 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATS: An Interpretable Trajectory Forecasting Representation for Planning and Control
Sep 16, 2020

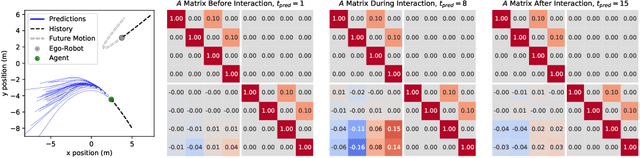
Reasoning about human motion is a core component of modern human-robot interactive systems. In particular, one of the main uses of behavior prediction in autonomous systems is to inform ego-robot motion planning and control. However, a majority of planning and control algorithms reason about system dynamics rather than the predicted agent tracklets that are commonly output by trajectory forecasting methods, which can hinder their integration. Towards this end, we propose Mixtures of Affine Time-varying Systems (MATS) as an output representation for trajectory forecasting that is more amenable to downstream planning and control use. Our approach leverages successful ideas from probabilistic trajectory forecasting works to learn dynamical system representations that are well-studied in the planning and control literature. We integrate our predictions with a proposed multimodal planning methodology and demonstrate significant computational efficiency improvements on a large-scale autonomous driving dataset.
Risk-Sensitive Sequential Action Control with Multi-Modal Human Trajectory Forecasting for Safe Crowd-Robot Interaction
Sep 12, 2020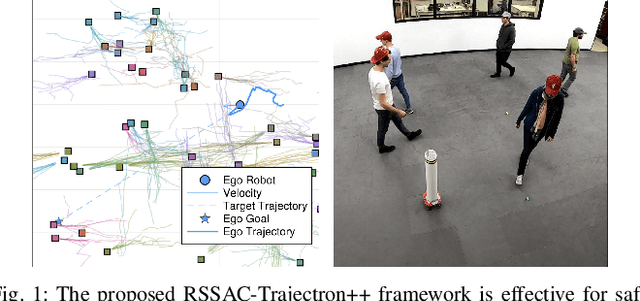

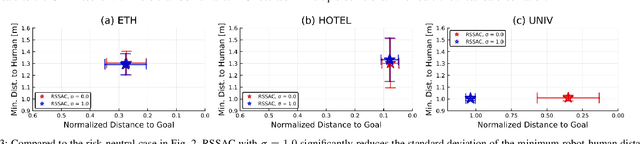
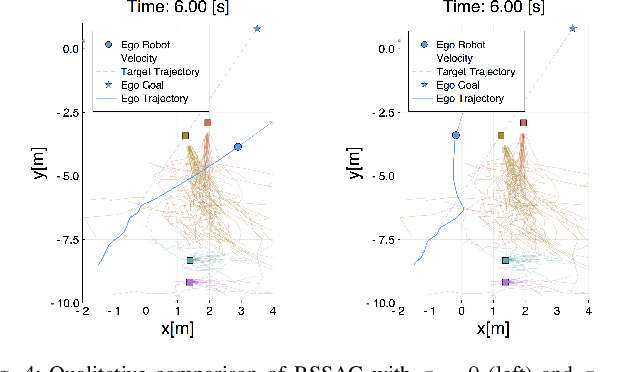
This paper presents a novel online framework for safe crowd-robot interaction based on risk-sensitive stochastic optimal control, wherein the risk is modeled by the entropic risk measure. The sampling-based model predictive control relies on mode insertion gradient optimization for this risk measure as well as Trajectron++, a state-of-the-art generative model that produces multimodal probabilistic trajectory forecasts for multiple interacting agents. Our modular approach decouples the crowd-robot interaction into learning-based prediction and model-based control, which is advantageous compared to end-to-end policy learning methods in that it allows the robot's desired behavior to be specified at run time. In particular, we show that the robot exhibits diverse interaction behavior by varying the risk sensitivity parameter. A simulation study and a real-world experiment show that the proposed online framework can accomplish safe and efficient navigation while avoiding collisions with more than 50 humans in the scene.
