 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Precision Hydraulic Excavator Control for Heavy-Duty Grading
May 10, 2026High-precision heavy-duty grading is a common step in earthworks, traditionally carried out manually by skilled operators. Removing a significant amount of material while achieving a high-precision surface requires substantial machine-specific experience. Different hydraulic architectures react differently to operator inputs and soil interaction forces, which makes generalizable controllers challenging. In this paper, we present an autonomous controller that achieves high-precision grading at expert-operator speed on Load Sensing and Negative Flow Control machines alike. We split our controller into two parts: (1) a hydraulic-aware low-level loop that is hydraulic architecture-specific and (2) a path-tracking layer that coordinates joint motions and responses. Through a calibration process, our technique is applicable to load-sensing and negative-flow-control machinery. To showcase its versatility, we benchmark our approach on two excavators with different hydraulics and compare it against a commercial state-of-the-art solution. Our technique (RMSE 1.8~cm) outperforms the commercial solution (RMSE 4.7~cm) in precision by a factor of 2.6 and improves machine usage by leveraging the maximum function pressure, as opposed to commercial solutions that stall prematurely.
Learning Multi-Agent Local Collision-Avoidance for Collaborative Carrying tasks with Coupled Quadrupedal Robots
Mar 24, 2026Robotic collaborative carrying could greatly benefit human activities like warehouse and construction site management. However, coordinating the simultaneous motion of multiple robots represents a significant challenge. Existing works primarily focus on obstacle-free environments, making them unsuitable for most real-world applications. Works that account for obstacles, either overfit to a specific terrain configuration or rely on pre-recorded maps combined with path planners to compute collision-free trajectories. This work focuses on two quadrupedal robots mechanically connected to a carried object. We propose a Reinforcement Learning (RL)-based policy that enables tracking a commanded velocity direction while avoiding collisions with nearby obstacles using only onboard sensing, eliminating the need for precomputed trajectories and complete map knowledge. Our work presents a hierarchical architecture, where a perceptive high-level object-centric policy commands two pretrained locomotion policies. Additionally, we employ a game-inspired curriculum to increase the complexity of obstacles in the terrain progressively. We validate our approach on two quadrupedal robots connected to a bar via spherical joints, benchmarking it against optimization-based and decentralized RL baselines. Our hardware experiments demonstrate the ability of our system to locomote in unknown environments without the need for a map or a path planner. The video of our work is available in the multimedia material.
Beyond Cybathlon: On-demand Quadrupedal Assistance for People with Limited Mobility
Mar 17, 2026Background: Assistance robots have the potential to increase the independence of people who need daily care due to limited mobility or being wheelchair-bound. Current solutions of attaching robotic arms to motorized wheelchairs offer limited additional mobility at the cost of increased size and reduced wheelchair maneuverability. Methods: We present an on-demand quadrupedal assistance robot system controlled via a shared autonomy approach, which combines semi-autonomous task execution with human teleoperation. Due to the mobile nature of the system it can assist the operator whenever needed and perform autonomous tasks independently, without otherwise restricting their mobility. We automate pick-and-place tasks, as well as robot movement through the environment with semantic, collision-aware navigation. For teleoperation, we present a mouth-level joystick interface that enables an operator with reduced mobility to control the robot's end effector for precision manipulation. Results: We showcase our system in the \textit{Cybathlon 2024 Assistance Robot Race}, and validate it in an at-home experimental setup, where we measure task completion times and user satisfaction. We find our system capable of assisting in a broad variety of tasks, including those that require dexterous manipulation. The user study confirms the intuition that increased robot autonomy alleviates the operator's mental load. Conclusions: We present a flexible system that has the potential to help people in wheelchairs maintain independence in everyday life by enabling them to solve mobile manipulation problems without external support. We achieve results comparable to previous state-of-the-art on subjective metrics while allowing for more autonomy of the operator and greater agility for manipulation.
