 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylish and Functional: Guided Interpolation Subject to Physical Constraints
Dec 20, 2024



Generative AI is revolutionizing engineering design practices by enabling rapid prototyping and manipulation of designs. One example of design manipulation involves taking two reference design images and using them as prompts to generate a design image that combines aspects of both. Real engineering designs have physical constraints and functional requirements in addition to aesthetic design considerations. Internet-scale foundation models commonly used for image generation, however, are unable to take these physical constraints and functional requirements into consideration as part of the generation process. We consider the problem of generating a design inspired by two input designs, and propose a zero-shot framework toward enforcing physical, functional requirements over the generation process by leveraging a pretrained diffusion model as the backbone. As a case study, we consider the example of rotational symmetry in generation of wheel designs. Automotive wheels are required to be rotationally symmetric for physical stability. We formulate the requirement of rotational symmetry by the use of a symmetrizer, and we use this symmetrizer to guide the diffusion process towards symmetric wheel generations. Our experimental results find that the proposed approach makes generated interpolations with higher realism than methods in related work, as evaluated by Fr\'echet inception distance (FID). We also find that our approach generates designs that more closely satisfy physical and functional requirements than generating without the symmetry guidance.
Parametric-ControlNet: Multimodal Control in Foundation Models for Precise Engineering Design Synthesis
Dec 06, 2024



This paper introduces a generative model designed for multimodal control over text-to-image foundation generative AI models such as Stable Diffusion, specifically tailored for engineering design synthesis. Our model proposes parametric, image, and text control modalities to enhance design precision and diversity. Firstly, it handles both partial and complete parametric inputs using a diffusion model that acts as a design autocomplete co-pilot, coupled with a parametric encoder to process the information. Secondly, the model utilizes assembly graphs to systematically assemble input component images, which are then processed through a component encoder to capture essential visual data. Thirdly, textual descriptions are integrated via CLIP encoding, ensuring a comprehensive interpretation of design intent. These diverse inputs are synthesized through a multimodal fusion technique, creating a joint embedding that acts as the input to a module inspired by ControlNet. This integration allows the model to apply robust multimodal control to foundation models, facilitating the generation of complex and precise engineering designs. This approach broadens the capabilities of AI-driven design tools and demonstrates significant advancements in precise control based on diverse data modalities for enhanced design generation.
Leveraging Language Models and Bandit Algorithms to Drive Adoption of Battery-Electric Vehicles
Oct 30, 2024



Behavior change interventions are important to coordinate societal action across a wide array of important applications, including the adoption of electrified vehicles to reduce emissions. Prior work has demonstrated that interventions for behavior must be personalized, and that the intervention that is most effective on average across a large group can result in a backlash effect that strengthens opposition among some subgroups. Thus, it is important to target interventions to different audiences, and to present them in a natural, conversational style. In this context, an important emerging application domain for large language models (LLMs) is conversational interventions for behavior change. In this work, we leverage prior work on understanding values motivating the adoption of battery electric vehicles. We leverage new advances in LLMs, combined with a contextual bandit, to develop conversational interventions that are personalized to the values of each study participant. We use a contextual bandit algorithm to learn to target values based on the demographics of each participant. To train our bandit algorithm in an offline manner, we leverage LLMs to play the role of study participants. We benchmark the persuasive effectiveness of our bandit-enhanced LLM against an unaided LLM generating conversational interventions without demographic-targeted values.
On LLM Wizards: Identifying Large Language Models' Behaviors for Wizard of Oz Experiments
Jul 10, 2024The Wizard of Oz (WoZ) method is a widely adopted research approach where a human Wizard ``role-plays'' a not readily available technology and interacts with participants to elicit user behaviors and probe the design space. With the growing ability for modern large language models (LLMs) to role-play, one can apply LLMs as Wizards in WoZ experiments with better scalability and lower cost than the traditional approach. However, methodological guidance on responsibly applying LLMs in WoZ experiments and a systematic evaluation of LLMs' role-playing ability are lacking. Through two LLM-powered WoZ studies, we take the first step towards identifying an experiment lifecycle for researchers to safely integrate LLMs into WoZ experiments and interpret data generated from settings that involve Wizards role-played by LLMs. We also contribute a heuristic-based evaluation framework that allows the estimation of LLMs' role-playing ability in WoZ experiments and reveals LLMs' behavior patterns at scale.
* To be published in ACM IVA 2024
Bridging Design Gaps: A Parametric Data Completion Approach With Graph Guided Diffusion Models
Jun 17, 2024