PillarFlow: End-to-end Birds-eye-view Flow Estimation for Autonomous Driving
Aug 29, 2020
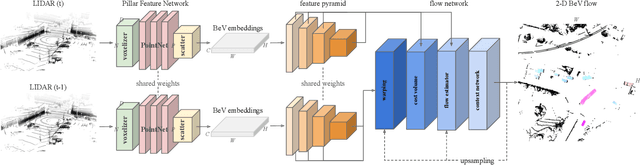

In autonomous driving, accurately estimating the state of surrounding obstacles is critical for safe and robust path planning. However, this perception task is difficult, particularly for generic obstacles/objects, due to appearance and occlusion changes. To tackle this problem, we propose an end-to-end deep learning framework for LIDAR-based flow estimation in bird's eye view (BeV). Our method takes consecutive point cloud pairs as input and produces a 2-D BeV flow grid describing the dynamic state of each cell. The experimental results show that the proposed method not only estimates 2-D BeV flow accurately but also improves tracking performance of both dynamic and static objects.
Driving Through Ghosts: Behavioral Cloning with False Positives
Aug 29, 2020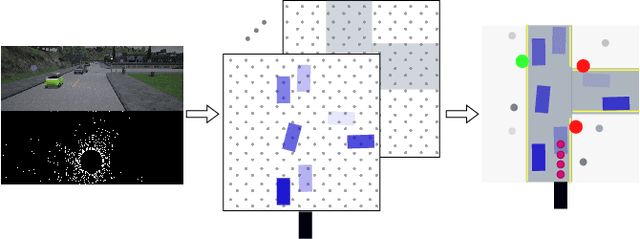
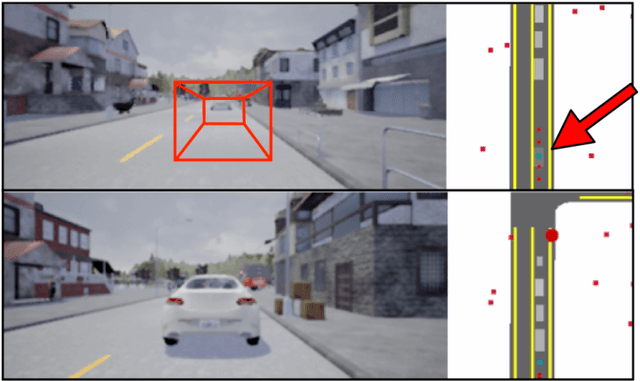
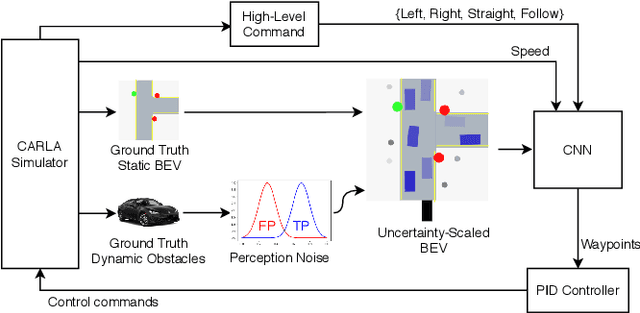
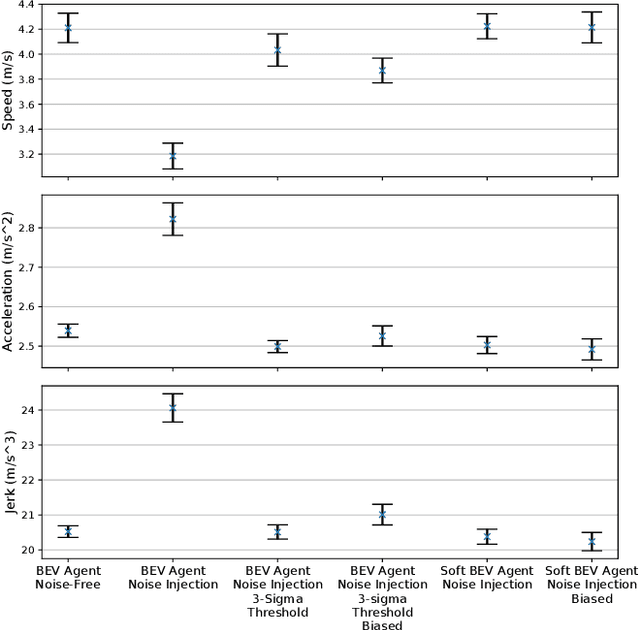
Safe autonomous driving requires robust detection of other traffic participants. However, robust does not mean perfect, and safe systems typically minimize missed detections at the expense of a higher false positive rate. This results in conservative and yet potentially dangerous behavior such as avoiding imaginary obstacles. In the context of behavioral cloning, perceptual errors at training time can lead to learning difficulties or wrong policies, as expert demonstrations might be inconsistent with the perceived world state. In this work, we propose a behavioral cloning approach that can safely leverage imperfect perception without being conservative. Our core contribution