DexEvolve: Evolutionary Optimization for Robust and Diverse Dexterous Grasp Synthesis
Feb 16, 2026Dexterous grasping is fundamental to robotics, yet data-driven grasp prediction heavily relies on large, diverse datasets that are costly to generate and typically limited to a narrow set of gripper morphologies. Analytical grasp synthesis can be used to scale data collection, but necessary simplifying assumptions often yield physically infeasible grasps that need to be filtered in high-fidelity simulators, significantly reducing the total number of grasps and their diversity. We propose a scalable generate-and-refine pipeline for synthesizing large-scale, diverse, and physically feasible grasps. Instead of using high-fidelity simulators solely for verification and filtering, we leverage them as an optimization stage that continuously improves grasp quality without discarding precomputed candidates. More specifically, we initialize an evolutionary search with a seed set of analytically generated, potentially suboptimal grasps. We then refine these proposals directly in a high-fidelity simulator (Isaac Sim) using an asynchronous, gradient-free evolutionary algorithm, improving stability while maintaining diversity. In addition, this refinement stage can be guided toward human preferences and/or domain-specific quality metrics without requiring a differentiable objective. We further distill the refined grasp distribution into a diffusion model for robust real-world deployment, and highlight the role of diversity for both effective training and during deployment. Experiments on a newly introduced Handles dataset and a DexGraspNet subset demonstrate that our approach achieves over 120 distinct stable grasps per object (a 1.7-6x improvement over unrefined analytical methods) while outperforming diffusion-based alternatives by 46-60\% in unique grasp coverage.
Pretraining in Actor-Critic Reinforcement Learning for Robot Motion Control
Oct 14, 2025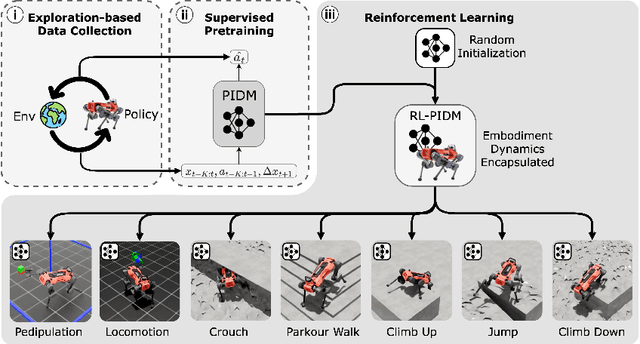


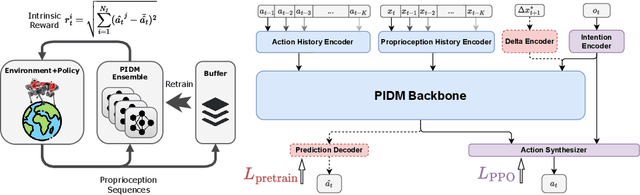
The pretraining-finetuning paradigm has facilitated numerous transformative advancements in artificial intelligence research in recent years. However, in the domain of reinforcement learning (RL) for robot motion control, individual skills are often learned from scratch despite the high likelihood that some generalizable knowledge is shared across all task-specific policies belonging to a single robot embodiment. This work aims to define a paradigm for pretraining neural network models that encapsulate such knowledge and can subsequently serve as a basis for warm-starting the RL process in classic actor-critic algorithms, such as Proximal Policy Optimization (PPO). We begin with a task-agnostic exploration-based data collection algorithm to gather diverse, dynamic transition data, which is then used to train a Proprioceptive Inverse Dynamics Model (PIDM) through supervised learning. The pretrained weights are loaded into both the actor and critic networks to warm-start the policy optimization of actual tasks. We systematically validated our proposed method on seven distinct robot motion control tasks, showing significant benefits to this initialization strategy. Our proposed approach on average improves sample efficiency by 40.1% and task performance by 7.5%, compared to random initialization. We further present key ablation studies and empirical analyses that shed light on the mechanisms behind the effectiveness of our method.