This study introduces a generative imputation model leveraging graph attention networks and tabular diffusion models for completing missing parametric data in engineering designs. This model functions as an AI design co-pilot, providing multiple design options for incomplete designs, which we demonstrate using the bicycle design CAD dataset. Through comparative evaluations, we demonstrate that our model significantly outperforms existing classical methods, such as MissForest, hotDeck, PPCA, and tabular generative method TabCSDI in both the accuracy and diversity of imputation options. Generative modeling also enables a broader exploration of design possibilities, thereby enhancing design decision-making by allowing engineers to explore a variety of design completions. The graph model combines GNNs with the structural information contained in assembly graphs, enabling the model to understand and predict the complex interdependencies between different design parameters. The graph model helps accurately capture and impute complex parametric interdependencies from an assembly graph, which is key for design problems. By learning from an existing dataset of designs, the imputation capability allows the model to act as an intelligent assistant that autocompletes CAD designs based on user-defined partial parametric design, effectively bridging the gap between ideation and realization. The proposed work provides a pathway to not only facilitate informed design decisions but also promote creative exploration in design.
Using LLMs to Model the Beliefs and Preferences of Targeted Populations
Mar 29, 2024We consider the problem of aligning a large language model (LLM) to model the preferences of a human population. Modeling the beliefs, preferences, and behaviors of a specific population can be useful for a variety of different applications, such as conducting simulated focus groups for new products, conducting virtual surveys, and testing behavioral interventions, especially for interventions that are expensive, impractical, or unethical. Existing work has had mixed success using LLMs to accurately model human behavior in different contexts. We benchmark and evaluate two well-known fine-tuning approaches and evaluate the resulting populations on their ability to match the preferences of real human respondents on a survey of preferences for battery electric vehicles (BEVs). We evaluate our models against their ability to match population-wide statistics as well as their ability to match individual responses, and we investigate the role of temperature in controlling the trade-offs between these two. Additionally, we propose and evaluate a novel loss term to improve model performance on responses that require a numeric response.
A Preference Learning Approach to Develop Safe and Personalizable Autonomous Vehicles
Oct 30, 2023This work introduces a preference learning method that ensures adherence to traffic rules for autonomous vehicles. Our approach incorporates priority ordering of signal temporal logic (STL) formulas, describing traffic rules, into a learning framework. By leveraging the parametric weighted signal temporal logic (PWSTL), we formulate the problem of safety-guaranteed preference learning based on pairwise comparisons, and propose an approach to solve this learning problem. Our approach finds a feasible valuation for the weights of the given PWSTL formula such that, with these weights, preferred signals have weighted quantitative satisfaction measures greater than their non-preferred counterparts. The feasible valuation of weights given by our approach leads to a weighted STL formula which can be used in correct-and-custom-by-construction controller synthesis. We demonstrate the performance of our method with human subject studies in two different simulated driving scenarios involving a stop sign and a pedestrian crossing. Our approach yields competitive results compared to existing preference learning methods in terms of capturing preferences, and notably outperforms them when safety is considered.
Training Towards Critical Use: Learning to Situate AI Predictions Relative to Human Knowledge
Aug 30, 2023
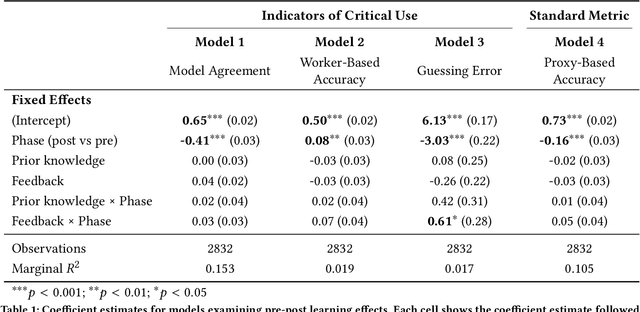
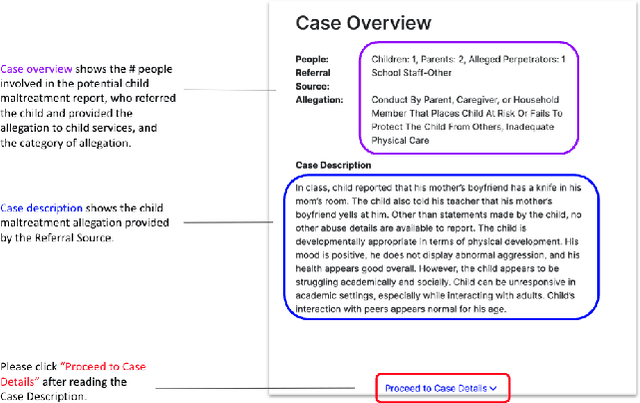
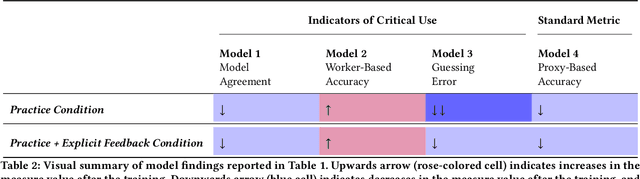
A growing body of research has explored how to support humans in making better use of AI-based decision support, including via training and onboarding. Existing research has focused on decision-making tasks where it is possible to evaluate "appropriate reliance" by comparing each decision against a ground truth label that cleanly maps to both the AI's predictive target and the human decision-maker's goals. However, this assumption does not hold in many real-world settings where AI tools are deployed today (e.g., social work, criminal justice, and healthcare). In this paper, we introduce a process-oriented notion of appropriate reliance called critical use that centers the human's ability to situate AI predictions against knowledge that is uniquely available to them but unavailable to the AI model. To explore how training can support critical use, we conduct a randomized online experiment in a complex social decision-making setting: child maltreatment screening. We find that, by providing participants with accelerated, low-stakes opportunities to practice AI-assisted decision-making in this setting, novices came to exhibit patterns of disagreement with AI that resemble those of experienced workers. A qualitative examination of participants' explanations for their AI-assisted decisions revealed that they drew upon qualitative case narratives, to which the AI model did not have access, to learn when (not) to rely on AI predictions. Our findings open new questions for the study and design of training for real-world AI-assisted decision-making.
Drag-guided diffusion models for vehicle image generation
Jun 16, 2023