is a novel representation of perceptual uncertainty for learning to plan. We propose a new probabilistic birds-eye-view semantic grid to encode the noisy output of object perception systems. We then leverage expert demonstrations to learn an imitative driving policy using this probabilistic representation. Using the CARLA simulator, we show that our approach can safely overcome critical false positives that would otherwise lead to catastrophic failures or conservative behavior.
Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-motion
Aug 15, 2020
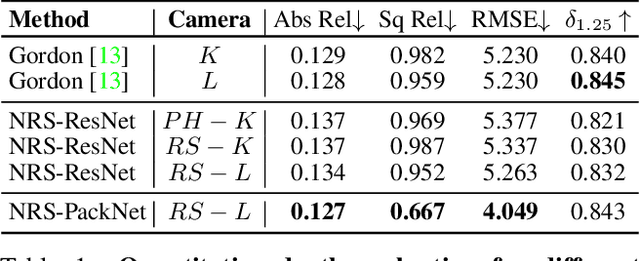
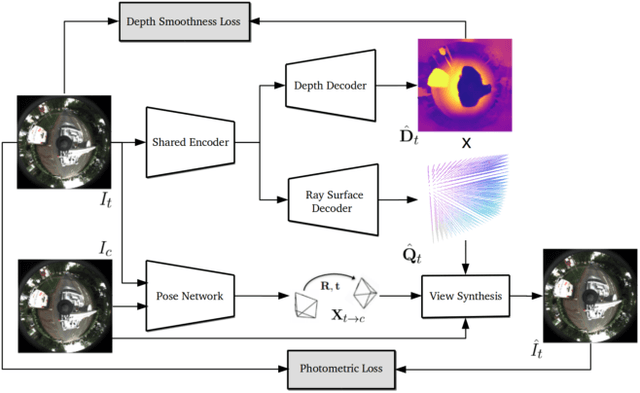

Self-supervised learning has emerged as a powerful tool for depth and ego-motion estimation, leading to state-of-the-art results on benchmark datasets. However, one significant limitation shared by current methods is the assumption of a known parametric camera model -- usually the standard pinhole geometry -- leading to failure when applied to imaging systems that deviate significantly from this assumption (e.g., catadioptric cameras or underwater imaging). In this work, we show that self-supervision can be used to learn accurate depth and ego-motion estimation without prior knowledge of the camera model. Inspired by the geometric model of Grossberg and Nayar, we introduce Neural Ray Surfaces (NRS), convolutional networks that represent pixel-wise projection rays, approximating a wide range of cameras. NRS are fully differentiable and can be learned end-to-end from unlabeled raw videos. We demonstrate the use of NRS for self-supervised learning of visual odometry and depth estimation from raw videos obtained using a wide variety of camera systems, including pinhole, fisheye, and catadioptric.