GraspQP: Differentiable Optimization of Force Closure for Diverse and Robust Dexterous Grasping
Aug 20, 2025



Dexterous robotic hands enable versatile interactions due to the flexibility and adaptability of multi-fingered designs, allowing for a wide range of task-specific grasp configurations in diverse environments. However, to fully exploit the capabilities of dexterous hands, access to diverse and high-quality grasp data is essential -- whether for developing grasp prediction models from point clouds, training manipulation policies, or supporting high-level task planning with broader action options. Existing approaches for dataset generation typically rely on sampling-based algorithms or simplified force-closure analysis, which tend to converge to power grasps and often exhibit limited diversity. In this work, we propose a method to synthesize large-scale, diverse, and physically feasible grasps that extend beyond simple power grasps to include refined manipulations, such as pinches and tri-finger precision grasps. We introduce a rigorous, differentiable energy formulation of force closure, implicitly defined through a Quadratic Program (QP). Additionally, we present an adjusted optimization method (MALA*) that improves performance by dynamically rejecting gradient steps based on the distribution of energy values across all samples. We extensively evaluate our approach and demonstrate significant improvements in both grasp diversity and the stability of final grasp predictions. Finally, we provide a new, large-scale grasp dataset for 5,700 objects from DexGraspNet, comprising five different grippers and three distinct grasp types. Dataset and Code:https://graspqp.github.io/
Learning coordinated badminton skills for legged manipulators
May 29, 2025Coordinating the motion between lower and upper limbs and aligning limb control with perception are substantial challenges in robotics, particularly in dynamic environments. To this end, we introduce an approach for enabling legged mobile manipulators to play badminton, a task that requires precise coordination of perception, locomotion, and arm swinging. We propose a unified reinforcement learning-based control policy for whole-body visuomotor skills involving all degrees of freedom to achieve effective shuttlecock tracking and striking. This policy is informed by a perception noise model that utilizes real-world camera data, allowing for consistent perception error levels between simulation and deployment and encouraging learned active perception behaviors. Our method includes a shuttlecock prediction model, constrained reinforcement learning for robust motion control, and integrated system identification techniques to enhance deployment readiness. Extensive experimental results in a variety of environments validate the robot's capability to predict shuttlecock trajectories, navigate the service area effectively, and execute precise strikes against human players, demonstrating the feasibility of using legged mobile manipulators in complex and dynamic sports scenarios.
* Science Robotics DOI: 10.1126/scirobotics.adu3922
Obstacle-Avoidant Leader Following with a Quadruped Robot
Oct 01, 2024Personal mobile robotic assistants are expected to find wide applications in industry and healthcare. For example, people with limited mobility can benefit from robots helping with daily tasks, or construction workers can have robots perform precision monitoring tasks on-site. However, manually steering a robot while in motion requires significant concentration from the operator, especially in tight or crowded spaces. This reduces walking speed, and the constant need for vigilance increases fatigue and, thus, the risk of accidents. This work presents a virtual leash with which a robot can naturally follow an operator. We use a sensor fusion based on a custom-built RF transponder, RGB cameras, and a LiDAR. In addition, we customize a local avoidance planner for legged platforms, which enables us to navigate dynamic and narrow environments. We successfully validate on the ANYmal platform the robustness and performance of our entire pipeline in real-world experiments.
Whole-body end-effector pose tracking
Sep 24, 2024



Combining manipulation with the mobility of legged robots is essential for a wide range of robotic applications. However, integrating an arm with a mobile base significantly increases the system's complexity, making precise end-effector control challenging. Existing model-based approaches are often constrained by their modeling assumptions, leading to limited robustness. Meanwhile, recent Reinforcement Learning (RL) implementations restrict the arm's workspace to be in front of the robot or track only the position to obtain decent tracking accuracy. In this work, we address these limitations by introducing a whole-body RL formulation for end-effector pose tracking in a large workspace on rough, unstructured terrains. Our proposed method involves a terrain-aware sampling strategy for the robot's initial configuration and end-effector pose commands, as well as a game-based curriculum to extend the robot's operating range. We validate our approach on the ANYmal quadrupedal robot with a six DoF robotic arm. Through our experiments, we show that the learned controller achieves precise command tracking over a large workspace and adapts across varying terrains such as stairs and slopes. On deployment, it achieves a pose-tracking error of 2.64 cm and 3.64 degrees, outperforming existing competitive baselines.
Cybathlon -- Legged Mobile Assistance for Quadriplegics
May 13, 2024Assistance robots are the future for people who need daily care due to limited mobility or being wheelchair-bound. Current solutions of attaching robotic arms to motorized wheelchairs only provide limited additional mobility at the cost of increased size. We present a mouth joystick control interface, augmented with voice commands, for an independent quadrupedal assistance robot with an arm. We validate and showcase our system in the Cybathlon Challenges February 2024 Assistance Robot Race, where we solve four everyday tasks in record time, winning first place. Our system remains generic and sets the basis for a platform that could help and provide independence in the everyday lives of people in wheelchairs.