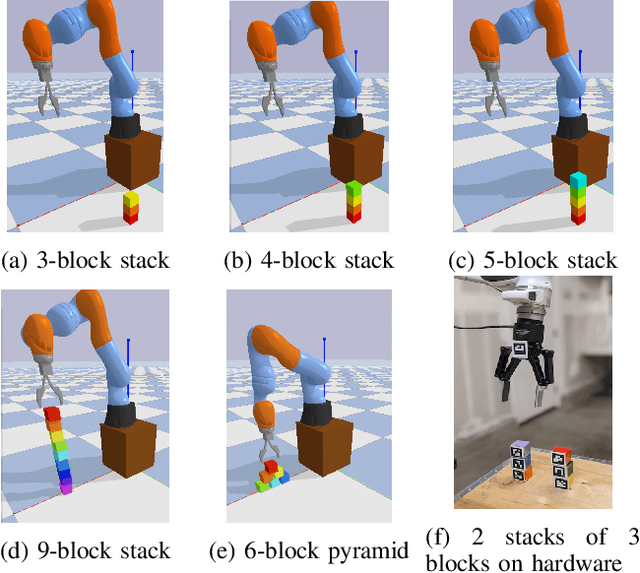


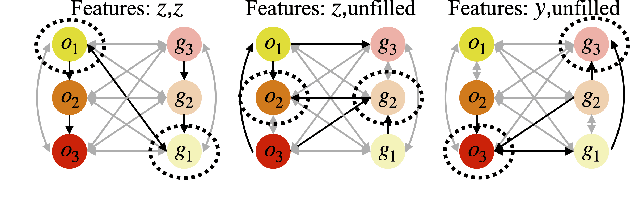
Many manipulation tasks can be naturally cast as a sequence of spatial relationships and constraints between objects. We aim to discover and scale these task-specific spatial relationships by representing manipulation tasks as operations over graphs. To do this, we pose manipulating a large, variable number of objects as a probabilistic classification problem over actions, objects and goals, learned using graph neural networks (GNNs). Our formulation first transforms the environment into a graph representation, then applies a trained GNN policy to predict which object to manipulate towards which goal state. Our GNN policies are trained using very few expert demonstrations on simple tasks, and exhibits generalization over number and configurations of objects in the environment and even to new, more complex tasks, and provide interpretable explanations for their decision-making. We present experiments which show that a single learned GNN policy can solve a variety of blockstacking tasks in both simulation and real hardware.