Reinforcement Learning based Control of Imitative Policies for Near-Accident Driving
Jul 01, 2020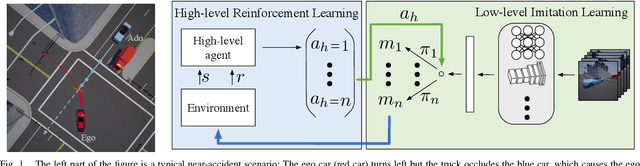
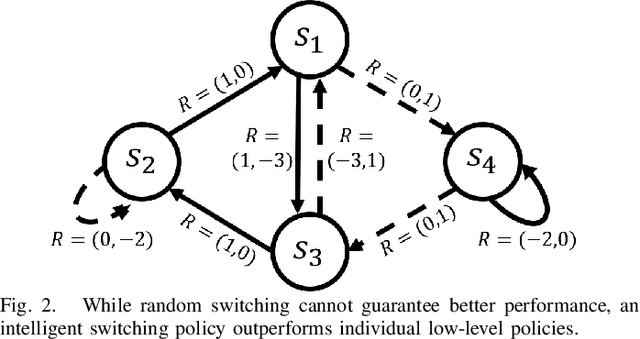
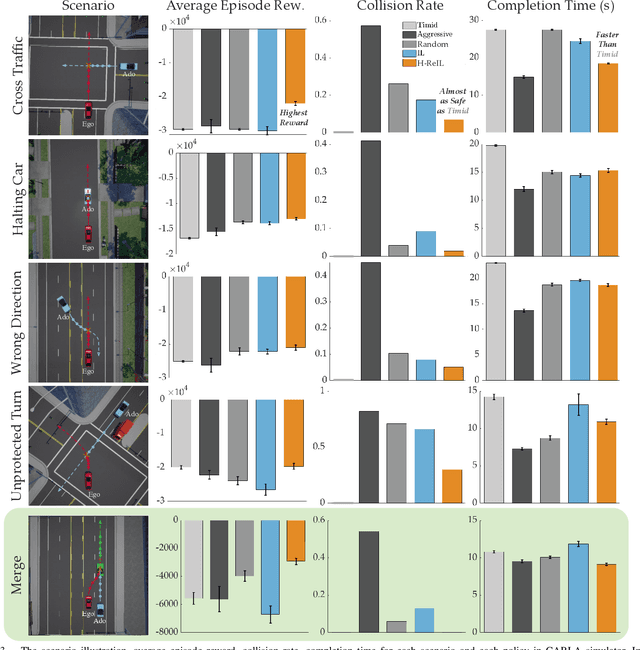
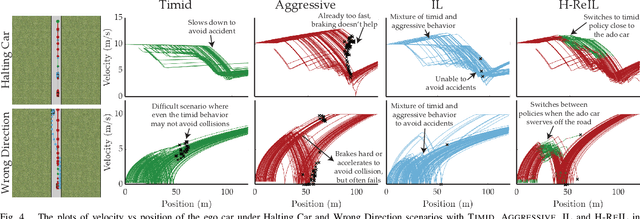
Autonomous driving has achieved significant progress in recent years, but autonomous cars are still unable to tackle high-risk situations where a potential accident is likely. In such near-accident scenarios, even a minor change in the vehicle's actions may result in drastically different consequences. To avoid unsafe actions in near-accident scenarios, we need to fully explore the environment. However, reinforcement learning (RL) and imitation learning (IL), two widely-used policy learning methods, cannot model rapid phase transitions and are not scalable to fully cover all the states. To address driving in near-accident scenarios, we propose a hierarchical reinforcement and imitation learning (H-ReIL) approach that consists of low-level policies learned by IL for discrete driving modes, and a high-level policy learned by RL that switches between different driving modes. Our approach exploits the advantages of both IL and RL by integrating them into a unified learning framework. Experimental results and user studies suggest our approach can achieve higher efficiency and safety compared to other methods. Analyses of the policies demonstrate our high-level policy appropriately switches between different low-level policies in near-accident driving situations.