Denoising diffusion models trained at web-scale have revolutionized image generation. The application of these tools to engineering design is an intriguing possibility, but is currently limited by their inability to parse and enforce concrete engineering constraints. In this paper, we take a step towards this goal by proposing physics-based guidance, which enables optimization of a performance metric (as predicted by a surrogate model) during the generation process. As a proof-of-concept, we add drag guidance to Stable Diffusion, which allows this tool to generate images of novel vehicles while simultaneously minimizing their predicted drag coefficients.
Surrogate Modeling of Car Drag Coefficient with Depth and Normal Renderings
May 26, 2023



Generative AI models have made significant progress in automating the creation of 3D shapes, which has the potential to transform car design. In engineering design and optimization, evaluating engineering metrics is crucial. To make generative models performance-aware and enable them to create high-performing designs, surrogate modeling of these metrics is necessary. However, the currently used representations of three-dimensional (3D) shapes either require extensive computational resources to learn or suffer from significant information loss, which impairs their effectiveness in surrogate modeling. To address this issue, we propose a new two-dimensional (2D) representation of 3D shapes. We develop a surrogate drag model based on this representation to verify its effectiveness in predicting 3D car drag. We construct a diverse dataset of 9,070 high-quality 3D car meshes labeled by drag coefficients computed from computational fluid dynamics (CFD) simulations to train our model. Our experiments demonstrate that our model can accurately and efficiently evaluate drag coefficients with an $R^2$ value above 0.84 for various car categories. Moreover, the proposed representation method can be generalized to many other product categories beyond cars. Our model is implemented using deep neural networks, making it compatible with recent AI image generation tools (such as Stable Diffusion) and a significant step towards the automatic generation of drag-optimized car designs. We have made the dataset and code publicly available at https://decode.mit.edu/projects/dragprediction/.