Heteroskedastic and Imbalanced Deep Learning with Adaptive Regularization
Jun 29, 2020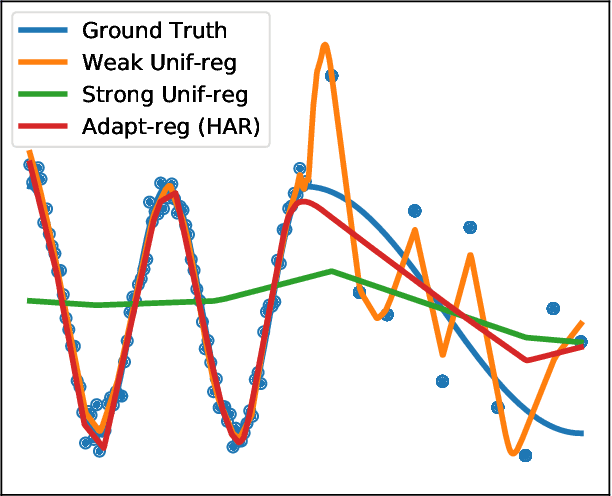
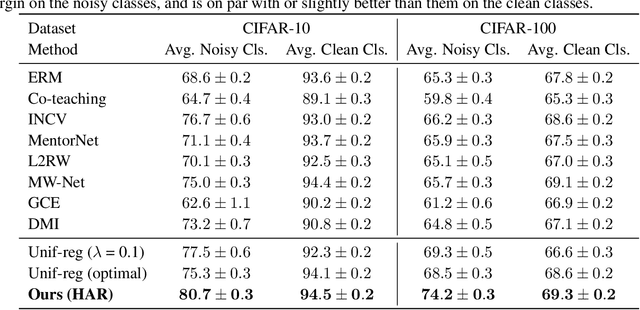
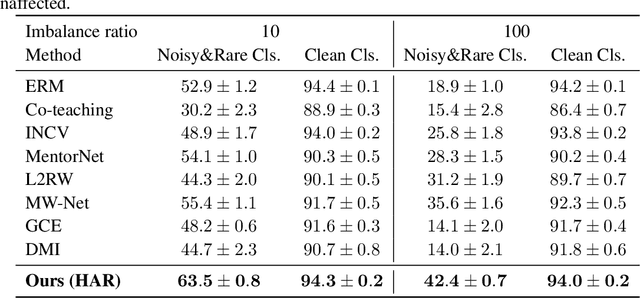
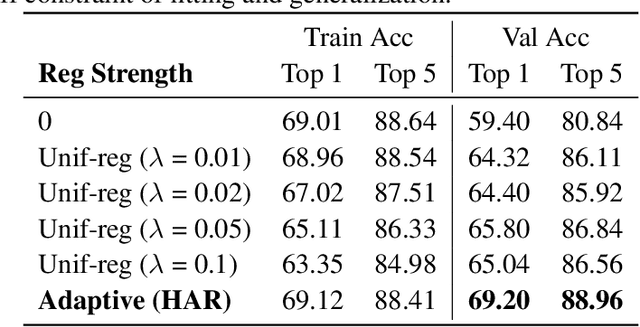
Real-world large-scale datasets are heteroskedastic and imbalanced -- labels have varying levels of uncertainty and label distributions are long-tailed. Heteroskedasticity and imbalance challenge deep learning algorithms due to the difficulty of distinguishing among mislabeled, ambiguous, and rare examples. Addressing heteroskedasticity and imbalance simultaneously is under-explored. We propose a data-dependent regularization technique for heteroskedastic datasets that regularizes different regions of the input space differently. Inspired by the theoretical derivation of the optimal regularization strength in a one-dimensional nonparametric classification setting, our approach adaptively regularizes the data points in higher-uncertainty, lower-density regions more heavily. We test our method on several benchmark tasks, including a real-world heteroskedastic and imbalanced dataset, WebVision. Our experiments corroborate our theory and demonstrate a significant improvement over other methods in noise-robust deep learning.
Differentiable Rendering: A Survey
Jun 22, 2020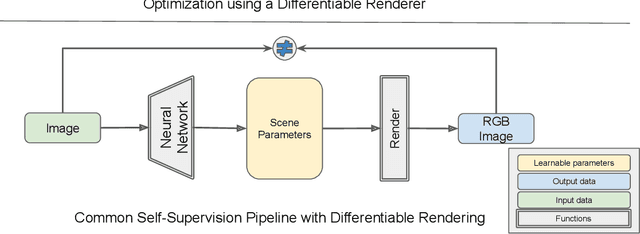
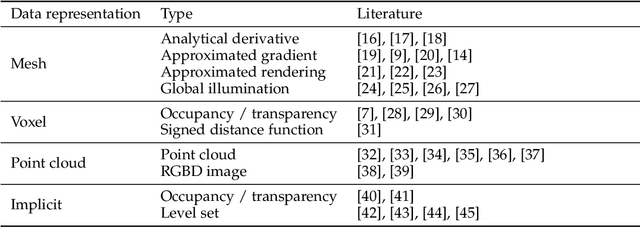
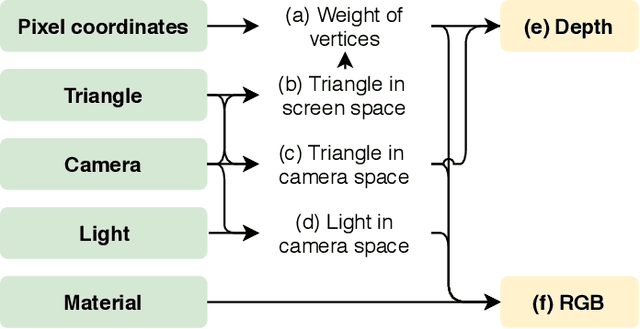

Deep neural networks (DNNs) have shown remarkable performance improvements on vision-related tasks such as object detection or image segmentation. Despite their success, they generally lack the understanding of 3D objects which form the image, as it is not always possible to collect 3D information about the scene or to easily annotate it. Differentiable rendering is a novel field which allows the gradients of 3D objects to be calculated and propagated through images. It also reduces the requirement of 3D data collection and annotation, while enabling higher success rate in various applications. This paper reviews existing literature and discusses the current state of differentiable rendering, its applications and open research problems.
It Is Not the Journey but the Destination: Endpoint Conditioned Trajectory Prediction
Apr 04, 2020

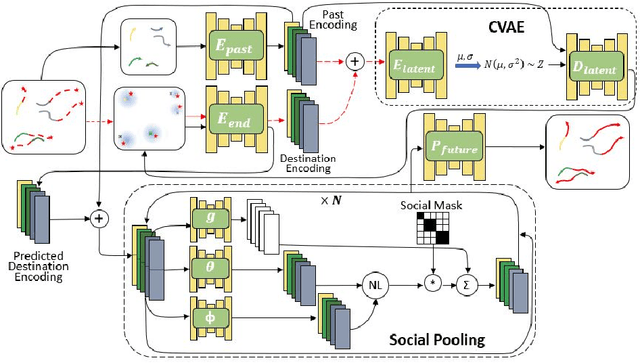
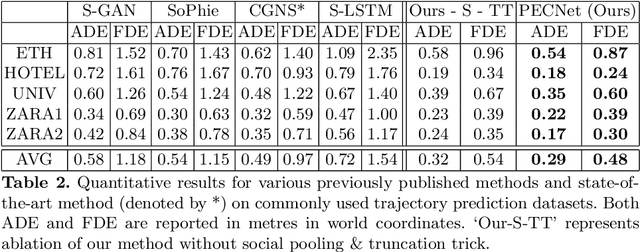
Human trajectory forecasting with multiple socially interacting agents is of critical importance for autonomous navigation in human environments, e.g., for self-driving cars and social robots. In this work, we present Predicted Endpoint Conditioned Network (PECNet) for flexible human trajectory prediction. PECNet infers distant trajectory endpoints to assist in long-range multi-modal trajectory prediction. A novel non-local social pooling layer enables PECNet to infer diverse yet socially compliant trajectories. Additionally, we present a simple "truncation-trick" for improving few-shot multi-modal trajectory prediction performance. We show that PECNet improves state-of-the-art performance on the Stanford Drone trajectory prediction benchmark by ~19.5% and on the ETH/UCY benchmark by ~40.8%.
Spatio-Temporal Graph for Video Captioning with Knowledge Distillation
Mar 31, 2020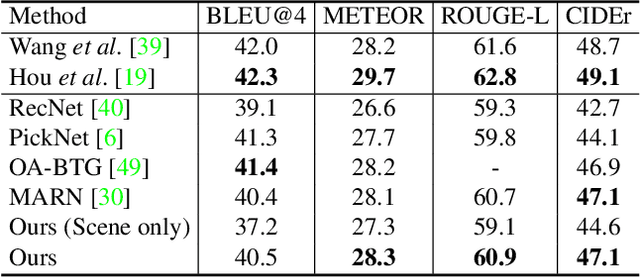
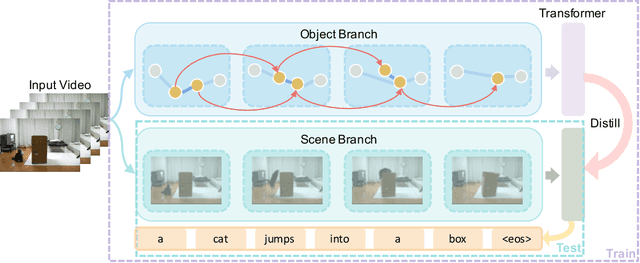
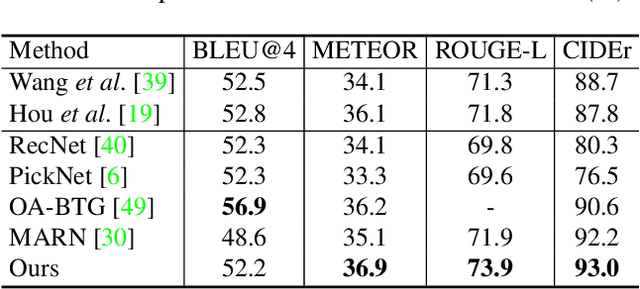
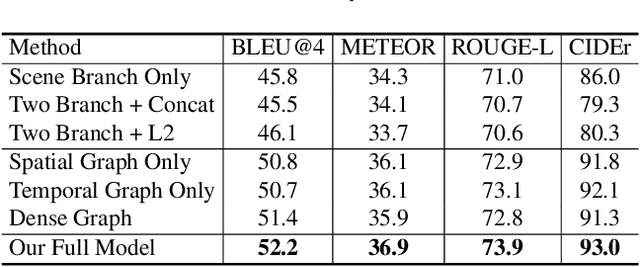
Video captioning is a challenging task that requires a deep understanding of visual scenes. State-of-the-art methods generate captions using either scene-level or object-level information but without explicitly modeling object interactions. Thus, they often fail to make visually grounded predictions, and are sensitive to spurious correlations. In this paper, we propose a novel spatio-temporal graph model for video captioning that exploits object interactions in space and time. Our model builds interpretable links and is able to provide explicit visual grounding. To avoid unstable performance caused by the variable number of objects, we further propose an object-aware knowledge distillation mechanism, in which local object information is used to regularize global scene features. We demonstrate the efficacy of our approach through extensive experiments on two benchmarks, showing our approach yields competitive performance with interpretable predictions.